
 Operation and MaintenanceLinux Operation and MaintenanceUltra-Comprehensive Collection - Summary Collection of Linux Performance Analysis Tools
Operation and MaintenanceLinux Operation and MaintenanceUltra-Comprehensive Collection - Summary Collection of Linux Performance Analysis ToolsUltra-Comprehensive Collection - Summary Collection of Linux Performance Analysis Tools
Out of interest in the Linux operating system and a strong desire for underlying knowledge, I organized This article. This article can also be used as an indicator to test basic knowledge. In addition, the article covers all aspects of a system. Without complete computer system knowledge, network knowledge and operating system knowledge, it is impossible to fully master the tools in the document. In addition, system performance analysis and optimization is a long-term series.
This document is mainly based on Linux expert Brendan Gregg, Netflix senior performance architect’s blog post updating Linux performance tuning tools to collect Linux system performance This is a comprehensive article compiled from optimization-related articles. It mainly explains the principles and performance testing tools involved in combination with blog posts.
Background knowledge: Having background knowledge is what you need to know when analyzing performance problems. For example, hardware cache; another example is the operating system kernel. The behavioral details of the application are often intertwined with these things. These low-level things can affect the performance of the application in unexpected ways. For example, some programs cannot fully utilize the cache, resulting in performance degradation. For example, too many system calls are called unnecessarily, causing frequent kernel/user switching, etc. This is just to pave the way for the follow-up content of this article. There are still many things about tuning. I don’t know much more than I know. I hope everyone can learn and make progress together.
【Performance Analysis Tool】
First look at a picture:

The above picture is a performance analysis shared by Brendan Gregg. Everything in it You can get its help documentation through man. The following is a brief introduction to the general usage:
▲ vmstat--virtual memory statistics
vmstat (VirtualMeomoryStatistics, virtual memory statistics) is a common tool for monitoring memory in Linux. It can monitor the overall situation of the operating system's virtual memory, process, CPU, etc.
General usage of vmstat: vmstat interval times means sampling once every interval seconds, for a total of times times. If times is omitted, then Data is collected until manually stopped by the user.
A simple example:

##You can use ctrl c to stop vmstat collecting data.
The first row shows the average since the system was started, the second row starts showing what is happening now, the following rows will show what is happening in each 5 second interval, the meaning of each column is at the beginning part, as follows:
▪ procs: The r column shows how many processes are waiting for the cpu, and the b column shows how many processes are sleeping uninterruptibly (waiting for IO).
▪ memory: The swapd column shows how many blocks have been swapped out of the disk (page swapping), and the remaining columns show how many blocks are free (unused). being used), how many blocks are being used as buffers, and how many are being used as the operating system's cache.
▪ swap: Shows swap activity: how many blocks are being swapped in (from disk) and swapped out (to disk) per second.
▪ io: Shows how many blocks were read (bi) and written (bo) from the block device, usually reflecting hard disk I/O.
▪ system: Displays the number of interrupts (in) and context switches (cs) per second.
▪ cpu: Displays the percentage of all CPU time spent on various operations, including executing user code (non-kernel), executing system code (kernel), idle, and waiting for IO.
Symptoms of insufficient memory: free memory decreases sharply, recycling buffers and caches does not help, extensive use of swap partitions (swpd), frequent page exchanges (swap), the number of read and write disks (io ) increases, page fault interrupts (in) increase, the number of context switches (cs) increases, the number of processes waiting for IO (b) increases, and a lot of CPU time is spent waiting for IO (wa)
▲iostat--used to report central processing unit statistics
iostat is used to report central processing unit (CPU) statistics and the entire system, adapter, tty device , disk and CD-ROM input/output statistics. By default, the same cpu usage information as vmstat is displayed. Use the following command to display extended device statistics:

The first line shows the average since system startup, then the incremental averages are shown, one line per device.
Common Linux disk IO indicator abbreviation habits: rq is request, r is read, w is write, qu is queue, sz is size, a is verage, tm is time, svc is service.
▪rrqm/s and wrqm/s: merged read and write requests per second, "merged" means that the operating system takes out multiple logical requests from the queue and merges them into one Request to actual disk.
▪r/s and w/s: Number of read and write requests sent to the device per second.
▪rsec/s and wsec/s: Number of sectors read and written per second.
▪avgrq –sz: Requested number of sectors.
▪avgqu –sz: The number of requests waiting in the device queue.
▪await: The time spent on each IO request.
▪svctm: Actual request (service) time.
▪%util: The percentage of time that there was at least one active request.
▲dstat--system monitoring tool
dstat shows cpu usage and disk io status , the network packet sending situation and page change situation, the output is colorful and highly readable. Compared with the input of vmstat and iostat, it is more detailed and intuitive. When using it, just enter the command directly, and of course you can also use specific parameters.
is as follows: dstat –cdlmnpsy

