

 Technology peripheralsAIMulti-path, multi-domain, all-inclusive! Google AI releases multi-domain learning general model MDL
Technology peripheralsAIMulti-path, multi-domain, all-inclusive! Google AI releases multi-domain learning general model MDLMulti-path, multi-domain, all-inclusive! Google AI releases multi-domain learning general model MDL

Deep learning models for visual tasks (such as image classification) are usually trained end-to-end with data from a single visual domain (such as natural images or computer-generated images).
Generally, an application that completes visual tasks for multiple fields needs to build multiple models for each separate field and train them independently, without sharing data between different fields. , at inference time, each model will process domain-specific input data.
Even if they are oriented to different fields, some features of the early layers between these models are similar, so joint training of these models is more efficient. This reduces latency and power consumption, and reduces the memory cost of storing each model parameter. This approach is called multi-domain learning (MDL).
In addition, MDL models can also be better than single-domain models. Additional training in one domain can improve the performance of the model in another domain. This is called "forward knowledge." Transfer", but may also produce negative knowledge transfer, depending on the training method and specific domain combination. Although previous work on MDL has demonstrated the effectiveness of cross-domain joint learning tasks, it involves a hand-crafted model architecture that is inefficient when applied to other tasks.

Paper link: https://arxiv.org/pdf/2010.04904.pdf
In order to solve this problem, in the article "Multi-path Neural Networks for On-device Multi-domain Visual Classification", Google researchers proposed a general MDL model.
The article states that this model can effectively achieve high accuracy, reduce negative knowledge transfer, and learn to enhance positive knowledge transfer, and can handle difficulties in various specific fields. When , the joint model can be effectively optimized.

To this end, the researchers proposed a multi-path neural architecture search (MPNAS) method to establish A unified model with heterogeneous network architectures.
This method extends the efficient neural structure search (NAS) method from single-path search to multi-path search to jointly find an optimal path for each field. A new loss function is also introduced, called Adaptive Balanced Domain Prioritization (ABDP), which adapts to domain-specific difficulties to help train models efficiently. The resulting MPNAS method is efficient and scalable.
The new model reduces model size and FLOPS by 78% and 32% respectively compared with single-domain methods while maintaining performance without degradation.
Multi-path neural structure search
In order to promote positive knowledge transfer and avoid negative transfer, the traditional solution is to establish an MDL model so that all domains can share it Most of the layers learn the shared features of each domain (called feature extraction), and then build some domain-specific layers on top. However, this feature extraction method cannot handle domains with significantly different characteristics (such as objects in natural images and artistic paintings). On the other hand, building a unified heterogeneous structure for each MDL model is time-consuming and requires domain-specific knowledge.

Multi-path neural search architecture framework NAS is a powerful paradigm for automatically designing deep learning architectures . It defines a search space consisting of various potential building blocks that may become part of the final model.
The search algorithm finds the best candidate architecture from the search space to optimize model goals, such as classification accuracy. Recent NAS methods, such as TuNAS, improve search efficiency by using end-to-end path sampling.
Inspired by TuNAS, MPNAS established an MDL model architecture in two stages: search and training.
In the search phase, in order to jointly find an optimal path for each domain, MPNAS creates a separate reinforcement learning (RL) controller for each domain, which starts from the super network (i.e., defined by the search space Sample end-to-end paths (from the input layer to the output layer) from a superset of all possible subnetworks between candidate nodes.
Over multiple iterations, all RL controllers update paths to optimize RL rewards in all areas. At the end of the search phase, we obtain a subnetwork for each domain. Finally, all sub-networks are combined to create a heterogeneous structure for the MDL model, as shown in the figure below.

Since the subnetwork of each domain is searched independently, the Components can be shared by multiple domains (i.e. dark gray nodes), used by a single domain (i.e. light gray nodes), or not used by any subnetwork (i.e. point nodes).
The path of each domain can also skip any layer during the search process. The output network is both heterogeneous and efficient, given that subnetworks are free to choose which blocks to use along the way in a way that optimizes performance.
The following figure shows the search architecture of two areas of Visual Domain Decathlon.

