Today I will share a batch of original creations by Xiao Ming students, using Python to explore the world written by Jin Yong!
Take you to read novels in python for entertainment and learning.
The knowledge points involved are:
##Crawling ideas for conventional novel websites
Basic pandas data sorting
##lxml Application skills with xpath
Regular pattern matching
Counter word frequency statistics
pyecharts data visualization
stylecloud word cloud chart
##Usage of gensim.models.Word2Vec
scipy.cluster.hierarchy Hierarchical clustering##This article starts from traditional matching Logical analysis transitions to machine learning word vectors, and all-round text analysis is worth learning. It is full of useful information.
Collection of Jin Yong's novels
There used to be many websites for Jin Yong's novels, but most of them are no longer accessible. However, due to the existence of many Jin Yong fans, new websites are constantly appearing. I recently found a website of Jin Yong’s novel that is still accessible through Baidu: aHR0cDovL2ppbnlvbmcxMjMuY29tLw==
But I have already prepared the collected data. , you can download the data directly and skip the content of this chapter.
Data source download address: https://gitcode.net/as604049322/blog_data
For each novel Creation date
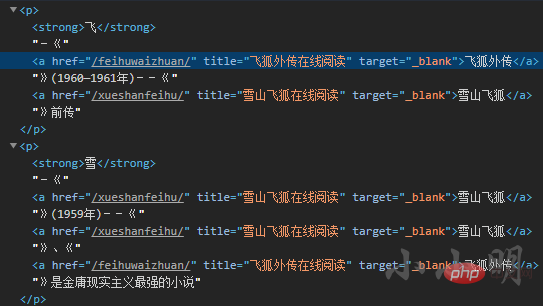
The following first obtains the names, creation years and corresponding links of these 15 works. From the developer tools, you can see that there are many a tags in each line. The characteristic of the node we need is that the subsequent adjacent node is followed by a string of creation date:
Then we You can traverse all a tags and determine whether the content of the next adjacent node conforms to the date format. The final complete download code is:
import requests
from lxml import etree
import pandas as pd
import re
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
"Accept-Language": "zh-CN,zh;q=0.9"
}
res = requests.get(base_url, headers=headers)
res.encoding = res.apparent_encoding
html = etree.HTML(res.text)
a_tags = html.xpath("//div[@class='jianjie']/p/a")
data = []
for a_tag in a_tags:
m_obj = re.search("\((\d{4}(?:—\d{4})?年)\)", a_tag.tail)
if m_obj:
data.append((a_tag.text, m_obj.group(1), a_tag.attrib["href"]))
data = pd.DataFrame(data, columns=["名称", "创作时间", "网址"])
You can view it sorted by creation date :
data.sort_values("创作时间", ignore_index=True, inplace=True)
data
名称
创作时间
网址
书剑恩仇录
1955年
/shujianenchoulu/
碧血剑
1956年
/bixuejian/
射雕英雄传
1957—1959年
/shediaoyingxiongzhuan/
神雕侠侣
1959—1961年
/shendiaoxialv/
Snow Mountain Flying Fox
1959
/xueshanfeihu/
##Flying Fox Gaiden
1960-1961
##/feihuwaizhuan/
白马肖西风
1961
/baimaxiaoxifeng/
Yitian Tulong Ji
1961
/yitiantulongji/
元鸯刀
1961
/yuanyangdao/
天龙八部
##1963-1966
/tianlongbabu/
lianchengjue
1963
/lianchengjue/
Xia Kexing
1965
/xiakexing/
##xiaiaoaojianghu
1967
/xiaoaojianghu/
The Deer and the Cauldron
##1969-1972
/ludingji/
##元女剑
1970
/yuenvjian/
章节页下载与顺序校正
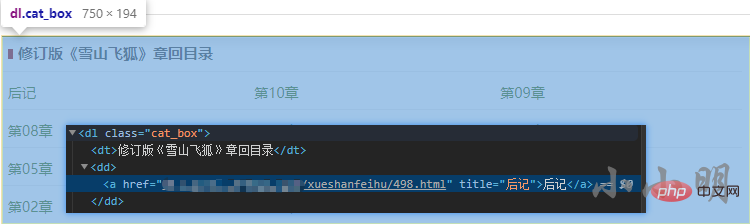
下面看看章节页节点的分布情况,以《雪山飞狐》为例:
同时可以看到部分小说的节点出现了倒序的情况,我们需要在识别出倒序时将其正序,完整代码:
from urllib.parse import urljoin
def getTitleAndUrl(url):
url = urljoin(base_url, url)
data = []
res = requests.get(url, headers=headers)
res.encoding = res.apparent_encoding
html = etree.HTML(res.text)
reverse, last_num = False, None
for i, a_tag in enumerate(html.xpath("//dl[@class='cat_box']/dd/a")):
