

 Technology peripheralsAITraining with 7,500 trajectory data, CMU and Meta allow the robot to reach the level of all-round living room and kitchen
Technology peripheralsAITraining with 7,500 trajectory data, CMU and Meta allow the robot to reach the level of all-round living room and kitchenTraining with 7,500 trajectory data, CMU and Meta allow the robot to reach the level of all-round living room and kitchen

Just by training using 7500 trajectory data, this robot can demonstrate 12 different operating skills in 38 tasks, not just limited to picking and pushing, but also including joint object manipulation and object repositioning . Furthermore, these skills can be applied to hundreds of different unknown situations, including unknown objects, unknown tasks, and even completely unknown kitchen environments. This kind of robot is really cool!

For decades, creating a robot capable of manipulating arbitrary objects in diverse environments has been an elusive goal. One of the reasons is the lack of diverse robotics datasets to train such agents, as well as the lack of general-purpose agents capable of generating such datasets
To overcome this problem, from The authors from Carnegie Mellon University and Meta AI spent two years developing a universal RoboAgent. Their main goal is to develop an efficient paradigm that can train a general agent capable of multiple skills with limited data and generalize these skills to various unknown situations

RoboAgent is modularly composed of:
- RoboPen - a distributed robotics infrastructure built with general-purpose hardware that enables Long term non-stop operation;
- RoboHive - a unified framework for robot learning in simulations and real-world operations;
- RoboSet - A high-quality dataset representing multiple skills using everyday objects in various scenarios;
- MT-ACT - An efficient language-conditional multi-task offline imitation learning framework , by creating diverse semantically enhanced collections based on existing robot experience, thereby expanding the offline data set, and adopting a novel policy architecture and efficient action representation method to recover good performance under limited data budgets strategy.
RoboSet: Multi-skill, multi-task, multi-modal data set
Build one that can be generalized in many different situations Robot agents first need a data set with broad coverage. Given that scaling-up efforts are often helpful (e.g., RT-1 demonstrated results on ~130,000 robot trajectories), there is a need to understand the efficiency and generalization principles of learning systems in the context of limited data sets, often low-data situations. Will lead to overfitting. Therefore, the authors' main goal is to develop a powerful paradigm that can learn generalizable general strategies in low-data situations while avoiding overfitting problems.
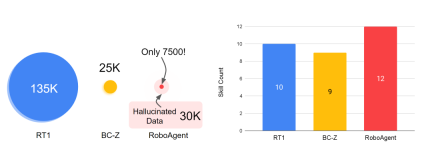
The skill and data panorama in robot learning is an important field. In robot learning, skills refer to the abilities that a robot acquires through learning and training and can be used to perform specific tasks. The development of these skills cannot be separated from the support of large amounts of data. Data is the basis for robot learning. By analyzing and processing data, robots can learn from it and improve their skills. Therefore, skills and data are two indispensable aspects of robot learning. Only by continuously learning and acquiring new data can robots continue to improve their skill levels and demonstrate higher intelligence and efficiency in various tasks
The dataset RoboSet (MT-ACT) used to train RoboAgent includes only 7,500 trajectories (18 times less than the data for RT-1). This data set is collected in advance and remains frozen. The dataset consists of high-quality trajectories collected during human teleoperation using commodity robotic hardware (Franka-Emika robot equipped with Robotiq gripper) across multiple tasks and scenarios. RoboSet (MT-ACT) sparsely covers 12 unique skills in several different contexts. Data were collected by dividing daily kitchen activities (e.g. making tea, baking) into different subtasks, each representing a unique skill. The dataset includes common pick-and-place skills, but also contact-rich skills such as wiping, lidding, and skills involving articulated objects. Rewritten content: The dataset used to train RoboAgent, RoboSet (MT-ACT), includes only 7,500 trajectories (18 times less than the data for RT-1). This data set is collected in advance and remains frozen. The dataset consists of high-quality trajectories collected during human teleoperation using commodity robotic hardware (Franka-Emika robot equipped with Robotiq gripper) across multiple tasks and scenarios. RoboSet (MT-ACT) sparsely covers 12 unique skills in several different contexts. Data were collected by dividing daily kitchen activities (e.g. making tea, baking) into different subtasks, each representing a unique skill. The dataset includes common pick-and-place skills, but also contact-rich skills such as wiping, capping, and skills involving articulated objects