Visual Domain Decathlon was tested as part of the PASCAL in Detail Workshop Challenge at CVPR 2017 Improves the ability of visual recognition algorithms to process (or exploit) many different visual domains. As can be seen, the subnetworks of these two highly related domains (one red, the other green) share most of the building blocks from their overlapping paths, but there are still differences between them.

The red and green paths in the figure represent the subnetworks of ImageNet and Describable Textures respectively, and the dark pink nodes represent blocks shared by multiple domains. , light pink nodes represent the blocks used by each path. The "dwb" block in the diagram represents the dwbottleneck block. The Zero block in the figure indicates that the subnet skips the block The figure below shows the path similarity in the two areas mentioned above. Similarity is measured by the Jaccard similarity score between subnets for each domain, where higher means more similar paths.

The picture shows the confusion matrix of Jaccard similarity scores between paths in ten domains. The score ranges from 0 to 1. The larger the score, the more nodes the two paths share.
Training heterogeneous multi-domain models
In the second phase, the models produced by MPNAS will be trained from scratch for all domains. To do this, it is necessary to define a unified objective function for all domains. To successfully handle a wide variety of domains, the researchers designed an algorithm that adjusts throughout the learning process to balance losses across domains, called Adaptive Balanced Domain Prioritization (ABDP). Below shows the accuracy, model size and FLOPS of models trained under different settings. We compare MPNAS with three other methods:
Domain-independent NAS: models are searched and trained separately for each domain.
Single path multi-head: Use a pre-trained model as a shared backbone for all domains, with separate classification heads for each domain.
Multi-head NAS: Search a unified backbone architecture for all domains, with separate classification heads for each domain.
From the results, we can observe that NAS requires building a set of models for each domain, resulting in large models. Although single-path multi-head and multi-head NAS can significantly reduce model size and FLOPS, forcing domains to share the same backbone introduces negative knowledge transfer, thereby reducing overall accuracy.

In contrast, MPNAS can build small and efficient models while still maintaining high overall accuracy. The average accuracy of MPNAS is even 1.9% higher than the domain-independent NAS method because the model is able to achieve active knowledge transfer. The figure below compares the top-1 accuracy per domain of these methods.

Evaluation shows that by using ABDP as part of the search and training stages, top-1 The accuracy increased from 69.96% to 71.78% (increment: 1.81%).
Future Direction
MPNAS is to build a heterogeneous network to solve the data imbalance, domain diversity, negative migration, domain availability of possible parameter sharing strategies in MDL Efficient solution for scalability and large search space. By using a MobileNet-like search space, the generated model is also mobile-friendly. For tasks that are incompatible with existing search algorithms, researchers are continuing to extend MPNAS for multi-task learning and hope to use MPNAS to build unified multi-domain models.
The above is the detailed content of Multi-path, multi-domain, all-inclusive! Google AI releases multi-domain learning general model MDL. For more information, please follow other related articles on the PHP Chinese website!

