
Home >Web Front-end >JS Tutorial >Teach you step-by-step how to reverse-engineer JS to reverse font crawling and obtain information from a recruitment website
Teach you step-by-step how to reverse-engineer JS to reverse font crawling and obtain information from a recruitment website

- Python当打之年forward
- 2023-08-09 17:56:531083browse
The editor has encrypted: aHR0cHM6Ly93d3cuc2hpeGlzZW5nLmNvbS8= For security reasons, we have encoded the URL through base64, and you can get the URL through base64 decoding.
Font anti-crawling: A common anti-crawling technology, which is a combination of web pages and front-end font files. Strategy, the first ones to use font anti-crawling technology were 58.com, Autohome, etc. Now many mainstream websites or APPs also use font anti-crawling technology to add an anti-crawling measure to their own websites or APPs.
Font anti-crawling principle: Replace certain data in the page with custom fonts. When we do not use the correct decoding method, we cannot obtain the correct data content.
Use custom fonts in HTML through @font-face, as shown below:
The syntax format is:
@font-face{
font-family:"名字";
src:url('字体文件链接');
url('字体文件链接')format('文件类型')
}Font files are generally ttf type, eot type, woff type. Woff type files are widely used, so everyone usually encounters them. are all woff type files.
Take the woff type file as an example, what is its content, and what encoding method is used to make the data and code correspond one to one?
We take the font file of a recruitment website as an example, enter the Baidu font compiler and open the font file, as shown in the figure below:

Open one randomly Font, as shown in the figure below:
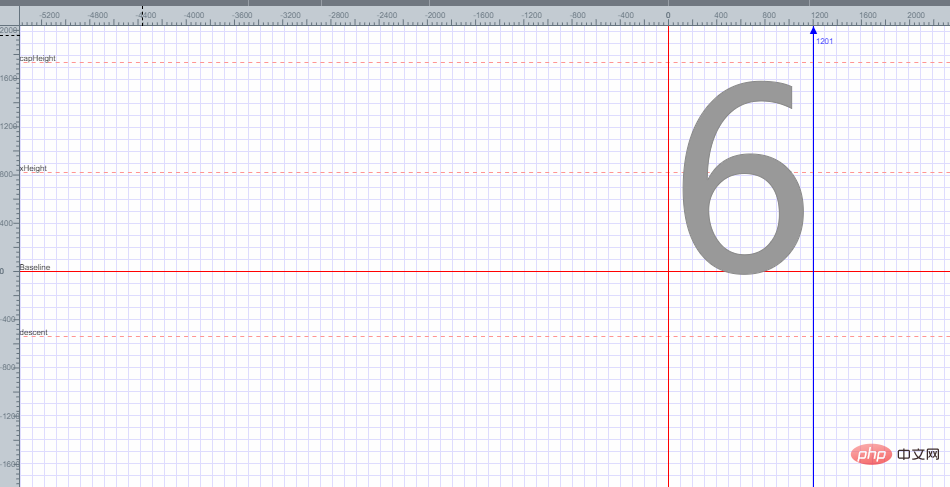
It can be found that font 6 is placed in a plane coordinate, and the encoding of font 6 is obtained based on each point of the plane coordinate. Explain how to get the encoding of font 6.
How to solve the problem of font anti-climbing?
First of all, the mapping relationship can be regarded as a dictionary. There are roughly two commonly used methods:
The first one: manually extract the corresponding relationship between a set of codes and characters and display it in the form of a dictionary. The code is as follows:
replace_dict={
'0xf7ce':'1',
'0xf324':'2',
'0xf23e':'3',
.......
'0xfe43':'n',
}
for key in replace_dict:
数据=数据.replace(key,replace_dict[key])First define a dictionary that corresponds to the font and its corresponding code, and then replace the data one by one through a for loop.
Note: This method is mainly suitable for data with few font mappings.
The second type: first download the font file of the website, then convert the font file into an XML file, find the code of the font mapping relationship inside, decode it through the decode function, and then combine the decoded code into a dictionary. Then replace the data one by one according to the dictionary content. Since the code is relatively long, I will not write the sample code here. The code of this method will be shown in the actual combat exercise later.
