
Home >Backend Development >Golang >Go language mechanism stack and pointers
Go language mechanism stack and pointers
- Go语言进阶学习forward
- 2023-07-24 16:10:54968browse
This series contains four articles, mainly explaining the mechanisms and design concepts behind Go language pointers, stacks, heaps, escape analysis, and value/pointer semantics. This is the first article in the series, mainly explaining stacks and pointers.
Introduction
I'm not going to put in a good word for pointers, it's really hard to understand. If used incorrectly, it can lead to annoying bugs and even performance issues. This is especially true when writing concurrent or multi-threaded software. It's no wonder that many programming languages try to avoid using pointers for programmers. However, if you use Go programming language, pointers are unavoidable. Only by deeply understanding pointers can you write clean, concise and efficient code.
Frame boundary
The frame boundary provides a separate memory space for each function, and the function is executed within the frame boundary. Frame boundaries allow functions to run in their own context and also provide flow control. Functions can directly access memory within the frame through the frame pointer, while accessing memory outside the frame can only be done indirectly. For each function, if you want to be able to access memory outside the frame, this memory must be shared with the function. To understand the shared implementation, we need to first learn and understand the mechanisms and constraints for establishing frame boundaries.
When a function is called, a context switch occurs between two frame boundaries. From the calling function to the called function, if parameters need to be passed when the function is called, these parameters must also be passed within the frame boundaries of the called function. In the Go language, data is transferred between two frames by value.
The advantage of passing data by value is good readability. When a function is called, the value you see is the value that is copied and received between the function caller and the callee. That's why I associate "pass by value" with WYSIWYG, because what you see is what you get.
Let’s look at a piece of code that passes integer data by value:
Listing 1
package main
func main() {
// Declare variable of type int with a value of 10.
count := 10
// Display the "value of" and "address of" count.
println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")
// Pass the "value of" the count.
increment(count)
println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")
}
//go:noinline
func increment(inc int) {
// Increment the "value of" inc.
inc++
println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]")
}When you start a Go program, the runtime will create a main coroutine to execute all initialization code including the code in the main() function. Goroutine is an execution path placed on the operating system thread, and is ultimately executed on a certain core. Starting from Go 1.8, each goroutine will allocate a 2048-byte contiguous memory block as its stack space. The size of the initial stack space has been changing over the years and may change again in the future.
The stack is very important because it provides the physical memory space for the frame boundaries of each individual function. According to Listing 1, when the main coroutine executes the main() function, the stack space is distributed as follows:
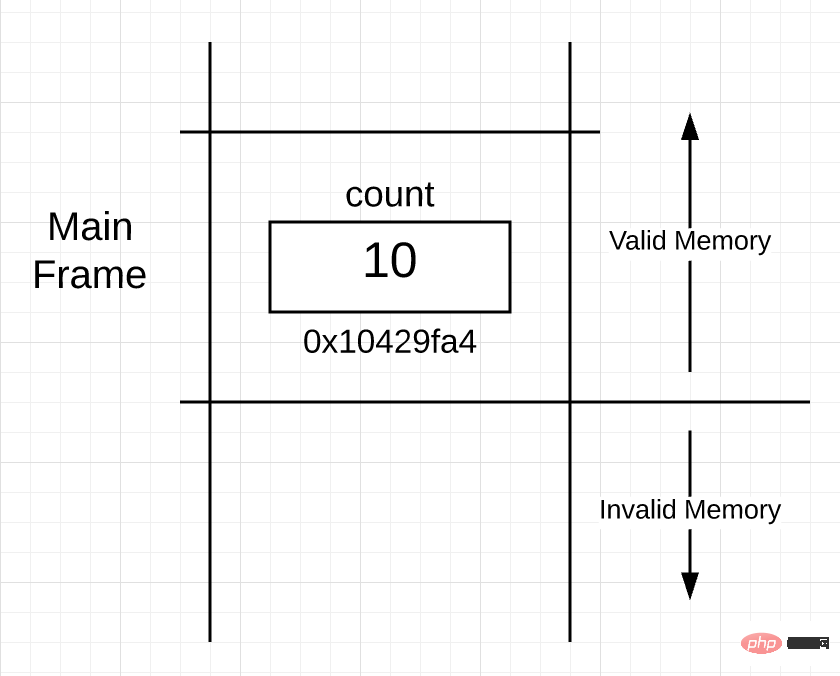
Figure 1
You can see in Figure 1 that part of the stack of the main function has been framed. This part is called a "stack frame", and this frame represents the boundary of the main function on the stack. The frame is created when the called function is executed. You can also see that the variable count is placed in the main() function frame at the memory address of 0x10429fa4.