data.append([re.sub("\s+", " ", a_tag.text), a_tag.attrib["href"]])
nums = re.findall("第(\d+)章", a_tag.text)
if nums:
if last_num and int(nums[0]) < last_num:
reverse = True
last_num = int(nums[0])
# 顺序校正并删除后记之后的内容
if reverse:
data.reverse()
return data
def load_novel(novel):
with open(f'novels/{novel}.txt', encoding="u8") as f:
return f.read()
主角分析
首先我们加载人物数据:
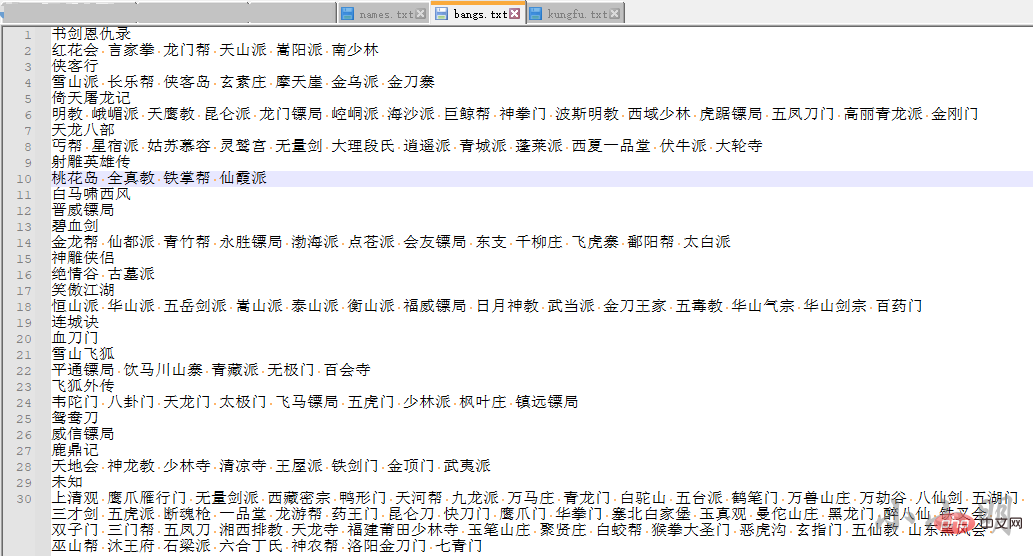
with open('data/names.txt',encoding="utf-8") as f:
data = [line.rstrip() for line in f]
novels = data[::2]
names = data[1::2]
novel_names = {k: v.split() for k, v in zip(novels, names)}
del novels, names, data
from collections import Counter
def find_main_charecters(novel, num=10, content=None):
if content is None:
content = load_novel(novel)
count = Counter()
for name in novel_names[novel]:
count[name] = content.count(name)
return count.most_common(num)
for novel in novel_names:
print(novel, dict(find_main_charecters(novel, 10)))
with open('data/kungfu.txt', encoding="utf-8") as f:
data = [line.rstrip() for line in f]
novels = data[::2]
kungfus = data[1::2]
novel_kungfus = {k: v.split() for k, v in zip(novels, kungfus)}
del novels, kungfus, data
定义计数方法:
def find_main_kungfus(novel, num=10, content=None):
if content is None:
content = load_novel(novel)
count = Counter()
for name in novel_kungfus[novel]:
count[name] = content.count(name)
return count.most_common(num)
for novel in novel_kungfus:
print(novel, dict(find_main_kungfus(novel, 10)))
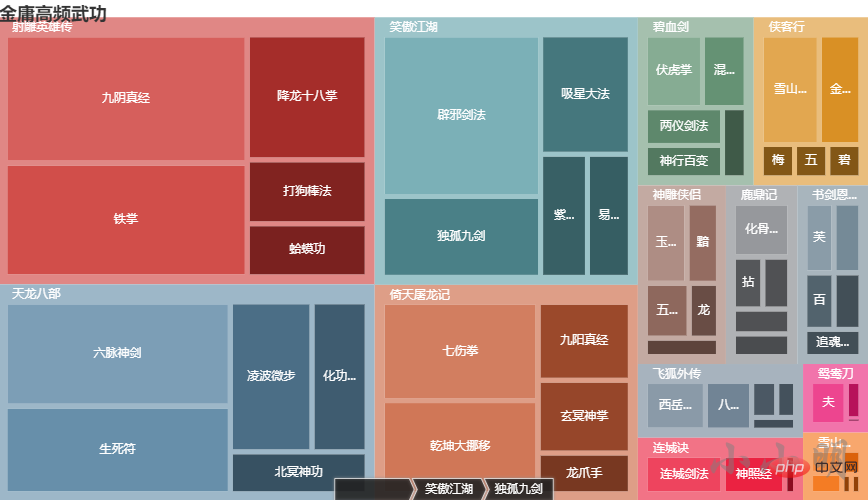
from pyecharts import options as opts
from pyecharts.charts import Tree
data = []
for novel in novel_kungfus:
tmp = []
data.append({"name": novel, "children": tmp})
for name, count in find_main_kungfus(novel, 5):