Okay, let’s briefly talk about font anti-crawling. Next, we will officially crawl a recruitment website.
Practical exercise
Search for custom font files
First enter a recruitment website and open the developer mode, as shown below Shown:
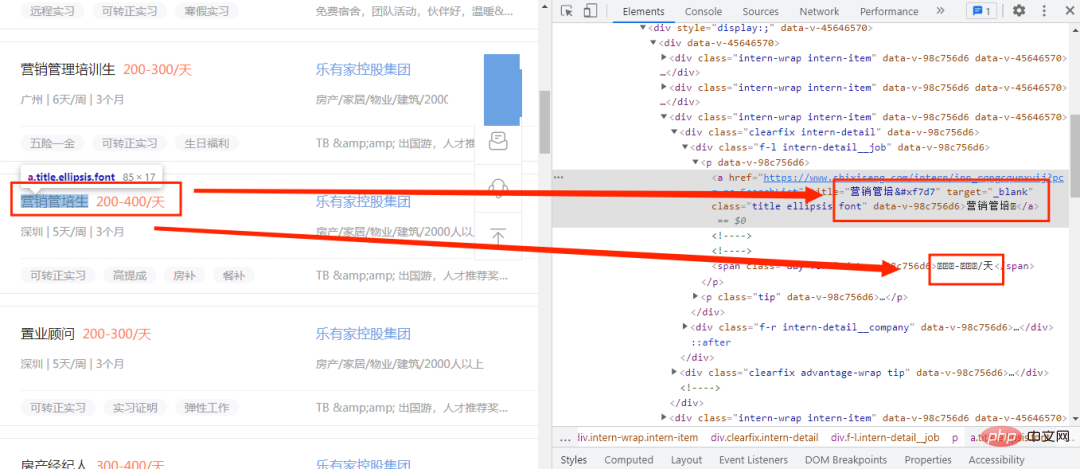
Here we see that only the new words in the code cannot function normally, but are replaced by codes. It is initially determined that a custom font file is used. At this time, we need to find the font file. , then where to find the font file? First open the developer mode and click the Network option, as shown in the following figure:
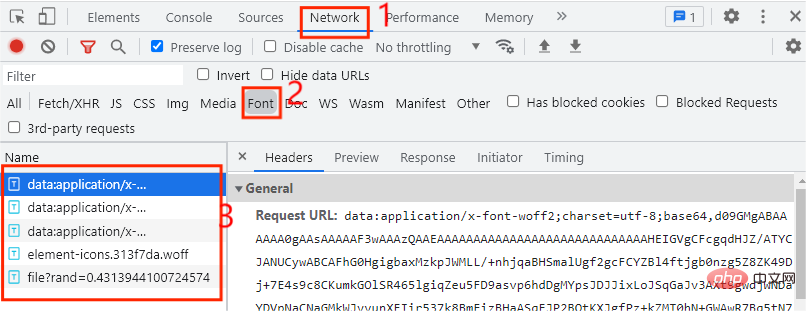
Generally, the font file is placed in Font In the tab, we found that there are a total of 5 entries here, so which one is the entry for the custom font file? Every time we click on the next page, the custom font file will be executed once. At this time we only need to click Just click on the next page in the web page, as shown in the figure below:
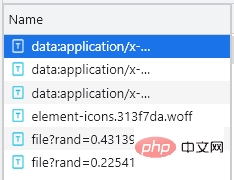
You can see an additional entry starting with file. At this time, you can initially determine that the file is a self-made one. Define the font file. Now we download it. The download method is very simple. You only need to copy the URL of the entry at the beginning of the file and open it on the web page. After downloading, open it in the Baidu font compiler, as shown in the following figure:
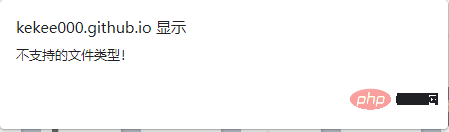
At this time, I found that I could not open it. Did I find the wrong font file? The website prompted that this file type was not supported, so we changed the suffix of the downloaded file to .woff. Open it and try, as shown in the picture below:

It will be opened successfully.
Font mapping relationship
The custom font file is found, so how do we use it? At this time, we first customize the method get_fontfile() to process the custom font file, and then display the mapping relationship in the font file through a dictionary in two steps.