Figure 1 also illustrates another interesting point. All stack memory below the active frame is unavailable. Only the stack memory above the active frame is available. The boundary between available stack space and unavailable stack space needs to be clarified.
Address
The purpose of a variable is to assign a name to a specific memory address, making the code more readable and helping you analyze the data you are processing. If you have a variable and you can get its value stored in memory, there must be an address in the memory address that stores this value. In line 9 of code, the main() function calls the built-in function println() to display the value and address of the variable count.
Listing 2
println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")It is not surprising to use the & operator to get the address of the memory location where a variable is located. Other languages also use this operator. If your code is running on a 32-bit computer, such as go playground, the output will be similar to the following:
清单3
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
函数调用
接下来的第 12 行代码,main() 函数调用 increment() 函数。
清单4
increment(count)
调用函数意味着协程需要在栈上构建出一块新的栈帧。但是,事情有点复杂。要想成功地调用函数,在发生上下文切换时,数据需要跨越帧边界传递到新的帧范围内。具体一点来说,函数调用的时候,整型值会被复制和传递。通过第 18 行代码、increment() 函数的声明,你就可以知道。
清单5
func increment(inc int) {如果你回过头来再次看第 12 行代码函数 increment() 的调用,你会发现 count 变量是传值的。这个值会被拷贝、传递,最后存储在 increment() 函数的栈中。记住,increment() 函数只能在自己的栈内读写内存,因此,它需要 inc 变量来接收、存储和访问传递的 count 变量的副本。
就在 increment() 函数内部代码开始执行之前,协程的栈(站在一个非常高的角度)应该是像下图这样的:
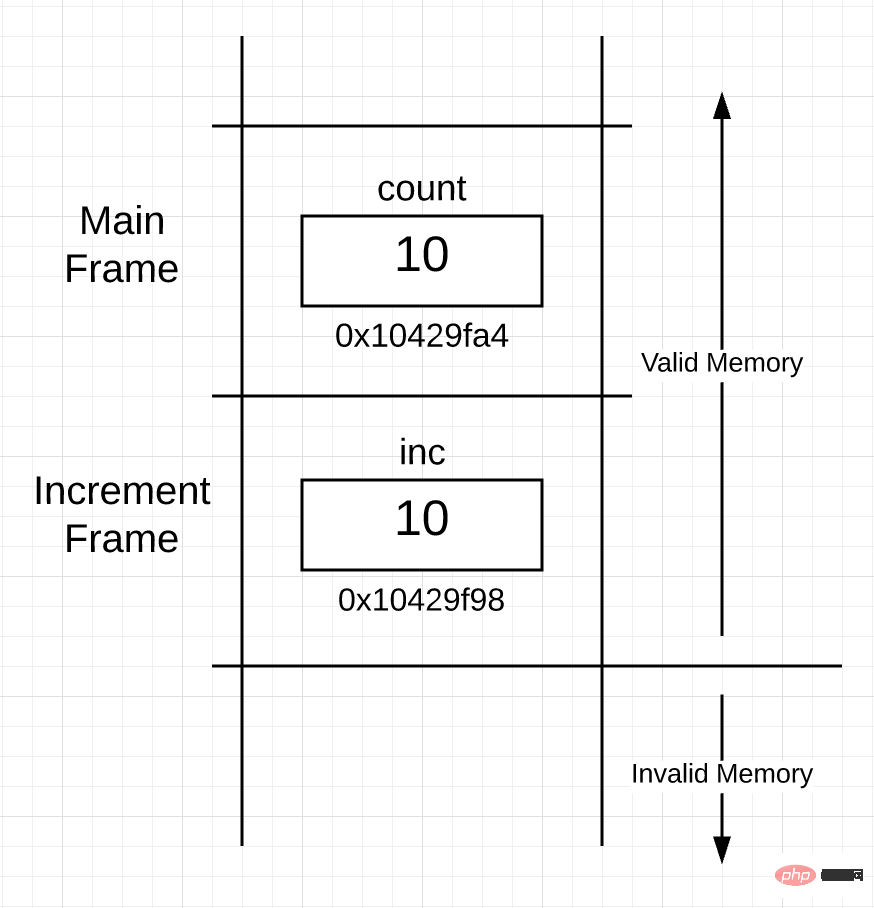
图 2
你可以看到栈上现在有两个帧,一个属于 main() 函数,另一个属于 increment() 函数。在 increment() 函数的帧里面,你可以看到 inc 变量,它的值 10,是函数调用时拷贝、传递进来的。变量 inc 的地址是 0x10429f98,因为栈帧是从上至下使用栈空间的,所以它的内存地址较小,这只是具体的实现细节,并没任何意义。重要的是,协程从 main() 的栈帧里获取变量 count 的值,并使用 inc 变量将该值的副本放置在 increment() 函数的栈帧里。
increment() 函数的剩余代码显示 inc 变量的值和地址。
清单6
inc++
println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]")第 22 行代码输出类似下面这样:
清单7
inc: Value Of[ 11 ] Addr Of[ 0x10429f98 ]
执行这些代码之后,栈就会像下面这样:
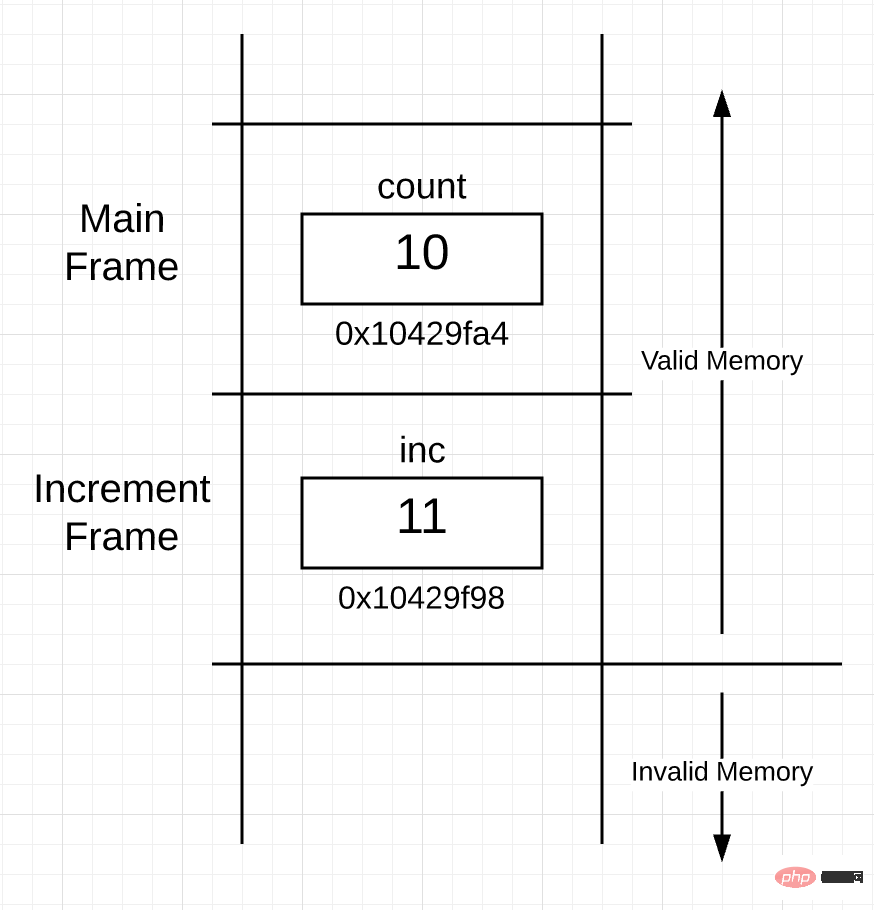
图 3
第 21、22 行代码执行之后,increment() 函数返回并且 CPU 控制权交还给 main() 函数。第 14 行代码,main() 函数会再次显示 count 变量的值和地址。
清单8
println("count:\tValue Of[",count, "]\tAddr Of[", &count, "]")上面例子完整的输出会像下面这样:
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ] inc: Value Of[ 11 ] Addr Of[ 0x10429f98 ] count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
main() 函数栈帧里,变量 count 的值在调用 increment() 函数前后是相同的。
函数返回
当函数返回并且控制权交还给调用函数时,栈上的内存实际上会发生什么?回答是:不会发生任何事情。当 increment() 函数返回时,栈上的空间看起来像下面这样:
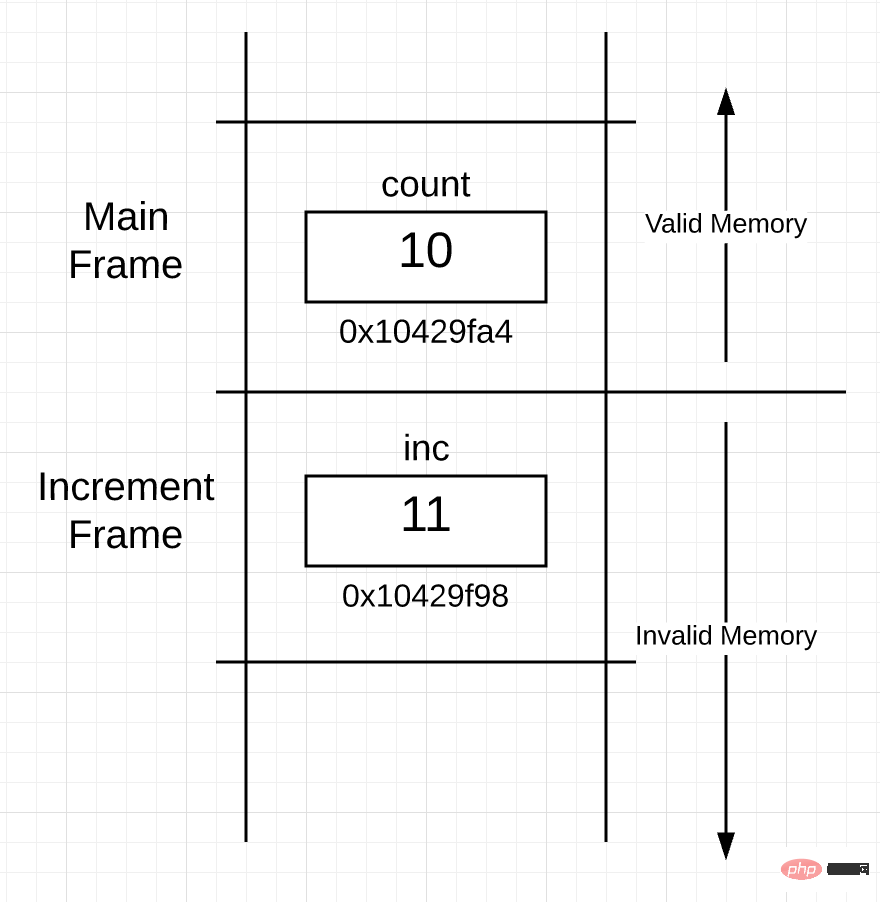
Figure 4
The distribution of the stack is basically the same as Figure 3, except that the stack frame created for the increment() function becomes unavailable. This is because the main() function's frame becomes the active frame. No processing is done on the stack frame of the increment() function.
