
How Redis implements master-slave replication

- 王林forward
- 2023-05-30 08:01:482116browse
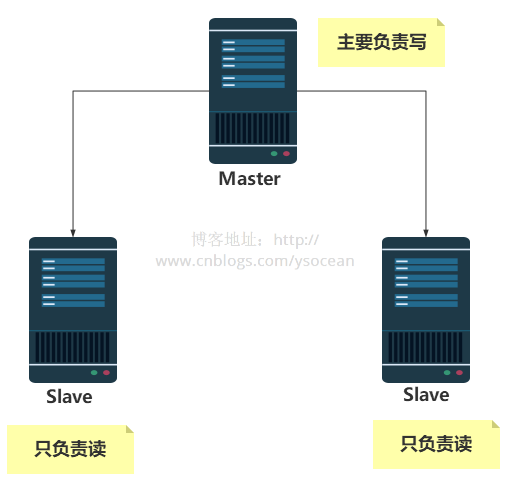
Introducing Redis earlier, we all operate on a server, which means that reading, writing and backup operations are all performed on a Redis server. As the number of project visits increases, the Redis server Operations are also becoming more frequent. Although Redis is very fast in reading and writing, it will also cause a certain delay to a certain extent. In order to solve the problem of large access volume, one method usually adopted is the master-slave architecture Master/ Slave and Master are mainly for writing, and Slave is mainly for reading. After the Master node is updated, it will automatically synchronize to the slave Slave node according to the configuration.
Next we will introduce how to build a master-slave architecture.
ps: Here I am simulating multiple Redis servers on one machine. Compared with the actual production environment, the basic configuration is the same, only the IP address and port number change.
1. Modify the configuration file
First, copy the redis.conf configuration file into three copies and simulate three Redis servers by modifying the ports.

Then we modify these three redis.conf files respectively.
①、Modify daemonize yes

Indicates that the specified Redis will be started as a daemon process (background startup)
②. Configure the PID file path pidfile

Indicates that when redis is running as a daemon process, it will write the pid to /var/redis by default In the /run/redis_6379.pid file
③、Configure port port

④、Configure log file name

⑤、Configure the rdb file name

Change 6380redis.conf, 6381Redis.conf is configured once, and the configuration is complete.