tmp.append({"name": name, "value": count})
c = (
TreeMap()
.add("", data, levels=[
opts.TreeMapLevelsOpts(),
opts.TreeMapLevelsOpts(
color_saturation=[0.3, 0.6],
treemap_itemstyle_opts=opts.TreeMapItemStyleOpts(
border_color_saturation=0.7, gap_width=5, border_width=10
),
upper_label_opts=opts.LabelOpts(
is_show=True, position='insideTopLeft', vertical_align='top'
)
),
])
.set_global_opts(title_opts=opts.TitleOpts(title="金庸高频武功"))
)
c.render_notebook()
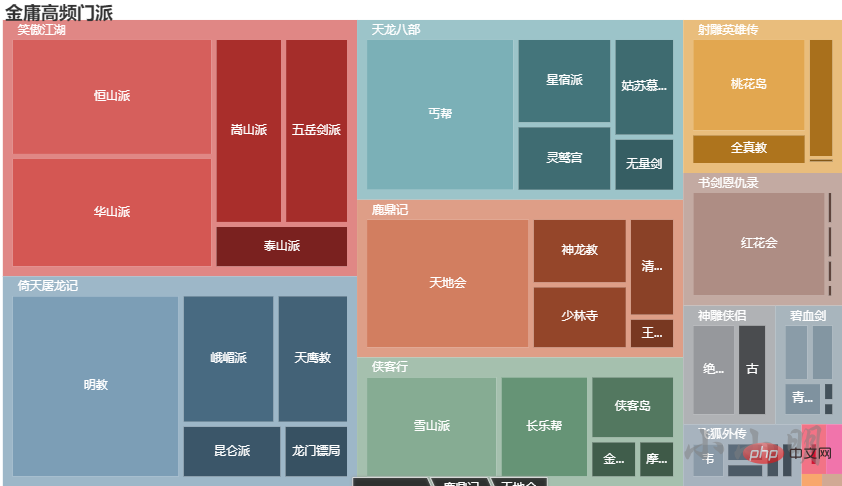
门派分析
加载数据并获取每部小说前10的门派:
with open('data/bangs.txt', encoding="utf-8") as f:
data = [line.rstrip() for line in f]
novels = data[::2]
bangs = data[1::2]
novel_bangs = {k: v.split() for k, v in zip(novels, bangs) if k != "未知"}
del novels, bangs, data
def find_main_bangs(novel, num=10, content=None):
if content is None:
content = load_novel(novel)
count = Counter()
for name in novel_bangs[novel]:
count[name] = content.count(name)
return count.most_common(num)
for novel in novel_bangs:
print(novel, dict(find_main_bangs(novel, 10)))
from pyecharts import options as opts
from pyecharts.charts import Tree
data = []
for novel in novel_bangs:
tmp = []
data.append({"name": novel, "children": tmp})
for name, count in find_main_bangs(novel, 5):
tmp.append({"name": name, "value": count})
c = (
TreeMap()
.add("", data, levels=[
opts.TreeMapLevelsOpts(),
opts.TreeMapLevelsOpts(
color_saturation=[0.3, 0.6],
treemap_itemstyle_opts=opts.TreeMapItemStyleOpts(
border_color_saturation=0.7, gap_width=5, border_width=10
),
upper_label_opts=opts.LabelOpts(
is_show=True, position='insideTopLeft', vertical_align='top'
)
),
])
.set_global_opts(title_opts=opts.TitleOpts(title="金庸高频门派"))
)
c.render_notebook()
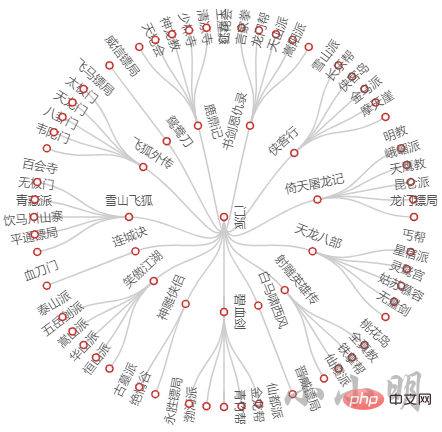