##▲iotop- -LINUX process real-time monitoring tool
The iotop command is a command specifically designed to display hard disk IO. The interface style is similar to the top command and can display which process specifically generates the IO load. It is a top tool used to monitor disk I/O usage. It has a UI similar to top, including PID, user, I/O, process and other related information.
Can be used in a non-interactive manner: iotop –bod interval, to view the I/O of each process, you can use pidstat, pidstat –d instat.
Search the public account Linux Chinese community backend and reply "private kitchen" to get a surprise gift package.
▲pidstat--monitoring system resources
pidstat is mainly used to monitor all or specified processes Occupying system resources, such as CPU, memory, device IO, task switching, threads, etc.
Usage: pidstat –d interval; pidstat can also be used to count CPU usage information: pidstat –u interval; to count memory information: Pidstat –r interval.
##▲top
top command The summary area displays five aspects of system performance information:
1. Load: time, number of logged-in users, average system load;
2. Process: running, sleeping, stopping, zombie;
3.cpu: user mode, core mode, NICE, idle, waiting for IO, interrupt, etc.;
4. Memory: total, used, idle ( System perspective), buffering, caching;
5. Swap partition: total, used, free
The task area default display: process ID, effective user, process priority, NICE value, virtual memory, physical memory and shared memory used by the process, process status, CPU usage, memory usage, accumulated CPU time, process command line information.
##▲htop
htop is Linux An interactive process viewer on the system, a text-mode application (in the console or X terminal), requires ncurses. 
Htop allows users to operate interactively, supports color themes, can scroll through the process list horizontally or vertically, and supports mouse operations.
Compared with top, htop has the following advantages:
▪ You can scroll through the process list horizontally or vertically to see all processes and the complete command line.
▪ Faster than top at startup.
▪ You do not need to enter the process ID when killing a process.
▪ htop supports mouse operations.
▲mpstat
mpstat is the abbreviation of Multiprocessor Statistics and is a real-time system monitoring tool. It reports some statistical information about the CPU, which is stored in the /proc/stat file. In a multi-CPUs system, it can not only view the average status information of all CPUs, but also view the information of a specific CPU. Common usage: mpstat –P ALL interval times.
##▲netstat
Netstat is used for Displays statistical data related to IP, TCP, UDP and ICMP protocols, generally used to check the network connection of each port of the machine.
▲Common usage:
netstat –npl You can check whether the port you want to open has been opened.
netstat –rn Print routing table information.
netstat –in Provides interface information on the system, prints the MTU of each interface, the number of input packets, input errors, the number of output packets, output errors, conflicts and the current output queue length.
##▲ps--Display the status of the current process
There are too many ps parameters. For specific usage methods, please refer to man ps. Commonly used methods: ps aux #hsserver; ps –ef |grep #hundsun
▪ Method to kill a certain program: ps aux | grep mysqld | grep –v grep | awk '{print $2 }' xargs kill -9
##▪ Kill the zombie process: ps –eal | awk '{if ($2 == “Z”){print $4}}' | xargs kill -9
strace Track system calls and signals received during program execution to help analyze abnormal situations encountered during program or command execution. Example: To check which configuration file mysqld loads on Linux, you can run the following command: strace –e stat64 mysqld –print –defaults > /dev/null ▲uptime Be able to print the total number of times the system is running How long and the average load of the system. The last three numbers output by the uptime command mean the average load of the system in 1 minute, 5 minutes, and 15 minutes respectively. ##▲lsof View file system blocking lsof /boot View Which process is occupying the port number lsof -i : 3306 View which files are opened by the user lsof –u username View which files are opened by the process lsof –p 4838 View remote Opened network link lsof –i @192.168.34.128 ##▲perf perf is the system performance optimization tool that comes with the Linux kernel. The advantage lies in its close integration with the Linux Kernel. It can be the first to be applied to new features added to the Kernel to view hot functions and cashe miss ratios, thereby helping developers optimize program performance. The basic principle of performance tuning tools such as perf, Oprofile, etc. is to sample monitored objects. The simplest case is to interrupt based on ticks To perform sampling, that is, trigger the sampling point within the tick interrupt, and determine the current context of the program at the sampling point. If a program spends 90% of its time in function foo(), then 90% of the sampling points should fall in the context of function foo(). Luck is elusive, but I think as long as the sampling frequency is high enough and the sampling time is long enough, the above inference will be more reliable. Therefore, by triggering sampling by tick, we can understand which parts of the program consume the most time and focus on analysis. If you want to know more about this tool, please refer to: Summary: Combining the above commonly used performance test commands and contacting the diagram of the performance analysis tool at the beginning of the article, you can initially understand which aspects of performance are used in the performance analysis process. Aspect tools (commands). 