Next we start these three services respectively.

Use the command to check whether Redis is started:

Next, enter the three Redis clients through the following commands Terminal:
|
1 2 3 |
|
2. Set the master-slave relationship
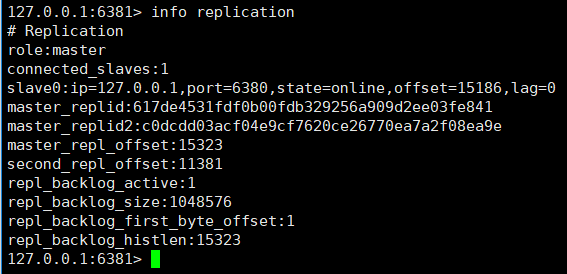
①、View the node role through the info replication command
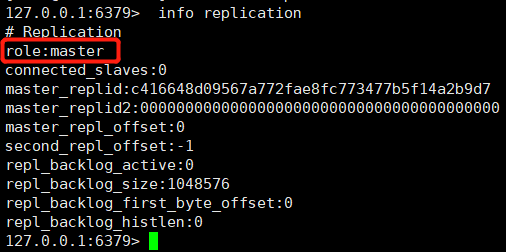
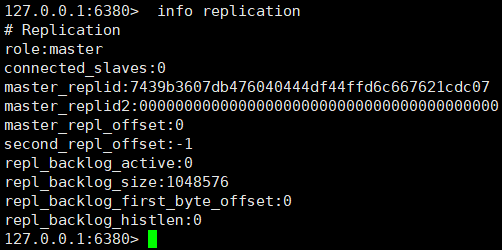
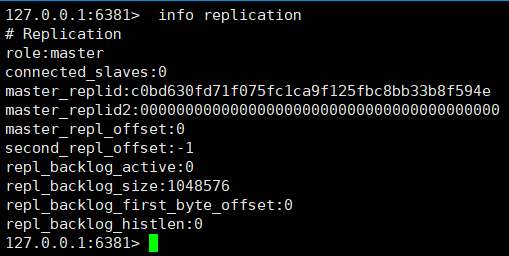
We found that these three nodes all play the role of Master. How to convert nodes 6380 and 6381 to slave node role?
②. Select port 6380 and port 6381 and execute the command: SLAVEOF 127.0.0.1 6379
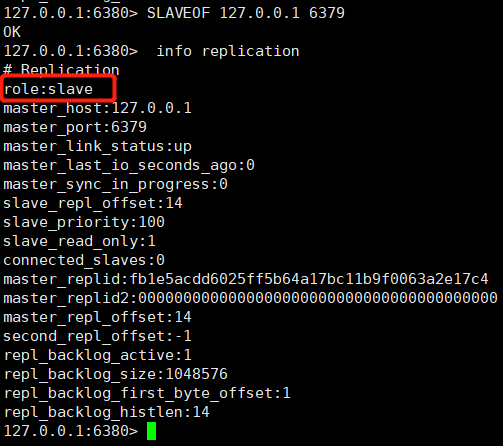
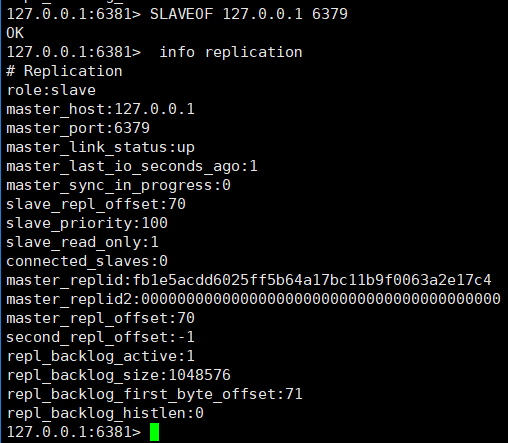
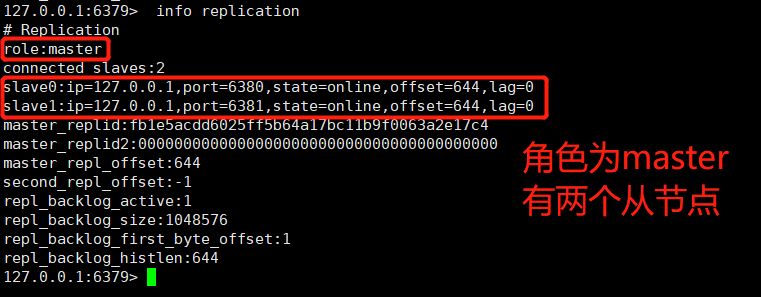
Let’s look at the 6379 node information:
Once the service is restarted, the master-slave relationship previously set through the command will become invalid. This relationship can be permanently saved by configuring the redis.conf file.
3. Test the master-slave relationship
①.Incremental replication
The master node executes the set k1 v1 command. Can the slave node get k1? ?
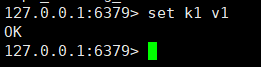
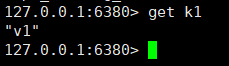
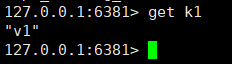
It can be seen from the picture above that it can be obtained.
②、Full copy
By executing SLAVEOF 127.0.0.1 6379, if there are still some keys before the master node 6379, then after executing the command, the slave node will copy the previous Have you copied all the information?
The answer is yes, I won’t post the test results here.
③. Master-slave read and write separation
Can the master node execute write commands, and can the slave node execute write commands?