When the function returns, cleaning up the function's frame will waste time because you don't know whether this memory will be used again. So this memory will not do any processing. Each time a function is called, the frames allocated on the stack will be cleared when a frame is needed. This is done when initializing the variables stored in the frame. Because all values are initialized to their corresponding zero values, the stack cleans itself correctly every time the function is called.
Shared value
What if it is very important that the increment() function directly operates the count variable stored in the main() function frame? This requires the use of pointers! The purpose of pointers is to share values between functions. Even if the value is not in the frame of its own function, the function can read and write it.
If you don't have the concept of sharing in your mind, you probably won't use pointers. When learning pointers, it is important to use a clear vocabulary rather than simply memorizing operators or syntax. So, remember that pointers are meant to be shared and when reading code, when you think of "sharing", you should think of the & operator.
Pointer type
Whether it is customized by you or comes with the Go language, for each declared type, you can obtain the corresponding pointer type based on these types for sharing. . For example, the built-in type int, the corresponding pointer type is *int. If you declare the type User yourself, the corresponding pointer type is *User.
All pointer types have the same characteristics. First, they start with the * symbol; second, they occupy the same memory space and both represent an address, using 4 or 8 bytes in length to represent an address. On a 32-bit machine (such as a playground), a pointer requires 4 bytes of memory; on a 64-bit machine (such as your computer), it requires 8 bytes of memory.