【Commonly used performance testing tools】 Proficient and proficient in the performance analysis of the second part Command tool, introduces several performance testing tools. Before introducing, let’s briefly understand several performance testing tools: ▪ perf_events: a tool that comes with Linux Performance diagnostic tools are released and maintained together with the kernel code and are maintained and developed by the kernel community. Perf can be used not only for performance statistical analysis of applications, but also for performance statistics and analysis of kernel code. More reference: http://blog.sina.com.cn/s/blog_98822316010122ex.html. ##▪ eBPF tools: A tool for performance tracking using bcc, eBPF map can use customized eBPF programs It is widely used in kernel tuning and can also read user-level asynchronous code. The important thing is that this external data can be managed in user space. This k-v format map data body is managed by calling the bpf system call in user space to create, add, delete and other operations. more: http://blog.csdn.net/ljy1988123/article/details/50444693. ▪ perf-tools: A Linux performance analysis and tuning tool set based on perf_events (perf) and ftrace. Perf-Tools has few library dependencies and is easy to use. Supports Linux 3.2 and above kernel versions. more: https://github.com/brendangregg/perf-tools. ▪ bcc (BPF Compiler Collection): A perf performance analysis tool using eBPF. A toolkit for creating efficient kernel tracing and manipulation programs, including several useful tools and examples. Take advantage of Extended BPF (Berkeley Packet Filter), officially called eBPF, a new feature that was first added to Linux 3.15. Multi-purpose requires Linux 4.1 or above BCC. More references: https://github.com/iovisor/bcc#tools. ##▪ ktap: A new type of dynamic performance tracking tool for Linux scripts. Allows users to track Linux kernel dynamics. ktap is designed to be interoperable, allowing users to tune operational insights, troubleshoot and extend kernels and applications. It is similar to Linux and Solaris DTrace SystemTap. More reference: https://github.com/ktap/ktap. ##▪ Flame Graphs: It is a graphics software that uses perf, system tap, ktap visualization, allowing the most frequent Code paths are quickly and accurately identified and can be procedurally generated using the development source code at github.com/brendangregg/flamegraph. More references: http://www.brendangregg.com/flamegraphs.html. #▪ The Basic Tools to learn first are as follows: ▪ The advanced commands are as follows: More reference: http://www.open-open.com/lib/view/open1434589043973.html. For detailed command usage, please refer to man. is a performance Evaluation tools, you can use corresponding tools for performance testing of different modules. If you want to learn more, you can refer to the attached document below. 3. Linux tuning tools | Linux performance tuning tools 4. Linux observability sar | linux performance observation tool sar(System Activity Reporter system activity report) is currently one of the most comprehensive system performance analysis tools on LINUX. It can report system activities from many aspects, including: file reading and writing, system call usage, disk I/O, CPU efficiency, memory usage, process activity and IPC-related activities, etc. Common usage of sar: sar [options] [-A] [-o file] t [n]
http://blog.csdn .net/trochiluses/article/details/10261339
1. Linux observability tools | Linux performance observation tools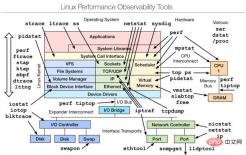
uptime, top(htop), mpstat, isstat, vmstat, free ,ping,nicstat,dstat.
sar, netstat, pidstat, strace, tcpdump, blktrace, iotop, slabtop, sysctl, /proc.
2. Linux benchmarking tools | Linux performance evaluation tool
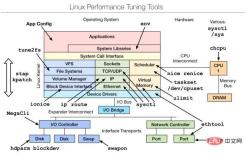
It is a performance tuning tool that mainly performs tuning from the Linux kernel source code layer. If you want to learn more about it, you can refer to the attached document below. 
Where:
t is the sampling interval, n is the number of sampling times, the default value is 1;
-o file means to convert the command result to The binary format is stored in a file, where file is the file name.
options are command line options
The above is the detailed content of Ultra-Comprehensive Collection - Summary Collection of Linux Performance Analysis Tools. For more information, please follow other related articles on the PHP Chinese website!