## MT-ACT: Multi-task Action Chunking Transformer
RoboAgent learns a common policy in low-data situations based on two key insights. It leverages the underlying model's prior knowledge of the world to avoid mode collapse, and adopts a novel efficient representation strategy capable of ingesting highly multimodal data.
#What needs to be rewritten They are: 1. Semantic enhancement: RoboAgent injects world prior knowledge from the existing basic model into RoboSet (MT-ACT) by semantically enhancing it. The resulting dataset combines the robot's experience with prior knowledge of the world without additional human/robot costs. Use SAM to segment target objects and semantically enhance them in terms of shape, color, and texture changes. Rewritten content: 1. Semantic enhancement: RoboAgent injects world prior knowledge from the existing basic model into RoboSet (MT-ACT) by semantically enhancing it. In this way, the robot's experience and prior knowledge of the world can be combined without additional human/robot costs. Use SAM to segment target objects and perform semantic enhancement in terms of shape, color, and texture changes
2. Efficient strategy representation: The resulting dataset is severely multi-modal , containing a rich variety of skills, tasks, and scenarios. We apply the action chunking method to a multi-task setting and develop a novel and efficient policy representation—MT-ACT—that is able to acquire highly multimodal datasets with small amounts of data while avoiding overfitting. Question

Experimental results
RoboAgent’s sample efficiency is higher than existing methods
The following figure compares the MT-ACT strategy representation proposed by the author with several imitation learning architectures. The author only uses environment changes including object pose changes and partial illumination changes. Similar to previous studies, the authors attribute this to L1 generalization. From the results of RoboAgent, it is clear that using action chunking to model sub-trajectories significantly outperforms all baseline methods, thus further proving the effectiveness of the author's proposed strategy representation in sample-efficient learning
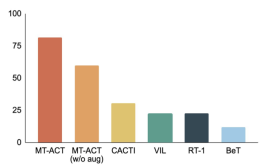
RoboAgent excels at multiple levels of abstraction
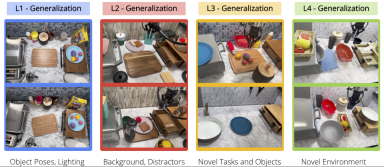
The following figure shows the author's results of testing methods at different levels of generalization. At the same time, the generalization level is also demonstrated through visualization, where L1 represents object pose changes, L2 represents diverse desktop backgrounds and interference factors, and L3 represents novel skill-object combinations. Next, the authors show how each method performs at these levels of generalization. In rigorous evaluation studies, MT-ACT performed significantly better than other methods, especially at the more difficult level of generalization (L3)
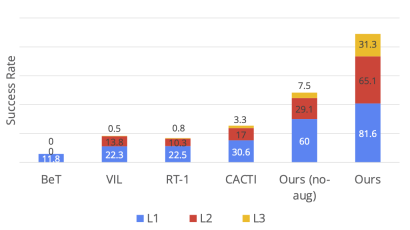
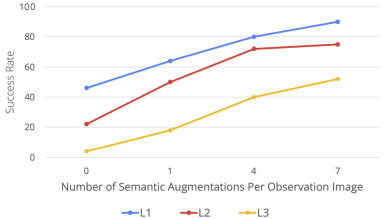
RoboAgent is highly scalable
The authors evaluated the performance of RoboAgent at increasing levels of semantic enhancement and presented it in a Five skills are assessed in the activity. As can be seen from the figure below, as the data increases (i.e. the number of enhancements per frame increases), the performance improves significantly at all levels of generalization. It is especially worth noting that in the more difficult task (L3 generalization), the performance improvement is more obvious
RoboAgent is able to demonstrate His skills in a variety of different activities


 ##
##
The above is the detailed content of Training with 7,500 trajectory data, CMU and Meta allow the robot to reach the level of all-round living room and kitchen. For more information, please follow other related articles on the PHP Chinese website!