规范里有说明,指针类型可以看成是类型字面量,这意味着它们是有现有类型组成的未命名类型。
间接访问内存
让我们来看一段代码,这段代码展示了函数调用时按值传递地址。main() 和 increment() 函数的栈帧会共享 count 变量:
清单10
package main
func main() {
// Declare variable of type int with a value of 10.
count := 10
// Display the "value of" and "address of" count.
println("count:\tValue Of[", count, "]\t\tAddr Of[", &count, "]")
// Pass the "address of" count.
increment(&count)
println("count:\tValue Of[", count, "]\t\tAddr Of[", &count, "]")
}
//go:noinline
func increment(inc *int) {
// Increment the "value of" count that the "pointer points to". (dereferencing)
*inc++
println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]\tValue Points To[", *inc, "]")
}基于原来的代码有三处改动的地方,第 12 行是第一处改动:
清单11
increment(&count)
现在,第 12 行代码拷贝、传递的并非 count 变量的值,而是变量的地址。可以认为,main() 函数与 increment() 函数是共享 count 变量的。这是 & 操作符起的作用。
重点理解,现在依旧是传值,唯一不同的是现在传递的是地址而不是一个整型数据。地址也是一个值,是函数调用时会跨帧边界发生拷贝和传递的内容。
因为地址会发生拷贝和传递,在 increment() 函数里面需要一个变量接收和存储该地址值。所以在第 18 行声明了整型的指针变量。
清单12
func increment(inc *int) {如果你传递的是 User 类型值的地址,变量就应该声明成 *User。尽管指针变量存储的是地址,也不能传递任何类型的地址,只能传递与指针类型相一致的地址。关键在于,共享值的原因是因为接收函数能够对值进行读写操作。只有知道值的类型信息才能够进行读写操作。编译器会保证只有与指针类型相一致的值才能够实现函数间共享。
调用 increment() 函数时候,栈空间就像下面这样:
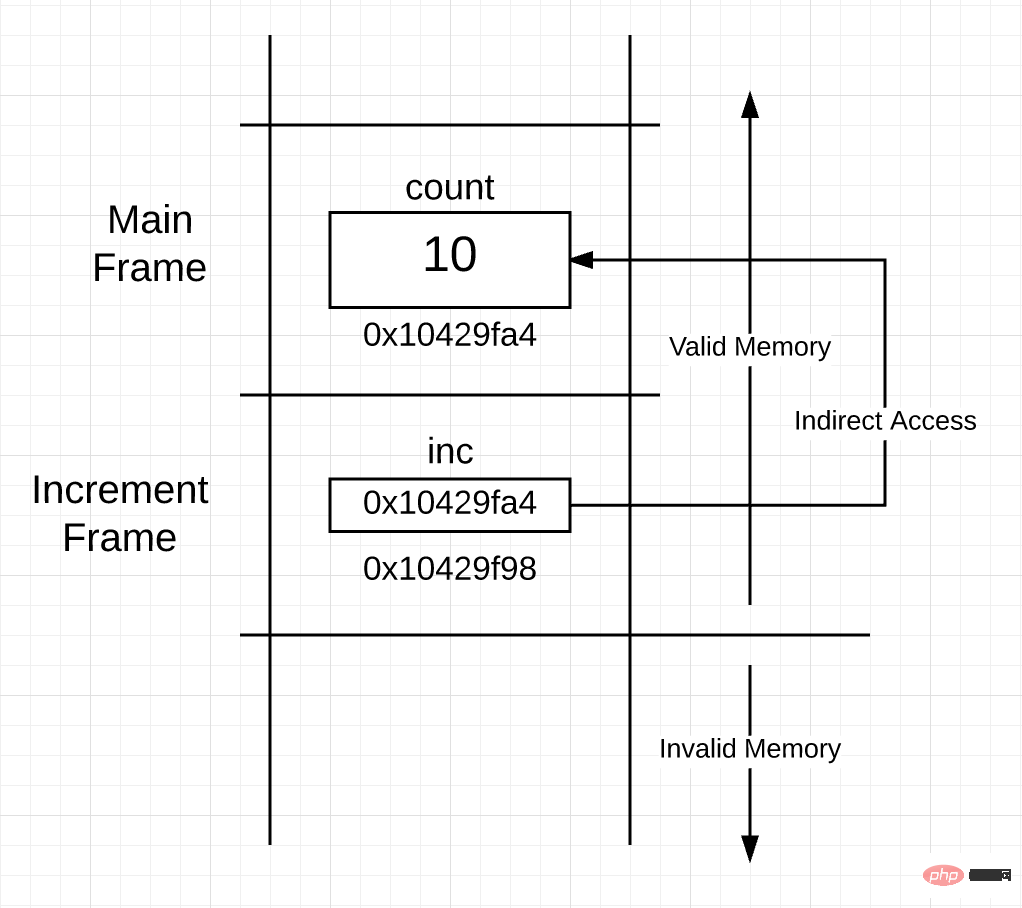
图 5
当一个地址作为值执行按值传递之后,你可以从图 5 看出栈是如何分布的。现在,increment() 函数帧空间里面的指针变量指向 count 变量,该变量在 main() 函数的帧空间里。
通过使用指针变量,increment() 函数可以间接对 count 变量执行读写操作。
清单 13
*inc++
这一次,字符 * 充当操作符,与指针变量搭配使用。使用 * 操作符是“获取指针指向的值”的意思。指针变量允许在帧外对函数帧内的内存进行间接访问。有时候,间接的读写操作也称为解引用。increment() 函数必须有指针变量,才能够对其他函数帧空间执行间接访问。
执行第 21 行代码之后,栈空间分布如图 6 所示。
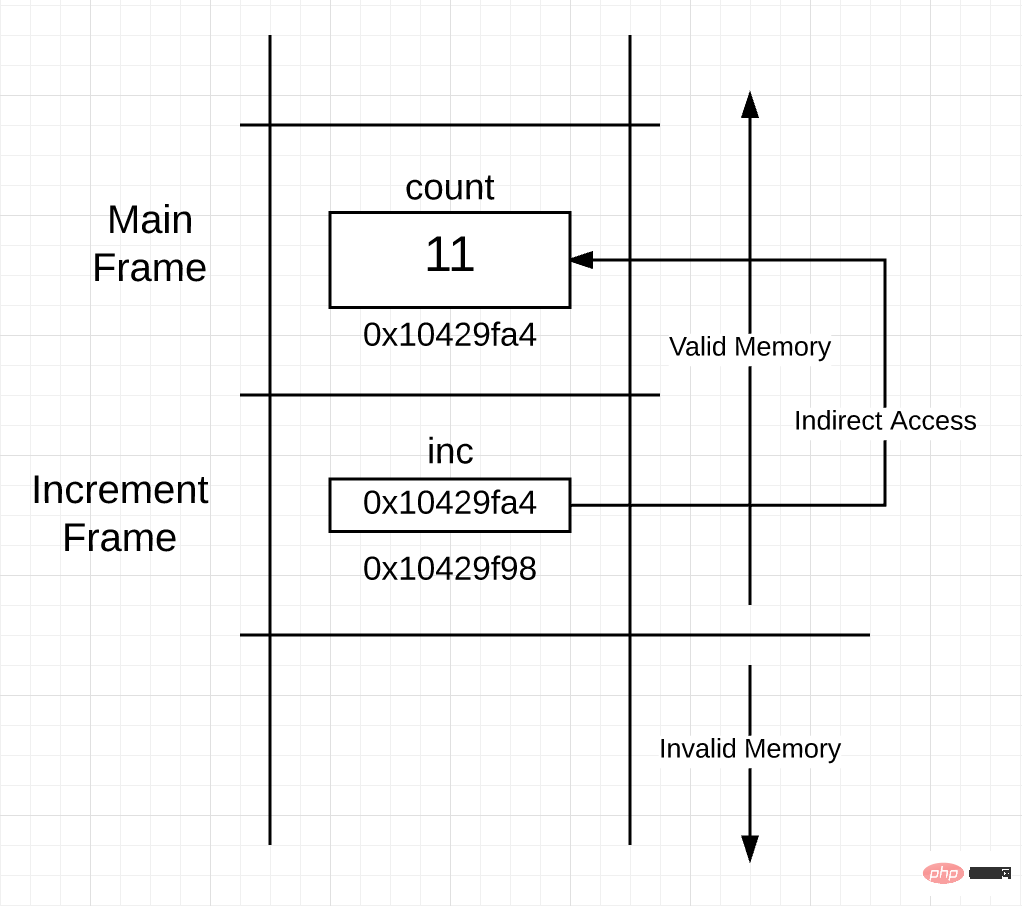
图 6
程序最后输出:
清单 14
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ] inc: Value Of[ 0x10429fa4 ] Addr Of[ 0x10429f98 ] Value Points To[ 11 ] count: Value Of[ 11 ] Addr Of[ 0x10429fa4 ]