还可以测试一下树形图:
from pyecharts.charts import Tree
c = (
Tree()
.add("", [{"name": "门派", "children": data}], layout="radial")
)
c.render_notebook()
综合统计
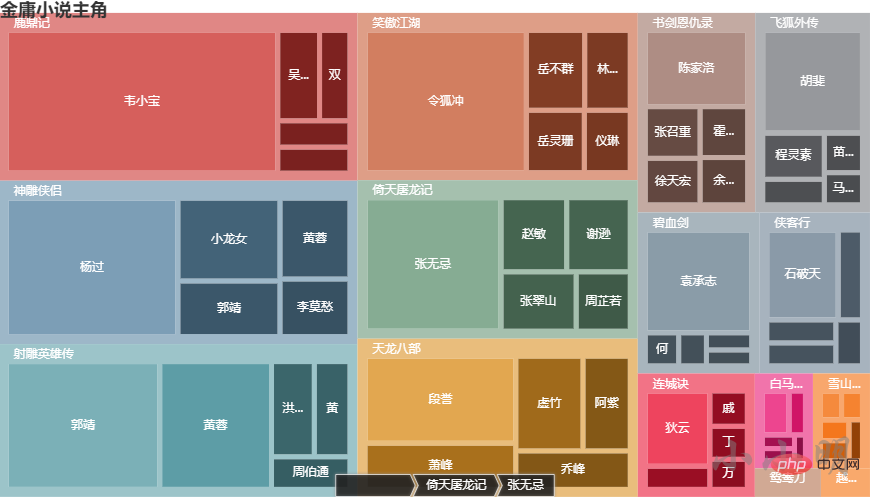
下面我们编写一个函数,输入一部小说名,可以输出其最高频的主角、武功和门派:
from pyecharts import options as opts
from pyecharts.charts import Bar
def show_top10(novel):
content = load_novel(novel)
charecters = find_main_charecters(novel, 10, content)[::-1]
k, v = map(list, zip(*charecters))
c = (
Bar(init_opts=opts.InitOpts("720px", "320px"))
.add_xaxis(k)
.add_yaxis("", v)
.reversal_axis()
.set_series_opts(label_opts=opts.LabelOpts(position="right"))
.set_global_opts(title_opts=opts.TitleOpts(title=f"{novel}主角"))
)
display(c.render_notebook())
kungfus = find_main_kungfus(novel, 10, content)[::-1]
k, v = map(list, zip(*kungfus))
c = (
Bar(init_opts=opts.InitOpts("720px", "320px"))
.add_xaxis(k)
.add_yaxis("", v)
.reversal_axis()
.set_series_opts(label_opts=opts.LabelOpts(position="right"))
.set_global_opts(title_opts=opts.TitleOpts(title=f"{novel}功夫"))
)
display(c.render_notebook())
bangs = find_main_bangs(novel, 10, content)[::-1]
k, v = map(list, zip(*bangs))
c = (
Bar(init_opts=opts.InitOpts("720px", "320px"))
.add_xaxis(k)
.add_yaxis("", v)
.reversal_axis()
.set_series_opts(label_opts=opts.LabelOpts(position="right"))
.set_global_opts(title_opts=opts.TitleOpts(title=f"{novel}门派"))
)
display(c.render_notebook())
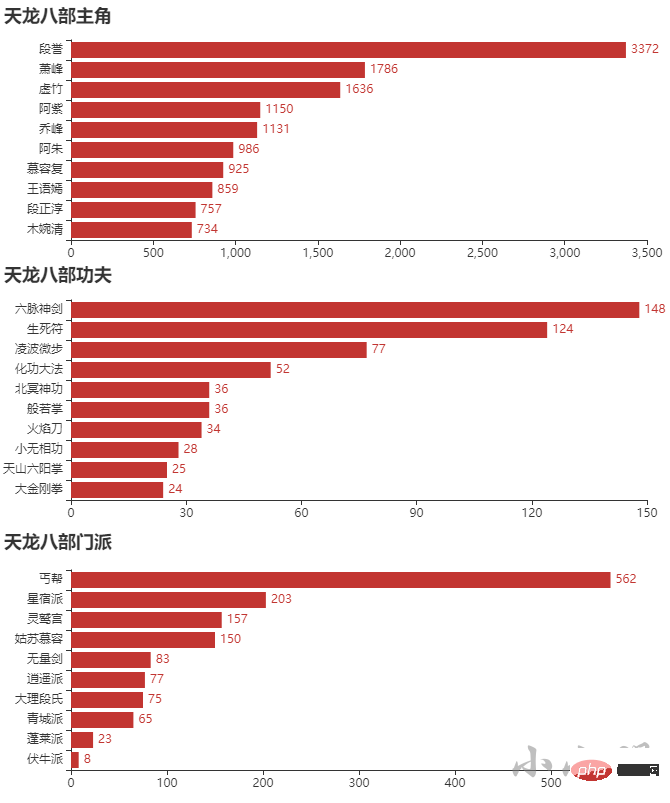
例如查看天龙八部:
show_top10("天龙八部")
词云图分析
可以先添加所有的人物、武功和门派作为自定义词汇:
import jieba
for novel, names in novel_names.items():
for name in names:
jieba.add_word(name)
for novel, kungfus in novel_kungfus.items():
for kungfu in kungfus:
jieba.add_word(kungfu)
for novel, bangs in novel_bangs.items():