Font file download and conversion; Font mapping relationship decoding.
Font file download and conversion
First of all, the custom font file update frequency is very high. At this time we The custom font file of the web page can be obtained in real time to prevent the use of previous custom font files, resulting in inaccurate data acquisition. First observe the url link of the custom font file:
https://www.xxxxxx.com/interns/iconfonts/file?rand=0.2254193167485603 https://www.xxxxxx.com/interns/iconfonts/file?rand=0.4313944100724574 https://www.xxxxxx.com/interns/iconfonts/file?rand=0.3615862774301839
可以发现自定义字体文件的URL只有rand这个参数发生变化,而且是随机的十六位小于1的浮点数,那么我们只需要构造rand参数即可,主要代码如下所示:
def get_fontfile():
rand=round(random.uniform(0,1),17)
url=f'https://www.xxxxxx.com/interns/iconfonts/file?rand={rand}'
response=requests.get(url,headers=headers).content
with open('file.woff','wb')as f:
f.write(response)
font = TTFont('file.woff')
font.saveXML('file.xml')首先通过random.uniform()方法来控制随机数的大小,再通过round()方法控制随机数的位数,这样就可以得到rand的值,再通过.content把URL响应内容转换为二进制并写入file.woff文件中,在通过TTFont()方法获取文件内容,通过saveXML方法把内容保存为xml文件。xml文件内容如下图所示:
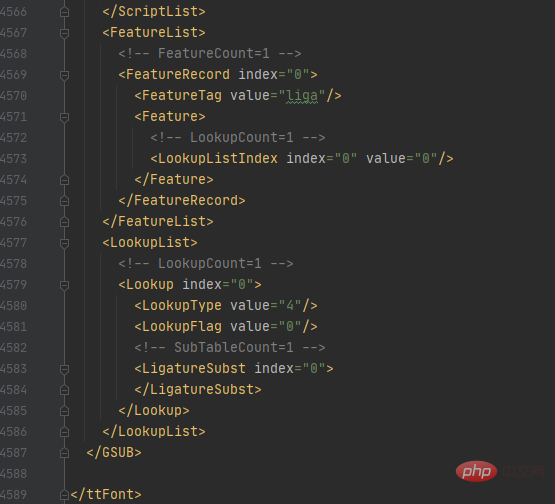
字体解码及展现
该字体.xml文件一共有4589行那么多,哪个部分才是字体映射关系的代码部分呢?
首先我们看回在百度字体编码器的内容,如下图所示:

汉字人对应的代码为f0e2,那么我们就在字体.xml文件中查询人的代码,如下图所示:
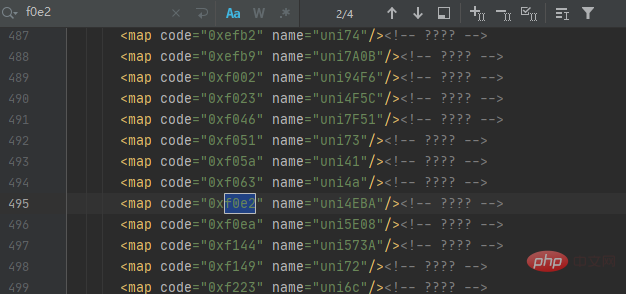
可以发现一共有4个结果,但仔细观察每个结果都相同,这时我们可以根据它们代码规律来获取映射关系,再通过解码来获取对应的数据值,最后以字典的形式展示,主要代码如下所示:
with open('file.xml') as f:
xml = f.read()
keys = re.findall('<map code="(0x.*?)" name="uni.*?"/>', xml)
values = re.findall('<map code="0x.*?" name="uni(.*?)"/>', xml)
for i in range(len(values)):
if len(values[i]) < 4:
values[i] = ('\\u00' + values[i]).encode('utf-8').decode('unicode_escape')
else:
values[i] = ('\\u' + values[i]).encode('utf-8').decode('unicode_escape')
word_dict = dict(zip(keys, values))首先读取file.xml文件内容,找出把代码中的code、name的值并分别设置为keys键,values值,再通过for循环把values的值解码为我们想要的数据,最后通过zip()方法合并为一个元组并通过dict()方法转换为字典数据,运行结果如图所示:

获取招聘数据
在上一步中,我们成功把字体映射关系转换为字典数据了,接下来开始发出网络请求来获取数据,主要代码如下所示:
def get_data(dict,url):