 YouTube Channels to Learn SQL For Free - Analytics VidhyaApr 13, 2025 am 10:46 AM
YouTube Channels to Learn SQL For Free - Analytics VidhyaApr 13, 2025 am 10:46 AMIntroduction Mastering SQL (Structured Query Language) is crucial for individuals pursuing data management, data analysis, and database administration. If you are starting as a novice or are a seasoned pro seeking to improve,
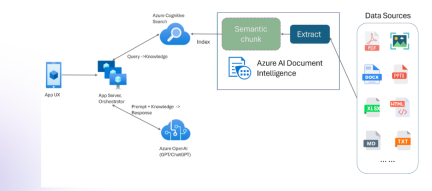 RAG with Multimodality and Azure Document IntelligenceApr 13, 2025 am 10:38 AM
RAG with Multimodality and Azure Document IntelligenceApr 13, 2025 am 10:38 AMIntroduction In the current-world that operates based on data, Relational AI Graphs (RAG) hold a lot of influence in industries by correlating data and mapping out relations. However, what if one could go a little further more
 Responsible AI in the Era of Generative AIApr 13, 2025 am 10:28 AM
Responsible AI in the Era of Generative AIApr 13, 2025 am 10:28 AMIntroduction We now live in the age of artificial intelligence, where everything around us is getting smarter by the day. State-of-the-art large language models (LLMs) and AI agents, are capable of performing complex tasks wit
 GPT-4o vs OpenAI o1: Is the New OpenAI Model Worth the Hype?Apr 13, 2025 am 10:18 AM
GPT-4o vs OpenAI o1: Is the New OpenAI Model Worth the Hype?Apr 13, 2025 am 10:18 AMIntroduction OpenAI has released its new model based on the much-anticipated “strawberry” architecture. This innovative model, known as o1, enhances reasoning capabilities, allowing it to think through problems mor
 Fine-tuning and Inference of Small Language ModelsApr 13, 2025 am 10:15 AM
Fine-tuning and Inference of Small Language ModelsApr 13, 2025 am 10:15 AMIntroduction Imagine you’re building a medical chatbot, and the massive, resource-hungry large language models (LLMs) seem like overkill for your needs. That’s where Small Language Models (SLMs) like Gemma come into play
 How to Access the OpenAI o1 API | Analytics VidhyaApr 13, 2025 am 10:14 AM
How to Access the OpenAI o1 API | Analytics VidhyaApr 13, 2025 am 10:14 AMIntroduction OpenAI’s o1 series models represent a significant leap in large language model (LLM) capabilities, particularly for complex reasoning tasks. These models engage in deep internal thought processes before resp
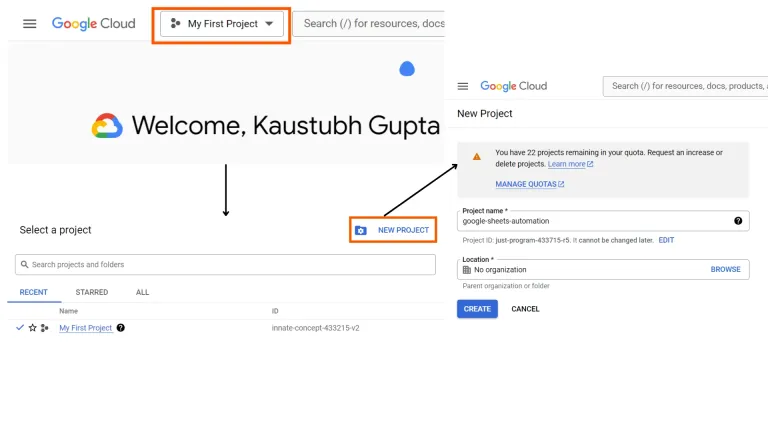 Google Sheets Automation using Python | Analytics VidhyaApr 13, 2025 am 10:01 AM
Google Sheets Automation using Python | Analytics VidhyaApr 13, 2025 am 10:01 AMGoogle Sheets is one of the most popular and widely used alternatives to Excel, offering a collaborative environment with features such as real-time editing, version control, and seamless integration with Google Suite, allowing u
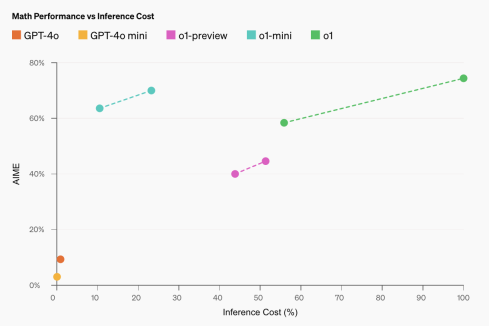 o1-mini: A Game-Changing Model for STEM and ReasoningApr 13, 2025 am 09:55 AM
o1-mini: A Game-Changing Model for STEM and ReasoningApr 13, 2025 am 09:55 AMOpenAI introduces o1-mini, a cost-efficient reasoning model with a focus on STEM subjects. The model demonstrates impressive performance in math and coding, closely resembling its predecessor, OpenAI o1, on various evaluation ben


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

SublimeText3 Mac version
God-level code editing software (SublimeText3)

Dreamweaver Mac version
Visual web development tools