for bang in bangs:
jieba.add_word(bang)
文章整体词云查看
这里我们仅提取词长度不小于4的成语、俗语和短语进行分析,以天龙八部这部小说为例:
from IPython.display import Image
import stylecloud
import jieba
import re
# 去除非中文字符
text = re.sub("[^一-龟]+", " ", load_novel("天龙八部"))
words = [word for word in jieba.cut(text) if len(word) >= 4]
stylecloud.gen_stylecloud(" ".join(words),
collocations=False,
font_path=r'C:\Windows\Fonts\msyhbd.ttc',
icon_name='fas fa-square',
output_name='tmp.png')
Image(filename='tmp.png')
data = []
for line in load_novel("神雕侠侣").splitlines():
if "杨过" in line and "小龙女" in line:
line = re.sub("[^一-龟]+", " ", line)
data.extend(word for word in jieba.cut(line) if len(word) >= 4)
stylecloud.gen_stylecloud(" ".join(data),
collocations=False,
font_path=r'C:\Windows\Fonts\msyhbd.ttc',
icon_name='fas fa-square',
output_name='tmp.png')
Image(filename='tmp.png')
这里的每一个词都能联想到发生在杨过和小龙女背后的一个故事。
同样的思路看看郭靖和黄蓉:
data = []
for line in load_novel("射雕英雄传").splitlines():
if "郭靖" in line and "黄蓉" in line:
line = re.sub("[^一-龟]+", " ", line)
data.extend(word for word in jieba.cut(line) if len(word) >= 4)
stylecloud.gen_stylecloud(" ".join(data),
collocations=False,
font_path=r'C:\Windows\Fonts\msyhbd.ttc',
icon_name='fas fa-square',
output_name='tmp.png')
Image(filename='tmp.png')
最后我们看看天龙八部的三兄弟相关的词云:
data = []
for line in load_novel("天龙八部").splitlines():
if ("萧峰" in line or "乔峰" in line) and "段誉" in line and "虚竹" in line:
line = re.sub("[^一-龟]+", " ", line)
data.extend(word for word in jieba.cut(line) if len(word) >= 4)
stylecloud.gen_stylecloud(" ".join(data),
collocations=False,
font_path=r'C:\Windows\Fonts\msyhbd.ttc',
icon_name='fas fa-square',
output_name='tmp.png')
Image(filename='tmp.png')