 Tesla's Robovan Was The Hidden Gem In 2024's Robotaxi TeaserApr 22, 2025 am 11:48 AM
Tesla's Robovan Was The Hidden Gem In 2024's Robotaxi TeaserApr 22, 2025 am 11:48 AMSince 2008, I've championed the shared-ride van—initially dubbed the "robotjitney," later the "vansit"—as the future of urban transportation. I foresee these vehicles as the 21st century's next-generation transit solution, surpas
 Sam's Club Bets On AI To Eliminate Receipt Checks And Enhance RetailApr 22, 2025 am 11:29 AM
Sam's Club Bets On AI To Eliminate Receipt Checks And Enhance RetailApr 22, 2025 am 11:29 AMRevolutionizing the Checkout Experience Sam's Club's innovative "Just Go" system builds on its existing AI-powered "Scan & Go" technology, allowing members to scan purchases via the Sam's Club app during their shopping trip.
 Nvidia's AI Omniverse Expands At GTC 2025Apr 22, 2025 am 11:28 AM
Nvidia's AI Omniverse Expands At GTC 2025Apr 22, 2025 am 11:28 AMNvidia's Enhanced Predictability and New Product Lineup at GTC 2025 Nvidia, a key player in AI infrastructure, is focusing on increased predictability for its clients. This involves consistent product delivery, meeting performance expectations, and
 Exploring the Capabilities of Google's Gemma 2 ModelsApr 22, 2025 am 11:26 AM
Exploring the Capabilities of Google's Gemma 2 ModelsApr 22, 2025 am 11:26 AMGoogle's Gemma 2: A Powerful, Efficient Language Model Google's Gemma family of language models, celebrated for efficiency and performance, has expanded with the arrival of Gemma 2. This latest release comprises two models: a 27-billion parameter ver
 The Next Wave of GenAI: Perspectives with Dr. Kirk Borne - Analytics VidhyaApr 22, 2025 am 11:21 AM
The Next Wave of GenAI: Perspectives with Dr. Kirk Borne - Analytics VidhyaApr 22, 2025 am 11:21 AMThis Leading with Data episode features Dr. Kirk Borne, a leading data scientist, astrophysicist, and TEDx speaker. A renowned expert in big data, AI, and machine learning, Dr. Borne offers invaluable insights into the current state and future traje
 AI For Runners And Athletes: We're Making Excellent ProgressApr 22, 2025 am 11:12 AM
AI For Runners And Athletes: We're Making Excellent ProgressApr 22, 2025 am 11:12 AMThere were some very insightful perspectives in this speech—background information about engineering that showed us why artificial intelligence is so good at supporting people’s physical exercise. I will outline a core idea from each contributor’s perspective to demonstrate three design aspects that are an important part of our exploration of the application of artificial intelligence in sports. Edge devices and raw personal data This idea about artificial intelligence actually contains two components—one related to where we place large language models and the other is related to the differences between our human language and the language that our vital signs “express” when measured in real time. Alexander Amini knows a lot about running and tennis, but he still
 Jamie Engstrom On Technology, Talent And Transformation At CaterpillarApr 22, 2025 am 11:10 AM
Jamie Engstrom On Technology, Talent And Transformation At CaterpillarApr 22, 2025 am 11:10 AMCaterpillar's Chief Information Officer and Senior Vice President of IT, Jamie Engstrom, leads a global team of over 2,200 IT professionals across 28 countries. With 26 years at Caterpillar, including four and a half years in her current role, Engst
 New Google Photos Update Makes Any Photo Pop With Ultra HDR QualityApr 22, 2025 am 11:09 AM
New Google Photos Update Makes Any Photo Pop With Ultra HDR QualityApr 22, 2025 am 11:09 AMGoogle Photos' New Ultra HDR Tool: A Quick Guide Enhance your photos with Google Photos' new Ultra HDR tool, transforming standard images into vibrant, high-dynamic-range masterpieces. Ideal for social media, this tool boosts the impact of any photo,


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

Dreamweaver Mac version
Visual web development tools

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

