
Home >Common Problem >Very low-level performance optimization: let the CPU execute your code faster
Very low-level performance optimization: let the CPU execute your code faster
- 嵌入式Linux充电站forward
- 2023-07-31 15:44:431146browse
##The impact of Cache on performance
First we need to know,CPUWhen accessing memory , instead of directly accessing the memory, it first accesses the cache (cache).
When the data we want is already in the cache, CPU will read the data directly from the cache instead of reading from the memory.
The relationship between CPU and cache is as follows:
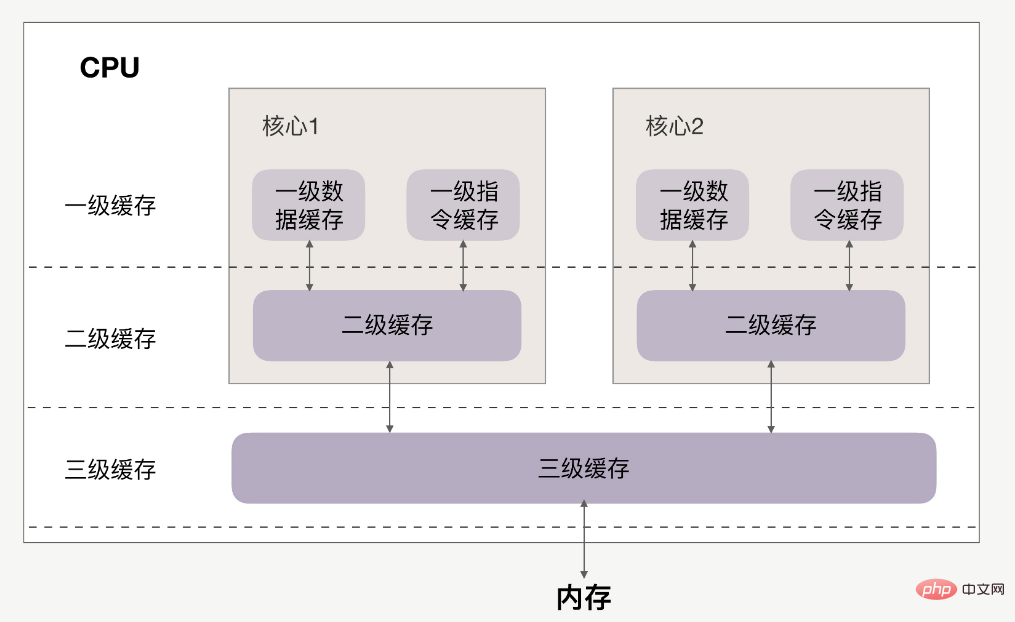
cache is much faster than memory.
If the data operated by the CPU is in the cache, it is read directly from the cache. This process is calledcache hit.
Therefore, the key to improving performance is to increase the cache hit rate. Let’s look at how to improve the cache hit rate.
Improve the data cache hit rate
Let’s look at an example, there is aN*N's two-dimensional array, for example:
int array[N][N];Now use two for loops to traverse this array and access the content of each element:
for(i = 0; i < N; i+=1)
{
for(j = 0; j < N; j+=1)
{
array[i][j] = 0;//速度快
//array[j][i] = 0;//速度慢
}
}
有两种访问方式:array[i][j]和array[j][i]。
在性能上,array[i][j]会比array[j][i]执行地更快,并且速度相差8倍。
1、速度更快的原因
首先数组在内存上是连续的,假设N等于2,则array[2][2]在内存中的排布是:
array[0][0]、array[0][1]、array[1][0]、array[1][1]、
以array[i][j]方式访问,即按内存中的顺序访问,当访问array[0][0]时,CPU就已经把数组的剩余三个数据(array[0][1]、array[1][0]、array[1][1])加载到了缓存当中。
当继续访问后三个元素时,CPU会直接从缓存中读取数据,而不需要从内存中读取(cache命中)。因此速度会很快。
如果以array[j][i]方式访问数组,则访问顺序为:
array[0][0]、array[1][0]、array[0][1]、array[1][1]
此时访问顺序是跳跃的,并不是按数组在内存中的的排布顺序来访问。如果N很大的话,那么执行array[j][i]时,array[j+1][i]的内容是没法读进缓存里的,等到要访问array[j+1][i]时就只能从内存中读取。
所以array[j][i]的速度会慢于array[i][j]。
2、速度相差8倍的原因
刚刚提到,如果这个二维数组的N很大,array[j+1][i]的内容是没法读到缓存里的,那CPU一次能够将多少数据加载进缓存里呢?