from pyecharts import options as opts
from pyecharts.charts import Graph
import math
import itertools
count = Counter()
for novel in novel_names:
names = novel_names[novel]
re_rule = f"({'|'.join(names)})"
for line in load_novel(novel).splitlines():
names = list(set(re.findall(re_rule, line)))
if names and len(names) >= 2:
names.sort()
for s, t in itertools.combinations(names, 2):
count[(s, t)] += 1
count = count.most_common(200)
node_count, nodes, links = Counter(), [], []
for (n1, n2), v in count:
node_count[n1] += 1
node_count[n2] += 1
links.append({"source": n1, "target": n2})
for node, count in node_count.items():
nodes.append({"name": node, "symbolSize": int(math.log(count)*5)+5})
c = (
Graph(init_opts=opts.InitOpts("1280px","960px"))
.add("", nodes, links, repulsion=30)
)
c.render("tmp.html")
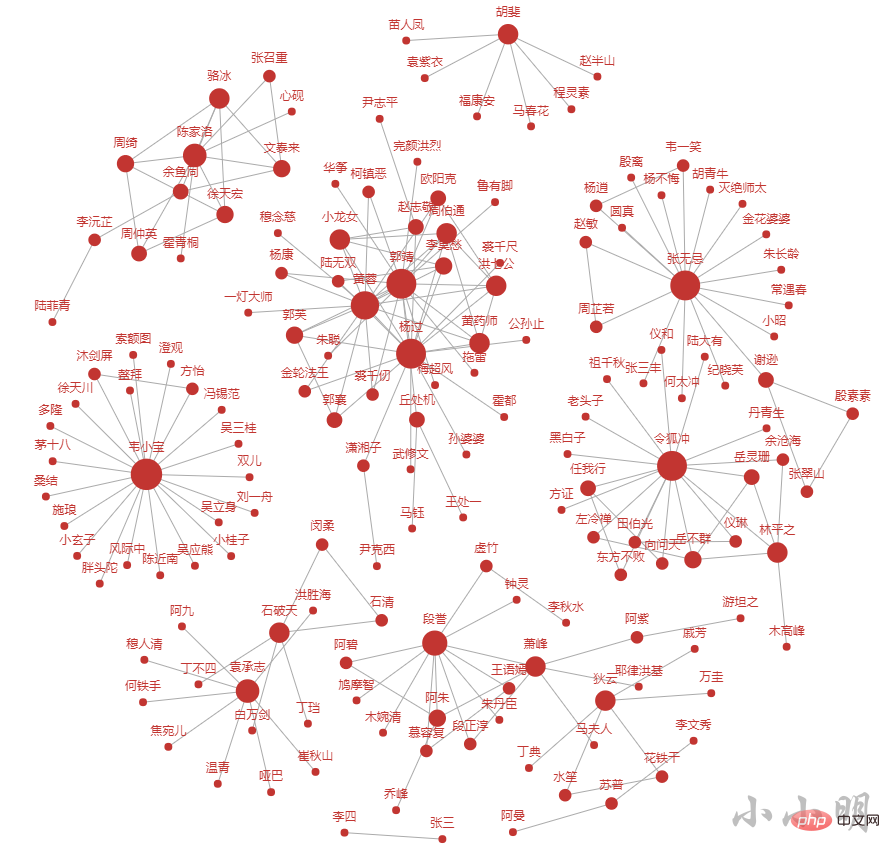
这次我们生成了HTML文件是为了更方便的查看结果,前200个人物的关系情况如下:
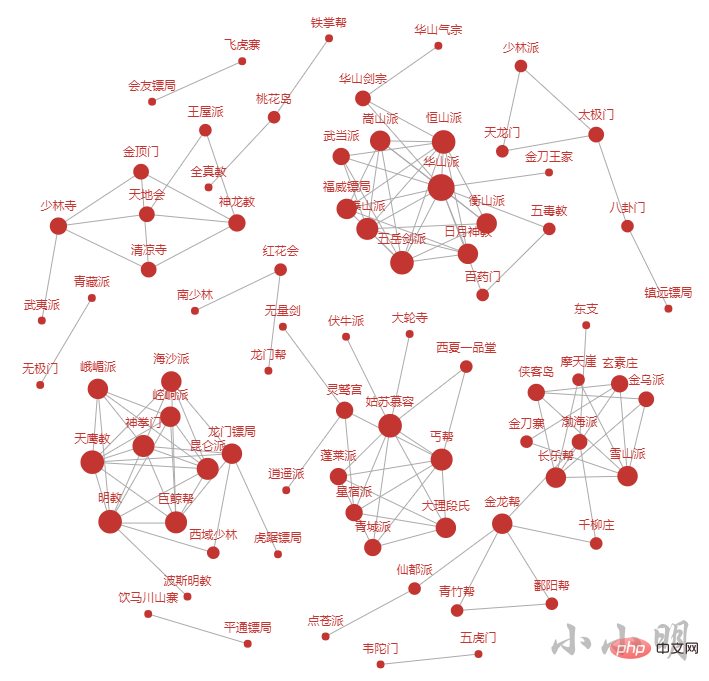
门派关系分析
按照相同的方法分析所有小说的门派关系:
from pyecharts import options as opts
from pyecharts.charts import Graph
import math
import itertools
count = Counter()
for novel in novel_bangs:
bangs = novel_bangs[novel]
re_rule = f"({'|'.join(bangs)})"
for line in load_novel(novel).splitlines():
names = list(set(re.findall(re_rule, line)))
if names and len(names) >= 2:
names.sort()
for s, t in itertools.combinations(names, 2):
count[(s, t)] += 1
count = count.most_common(200)
node_count, nodes, links = Counter(), [], []
for (n1, n2), v in count:
node_count[n1] += 1
node_count[n2] += 1
links.append({"source": n1, "target": n2})
for node, count in node_count.items():
nodes.append({"name": node, "symbolSize": int(math.log(count)*5)+5})
c = (
Graph(init_opts=opts.InitOpts("1280px","960px"))