你可以看到,指针变量 inc 的值和 count 变量的地址是相同的。这将建立起共享关系,允许在帧外执行内存的间接访问。在 increment() 函数里,一旦通过指针执行了写操作,改变也会体现在 main() 函数里。
指针变量并不特别
指针变量并不特别,它们和其他变量一样也是变量,有内存地址和值。正巧的是,无论指针变量指向的值的类型如何,所有的指针变量都有同样的大小和表现形式。唯一困惑的是使用 * 字符充当操作符,用来声明指针类型。如果你能分清指针类型声明和指针操作,你就没有那么困惑了。
总结
这篇文章描述了设计指针背后的目的和 Go 语言中栈和指针的工作机制。这是理解 Go 语言机制、设计哲学的第一步,也对编写一致性且可读性的代码提供一些指导作用。
总结一下,通过这篇文章你能学习到的知识:
1.The frame boundary provides a separate memory space for each function, and the function is executed within the frame range; 2.When When the function is called, the context environment will switch between the two frames;3.The advantage of passing by value is good readability; 4.The stack is important because it provides accessible physical memory space for the frame boundary of each function;5.All stack memory below the active frame is inaccessible Used, only the active frame and the stack memory above it are useful;6.Calling the function means that the coroutine will open a new stack frame on the stack memory;7.Every time a function is called, when a frame is used, the corresponding stack memory will be initialized; 8.Design pointer The purpose is to realize value sharing between functions. Even if the value is not in the function's own stack frame, it can still be read and written; 9.For each type, whether it is its own The definitions are built-in in the Go language and have corresponding pointer types; 10. By using pointer variables, indirect memory access is allowed outside the function frame; 11.Compared with other variables, there is nothing special about pointer variables, because they are also variables, with memory addresses and values.
The above is the detailed content of Go language mechanism stack and pointers. For more information, please follow other related articles on the PHP Chinese website!