The reason here is the configuration of slave-read-only in the configuration file 6381redis.conf

If After we change it to no, it is possible to execute the write command.
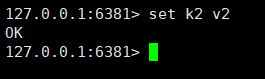
But the data of the slave node write command cannot be obtained from the slave node or the master node.
④. Master node downtime
If the master node Master hangs up, will the roles of the two slave nodes change?
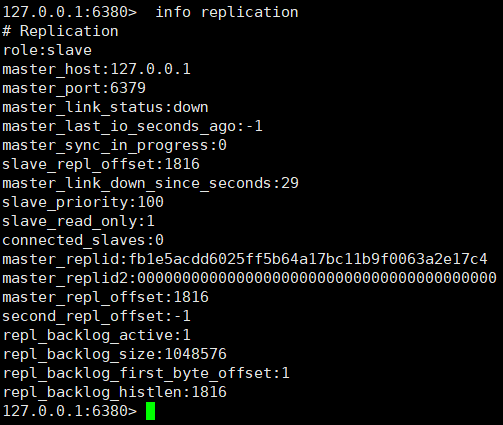
It can be seen from the above figure that after the master node Master hangs up, the role of the slave node will not change.
⑤. Recovery after the master node goes down
After the master node Master hangs up, start the host Master immediately. Does the master node still play the role of Master?
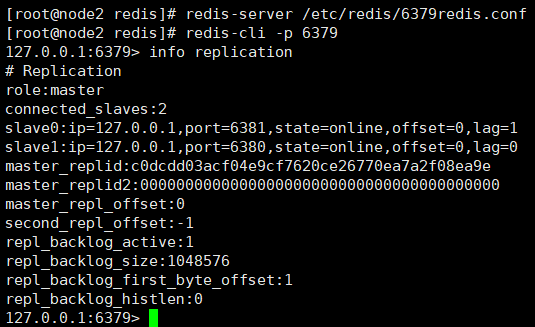
That is to say, after the master node hangs up, it restarts and resumes its role as the master node.
4. Sentinel Mode
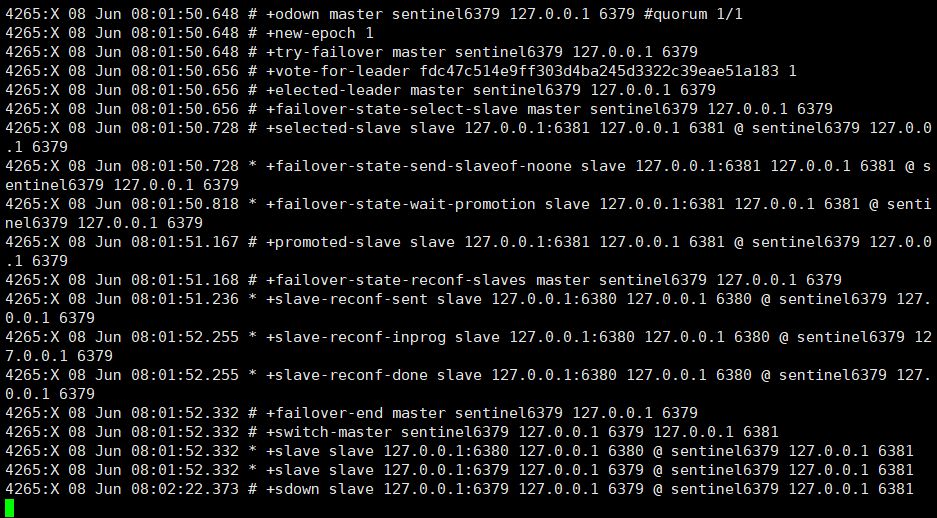
Through the previous configuration, there is only one master node Master. Once the master node hangs up, the slave node cannot take on the task of the master node, and the entire system cannot run. The sentinel mode was born from this, because the slave node can automatically take over the responsibilities of the master node, solving the problem of master node downtime.
The sentry mode is to monitor whether redis is running well as expected from time to time (at least to ensure that the master node exists). If there is a problem with a host, the sentry will automatically remove a slave machine under the host. Set it as a new host and let other slaves establish a master-slave relationship with the new host.
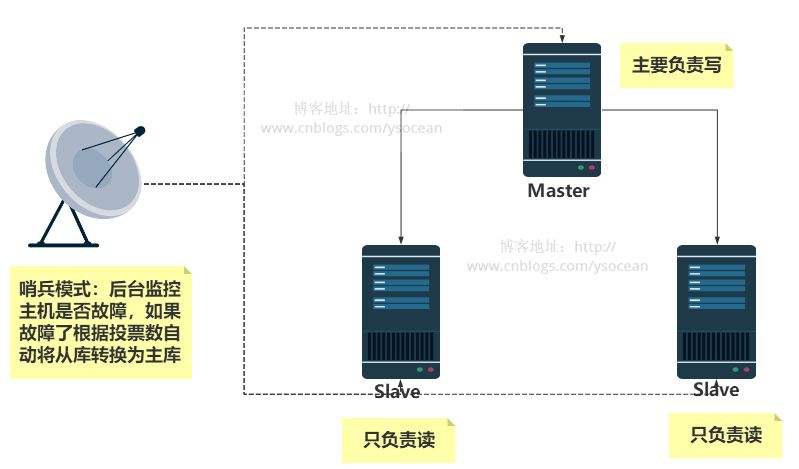
Steps to build sentinel mode:
①Create a new sentinel.conf file in the configuration file directory. The name must not be wrong, and then configure the corresponding content
1 |
|

Configure the monitored name, IP address, port number, and number of votes respectively. When the master machine goes down, the slave machine needs to vote to decide who will take over as the master machine. When the number of votes reaches 1, it is not enough to become the master machine. It must exceed 1 to become the master machine.
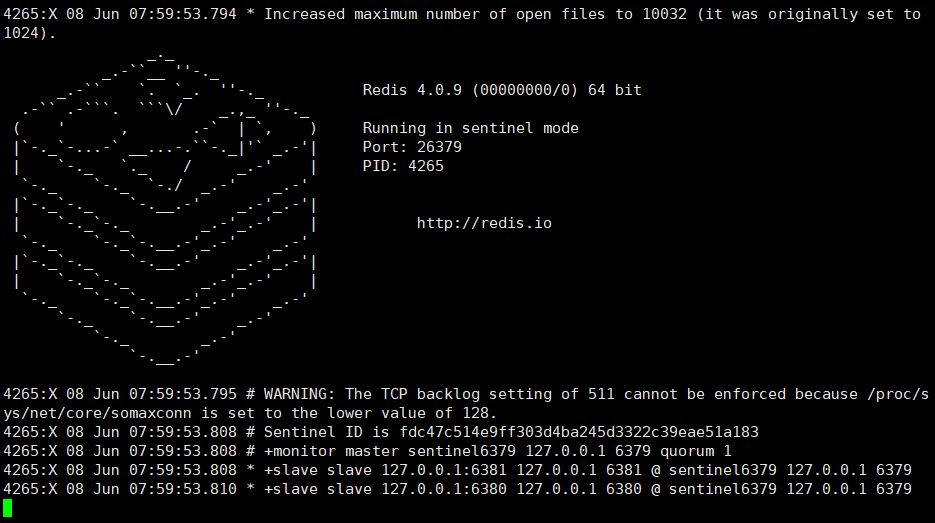
②. Start the sentinel
1 |
##redis-sentinel /etc/redis/sentinel.conf |
The above is the detailed content of How Redis implements master-slave replication. For more information, please follow other related articles on the PHP Chinese website!