.add("", nodes, links, repulsion=50)
)
c.render("tmp2.html")
Word2Vec分析
Word2Vec 是一款将词表征为实数值向量的高效工具,接下来,我们将使用它来处理这些小说。
gensim 包提供了一个 Python 版的实现。
源代码地址:https://github.com/RaRe-Technologies/gensim
官方文档地址:http://radimrehurek.com/gensim/
之前我有使用gensim 包进行了相似文本的匹配,有兴趣可查阅:《批量模糊匹配的三种方法》
Word2Vec训练模型
首先我要将所有小说的段落分词后添加到组织到一起(前面的程序可以重启):
import jieba
def load_novel(novel):
with open(f'novels/{novel}.txt', encoding="u8") as f:
return f.read()
with open('data/names.txt', encoding="utf-8") as f:
data = f.read().splitlines()
novels = data[::2]
names = []
for line in data[1::2]:
names.extend(line.split())
with open('data/kungfu.txt', encoding="utf-8") as f:
data = f.read().splitlines()
kungfus = []
for line in data[1::2]:
kungfus.extend(line.split())
with open('data/bangs.txt', encoding="utf-8") as f:
data = f.read().splitlines()
bangs = []
for line in data[1::2]:
bangs.extend(line.split())
for name in names:
jieba.add_word(name)
for kungfu in kungfus:
jieba.add_word(kungfu)
for bang in bangs:
jieba.add_word(bang)
# 去重
names = list(set(names))
kungfus = list(set(kungfus))
bangs = list(set(bangs))
sentences = []
for novel in novels:
print(f"处理:{novel}")
for line in load_novel(novel).splitlines():
sentences.append(jieba.lcut(line))
all_names = []
word_vectors = []
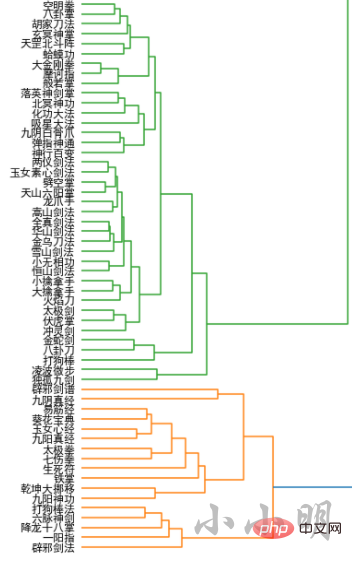
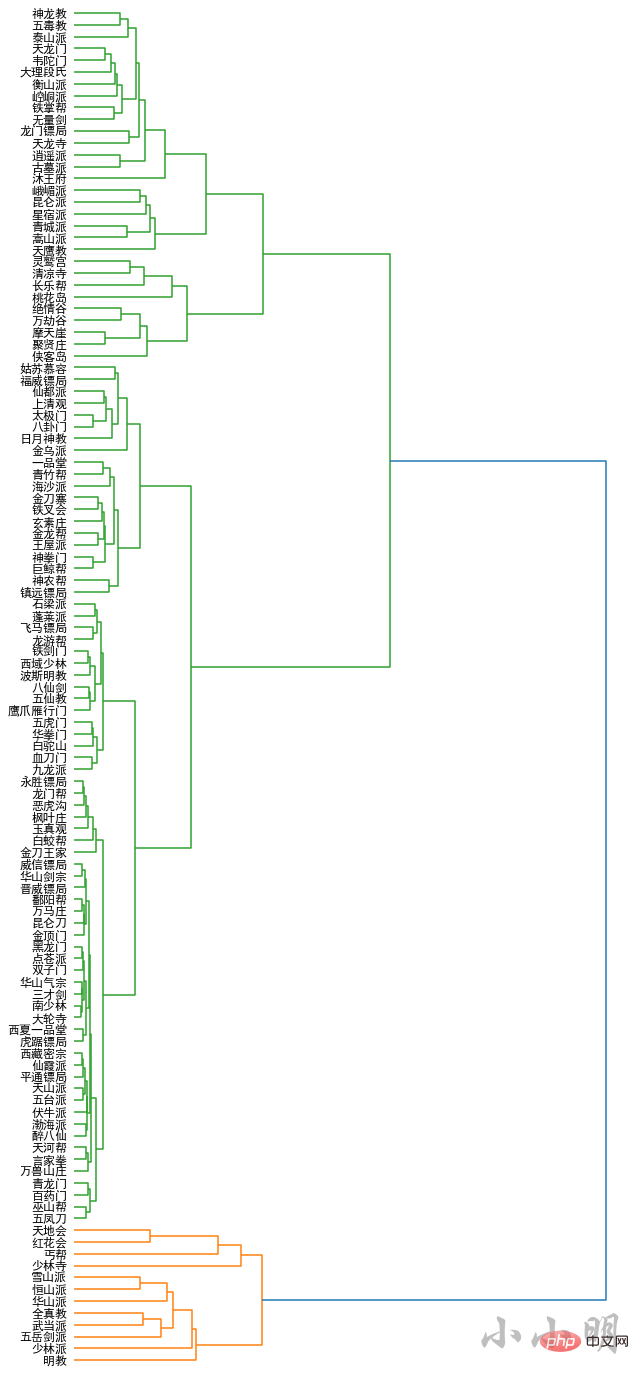
for name in names:
if name in model.wv:
all_names.append(name)
word_vectors.append(model.wv[name])
all_names = np.array(all_names)
word_vectors = np.vstack(word_vectors)
The above is the detailed content of Advanced | 20,000 words using Python to explore the world of Jin Yong's novels. For more information, please follow other related articles on the PHP Chinese website!