 What is Maintenance Mode in Linux? ExplainedApr 22, 2025 am 12:06 AM
What is Maintenance Mode in Linux? ExplainedApr 22, 2025 am 12:06 AMMaintenanceModeinLinuxisaspecialbootenvironmentforcriticalsystemmaintenancetasks.Itallowsadministratorstoperformtaskslikeresettingpasswords,repairingfilesystems,andrecoveringfrombootfailuresinaminimalenvironment.ToenterMaintenanceMode,interrupttheboo
 Linux: A Deep Dive into Its Fundamental PartsApr 21, 2025 am 12:03 AM
Linux: A Deep Dive into Its Fundamental PartsApr 21, 2025 am 12:03 AMThe core components of Linux include kernel, file system, shell, user and kernel space, device drivers, and performance optimization and best practices. 1) The kernel is the core of the system, managing hardware, memory and processes. 2) The file system organizes data and supports multiple types such as ext4, Btrfs and XFS. 3) Shell is the command center for users to interact with the system and supports scripting. 4) Separate user space from kernel space to ensure system stability. 5) The device driver connects the hardware to the operating system. 6) Performance optimization includes tuning system configuration and following best practices.
 Linux Architecture: Unveiling the 5 Basic ComponentsApr 20, 2025 am 12:04 AM
Linux Architecture: Unveiling the 5 Basic ComponentsApr 20, 2025 am 12:04 AMThe five basic components of the Linux system are: 1. Kernel, 2. System library, 3. System utilities, 4. Graphical user interface, 5. Applications. The kernel manages hardware resources, the system library provides precompiled functions, system utilities are used for system management, the GUI provides visual interaction, and applications use these components to implement functions.
 Linux Operations: Utilizing the Maintenance ModeApr 19, 2025 am 12:08 AM
Linux Operations: Utilizing the Maintenance ModeApr 19, 2025 am 12:08 AMLinux maintenance mode can be entered through the GRUB menu. The specific steps are: 1) Select the kernel in the GRUB menu and press 'e' to edit, 2) Add 'single' or '1' at the end of the 'linux' line, 3) Press Ctrl X to start. Maintenance mode provides a secure environment for tasks such as system repair, password reset and system upgrade.
 Linux: How to Enter Recovery Mode (and Maintenance)Apr 18, 2025 am 12:05 AM
Linux: How to Enter Recovery Mode (and Maintenance)Apr 18, 2025 am 12:05 AMThe steps to enter Linux recovery mode are: 1. Restart the system and press the specific key to enter the GRUB menu; 2. Select the option with (recoverymode); 3. Select the operation in the recovery mode menu, such as fsck or root. Recovery mode allows you to start the system in single-user mode, perform file system checks and repairs, edit configuration files, and other operations to help solve system problems.
 Linux's Essential Components: Explained for BeginnersApr 17, 2025 am 12:08 AM
Linux's Essential Components: Explained for BeginnersApr 17, 2025 am 12:08 AMThe core components of Linux include the kernel, file system, shell and common tools. 1. The kernel manages hardware resources and provides basic services. 2. The file system organizes and stores data. 3. Shell is the interface for users to interact with the system. 4. Common tools help complete daily tasks.
 Linux: A Look at Its Fundamental StructureApr 16, 2025 am 12:01 AM
Linux: A Look at Its Fundamental StructureApr 16, 2025 am 12:01 AMThe basic structure of Linux includes the kernel, file system, and shell. 1) Kernel management hardware resources and use uname-r to view the version. 2) The EXT4 file system supports large files and logs and is created using mkfs.ext4. 3) Shell provides command line interaction such as Bash, and lists files using ls-l.
 Linux Operations: System Administration and MaintenanceApr 15, 2025 am 12:10 AM
Linux Operations: System Administration and MaintenanceApr 15, 2025 am 12:10 AMThe key steps in Linux system management and maintenance include: 1) Master the basic knowledge, such as file system structure and user management; 2) Carry out system monitoring and resource management, use top, htop and other tools; 3) Use system logs to troubleshoot, use journalctl and other tools; 4) Write automated scripts and task scheduling, use cron tools; 5) implement security management and protection, configure firewalls through iptables; 6) Carry out performance optimization and best practices, adjust kernel parameters and develop good habits.


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

Dreamweaver Mac version
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

WebStorm Mac version
Useful JavaScript development tools