这个其实跟cache line有关,cache line代表缓存一次载入数据的大小。可以通过以下命令查看cache line为多大:
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size

cache line为64,代表CPU缓存一次数据的大小为64字节。
When accessing array[0][0], the number of bytes occupied by the element is less than 64 bytes, CPU will press To supplement subsequent elements in sequence, the following array[0][1], array[1][0] and other contents will be read into the cache together until ## is collected. #64Bytes.
array[i][j] accessed in sequence will be faster than array[j][i] accessed out of sequence .
Let’s look at why the speed difference is 8 times. We know that in a two-dimensional array, the first-dimensional element is the address, and the second-dimensional element is the data. In the 64 bit system, the address occupies 8 bytes. If the cache line is 64, the address has occupied 8 bytes, then each cache line can load no more than 8 two-dimensional array elements at most. When N is very large, they On average, the performance will differ by nearly 8 times.
Conclusion: Accessing in memory layout order can improve the data cache hit rate.
Improve the hit rate of the instruction cache
What we talked about earlier was the data cache, now let’s look at the instruction cache How to improve the hit rate.
有一个数组array,数组元素内容为0-255之间的随机数:
int array[N]; for (i = 0; i < TESTN; i++) array[i] = rand() % 256;
现在,要把数组中数字小于128的元素置为0,并且对数组排序。
大家应该都能想到,有两种方法:
先遍历数组,把小于128的元素置为0,然后排序。 先对数组排序,再遍历数组,把小于128的元素置为0。
for(i = 0; i < N; i++) {
if (array [i] < 128)
array[i] = 0;
}
sort(array, array +N);先排序后遍历的速度会比较快,为什么?
因为在for循环中会执行很多次if分支判断语句,而CPU拥有分支预测器。
如果分支预测器可以预测接下来要执行的分支(执行if还是执行else),那么就可以提前把这些指令放到缓存中,CPU执行的时候就会很快了。
如果一个数组的内容完全随机的话,那么分支预测器就很难进行正确的预测。但如果数组内容是有序的,它就会根据历史命中数据的情况对未来进行预测,那命中率就会很高,所以先排序后遍历的速度会比较快。
怎么验证指令缓存命中率的情况呢?
Under Linux, you can use the Perf performance analysis tool for verification. Through the -e option, specify the branch-loads and branch-loads-misses events, you can count the number of branch prediction successes and The number of failed branch predictions, the number of instruction misses in the first-level cache can also be counted through the L1-icache-load-misses event. However, these performance events are all hardware events. Whether the perf tool can count these events depends on whether CPU supports it and whether the original chip manufacturer implements this interface. I think Many of them are not supported or implemented.
In addition, in the Linux kernel, you can see a large number of likely and unlikely macros, and they all appear if statements , the purpose of these two macros is to improve performance.
This is a macro that displays the prediction probability. If you feel that the CPU branch prediction is inaccurate, but the probability of the condition in if being "true" is very high, then you can use likely()enclosed to improve performance.
#define likely(x) __builtin_expect(!!(x), 1) #define unlikely(x) __builtin_expect(!!(x), 0) if (likely(a == 1)) …
提高多核CPU下的缓存命中率
首先要清楚,一级缓存、二级缓存是每颗核心独享的,三级缓存则面向所有核心。
但多核CPU下的系统有个特点,存在CPU核心迁移问题。
For example, process A uses CPUcore1 during the time slice, naturally filling up CPUcore1's first and second level cache, but based on the scheduling policy, after the time slice ends, CPUcore1 will be given up to prevent some processes from starving to death. If CPUCore1 is very busy at this time, then process A is likely to be scheduled to CPUCore2Run on. In this case, no matter how we optimize the code, we can only efficiently use the CPU primary and secondary caches within one time slice, and we will face cache efficiency problems in the next time slice.
In this case, you canconsider binding the process to the CPU to run.
Theperf tool also provides statistics on this type of performance event, called cpu-migrations, which is CPU migration times. If the number of CPU migrations is large, the cache efficiency will be low.
Bind the process to the CPU to run, and the performance will also be improved.
Summary
These are the impact of CPU cache on performance, this It is already a very low-level performance optimization, and it is effective regardless of the programming language.
To truly understand caching, I believe your understanding of the underlying layer will be of great help.
Improve data cache hit rate: Sequentially operate continuous memory data Improve instruction cache hit rate : Regular conditional branches ##Improve the cache hit rate of multi-core CPU: Consider binding the process to the CPU to run
The above is the detailed content of Very low-level performance optimization: let the CPU execute your code faster. For more information, please follow other related articles on the PHP Chinese website!