response=requests.get(url,headers=headers).text.replace('&#','0')
for key in dict:
response=response.replace(key,dict[key])
XPATH=parsel.Selector(response)
datas=XPATH.xpath('//*[@id="__layout"]/div/div[2]/div[2]/div[1]/div[1]/div[1]/div')
for i in datas:
data={
'workname':i.xpath('./div[1]/div[1]/p[1]/a/text()').extract_first(),
'link':i.xpath('./div[1]/div[1]/p[1]/a/@href').extract_first(),
'salary':i.xpath('./div[1]/div[1]/p[1]/span/text()').extract_first(),
'place':i.xpath('./div[1]/div[1]/p[2]/span[1]/text()').extract_first(),
'work_time':i.xpath('./div[1]/div[1]/p[2]/span[3]/text()').extract_first()+i.xpath('./div[1]/div[1]/p[2]/span[5]/text()').extract_first(),
'company_name':i.xpath('./div[1]/div[2]/p[1]/a/text()').extract_first(),
'Field_scale':i.xpath('./div[1]/div[2]/p[2]/span[1]/text()').extract_first()+i.xpath('./div[1]/div[2]/p[2]/span[3]/text()').extract_first(),
'advantage': ','.join(i.xpath('./div[2]/div[1]/span/text()').extract()),
'welfare':','.join(i.xpath('./div[2]/div[2]/span/text()').extract())
}
saving_data(list(data.values()))首先自定义方法get_data()并接收字体映射关系的字典数据,再通过for循环将字典内容与数据一一替换,最后通过xpath()来提取我们想要的数据,最后把数据传入我们自定义方法saving_data()中。
保存数据
数据已经获取下来了,接下来将保存数据,主要代码如下所示:
def saving_data(data):
db = pymysql.connect(host=host, user=user, password=passwd, port=port, db='recruit')
cursor = db.cursor()
sql = 'insert into recruit_data(work_name, link, salary, place, work_time,company_name,Field_scale,advantage,welfare) values(%s,%s,%s,%s,%s,%s,%s,%s,%s)'
try:
cursor.execute(sql,data)
db.commit()
except:
db.rollback()
db.close()启动程序
好了,程序已经写得差不多了,接下来将编写代码运行程序,主要代码如下所示:
if __name__ == '__main__':
create_db()
get_fontfile()
for i in range(1,3):
url=f'https://www.xxxxxx.com/interns?page={i}&type=intern&salary=-0&city=%E5%85%A8%E5%9B%BD'
get_data(get_dict(),url)结果展示
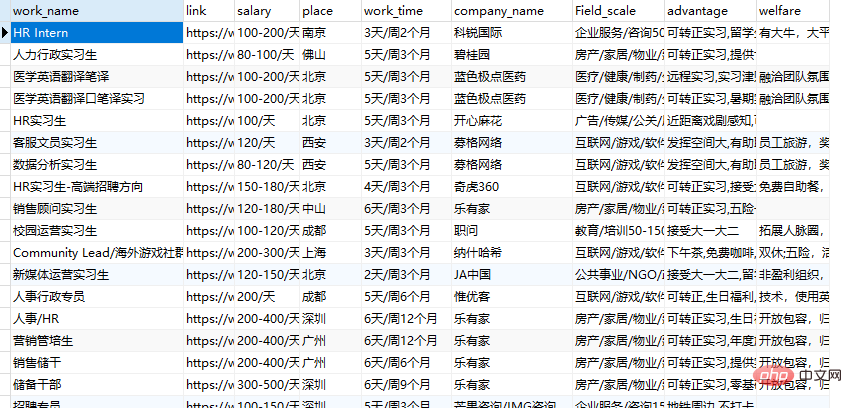
The above is the detailed content of Teach you step-by-step how to reverse-engineer JS to reverse font crawling and obtain information from a recruitment website. For more information, please follow other related articles on the PHP Chinese website!