

 Technology peripheralsAIGPT-4's 32k input box is still not enough? Unlimiformer stretches the context length to infinite length
Technology peripheralsAIGPT-4's 32k input box is still not enough? Unlimiformer stretches the context length to infinite lengthGPT-4's 32k input box is still not enough? Unlimiformer stretches the context length to infinite length

Transformer is the most powerful seq2seq architecture today. Pretrained transformers typically have context windows of 512 (e.g. BERT) or 1024 (e.g. BART) tokens, which is long enough for many current text summarization datasets (XSum, CNN/DM).
But 16384 is not an upper limit on the length of context required to generate: tasks involving long narratives, such as book summaries (Krys-´cinski et al., 2021) or narrative question and answer (Kociskýet al. ., 2018), typically inputting more than 100,000 tokens. The challenge set generated from Wikipedia articles (Liu* et al., 2018) contains inputs of more than 500,000 tokens. Open-domain tasks in generative question answering can synthesize information from larger inputs, such as answering questions about the aggregated properties of articles by all living authors on Wikipedia. Figure 1 plots the sizes of several popular summarization and Q&A datasets against common context window lengths; the longest input is more than 34 times longer than Longformer’s context window.
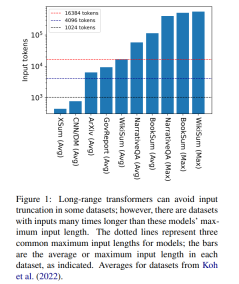
In the case of these very long inputs, the vanilla transformer cannot scale because the native attention mechanism has quadratic complexity. Long input transformers, while more efficient than standard transformers, still require significant computational resources that increase as the context window size increases. Furthermore, increasing the context window requires retraining the model from scratch with the new context window size, which is computationally and environmentally expensive.
In the article "Unlimiformer: Long-Range Transformers with Unlimited Length Input", researchers from Carnegie Mellon University introduced Unlimiformer. This is a retrieval-based approach that augments a pre-trained language model to accept infinite-length input at test time.

Paper link: https://arxiv.org/pdf/2305.01625v1.pdf
Unlimiformer can be injected into any existing encoder-decoder transformer, capable of handling input of unlimited length. Given a long input sequence, Unlimiformer can build a data store on the hidden states of all input tokens. The decoder's standard cross-attention mechanism is then able to query the data store and focus on the top k input tokens. The data store can be stored in GPU or CPU memory and can be queried sub-linearly.
Unlimiformer can be applied directly to a trained model and can improve existing checkpoints without any further training. The performance of Unlimiformer will be further improved after fine-tuning. This paper demonstrates that Unlimiformer can be applied to multiple base models, such as BART (Lewis et al., 2020a) or PRIMERA (Xiao et al., 2022), without adding weights and retraining. In various long-range seq2seq data sets, Unlimiformer is not only stronger than long-range Transformers such as Longformer (Beltagy et al., 2020b), SLED (Ivgi et al., 2022) and Memorizing transformers (Wu et al., 2021) on these data sets The performance is better, and this article also found that Unlimiform can be applied on top of the Longformer encoder model to make further improvements.
Unlimiformer technical principle
Since the size of the encoder context window is fixed, the maximum input length of the Transformer is limited. However, during decoding, different information may be relevant; furthermore, different attention heads may focus on different types of information (Clark et al., 2019). Therefore, a fixed context window may waste effort on tokens to which attention is less focused.
At each decoding step, each attention head in Unlimiformer selects a separate context window from all inputs. This is achieved by injecting the Unlimiformer lookup into the decoder: before entering the cross-attention module, the model performs a k-nearest neighbor (kNN) search in the external data store, selecting a set of each attention head in each decoder layer. token to participate.
coding
In order to encode input sequences longer than the context window length of the model, this article encodes the input overlapping blocks according to the method of Ivgi et al. (2022) (Ivgi et al., 2022), only The middle half of the output for each chunk is retained to ensure sufficient context before and after the encoding process. Finally, this article uses libraries such as Faiss (Johnson et al., 2019) to index encoded inputs in data stores (Johnson et al., 2019).
Retrieve enhanced cross-attention mechanism
In the standard cross-attention mechanism, the decoder of the transformer Focusing on the final hidden state of the encoder, the encoder usually truncates the input and encodes only the first k tokens in the input sequence.
This article does not only focus on the first k tokens of the input. For each cross attention head, it retrieves the first k hidden states of the longer input series and only focuses on the first k tokens. k. This allows the keyword to be retrieved from the entire input sequence rather than truncating the keyword. Our approach is also cheaper in terms of computation and GPU memory than processing all input tokens, while typically retaining over 99% of attention performance.
Figure 2 shows this article’s changes to the seq2seq transformer architecture. The complete input is block-encoded using the encoder and stored in a data store; the encoded latent state data store is then queried when decoding. The kNN search is non-parametric and can be injected into any pretrained seq2seq transformer, as detailed below.

Long document summary
Table 3 shows the results in the long text (4k and 16k token input) summary dataset.

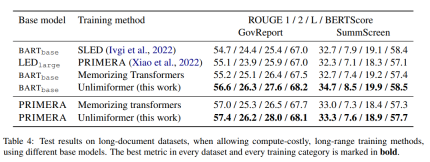
Among the training methods in Table 4, Unlimiformer can achieve the best in various indicators.
Book Summary
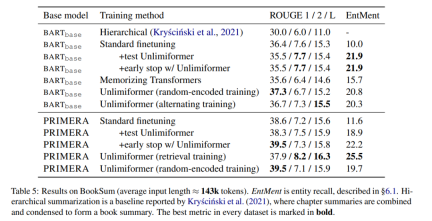
Table 5 Display Results on book abstracts. It can be seen that based on BARTbase and PRIMERA, applying Unlimiformer can achieve certain improvement results.
The above is the detailed content of GPT-4's 32k input box is still not enough? Unlimiformer stretches the context length to infinite length. For more information, please follow other related articles on the PHP Chinese website!

 Tesla's Robovan Was The Hidden Gem In 2024's Robotaxi TeaserApr 22, 2025 am 11:48 AM
Tesla's Robovan Was The Hidden Gem In 2024's Robotaxi TeaserApr 22, 2025 am 11:48 AMSince 2008, I've championed the shared-ride van—initially dubbed the "robotjitney," later the "vansit"—as the future of urban transportation. I foresee these vehicles as the 21st century's next-generation transit solution, surpas
 Sam's Club Bets On AI To Eliminate Receipt Checks And Enhance RetailApr 22, 2025 am 11:29 AM
Sam's Club Bets On AI To Eliminate Receipt Checks And Enhance RetailApr 22, 2025 am 11:29 AMRevolutionizing the Checkout Experience Sam's Club's innovative "Just Go" system builds on its existing AI-powered "Scan & Go" technology, allowing members to scan purchases via the Sam's Club app during their shopping trip.
 Nvidia's AI Omniverse Expands At GTC 2025Apr 22, 2025 am 11:28 AM
Nvidia's AI Omniverse Expands At GTC 2025Apr 22, 2025 am 11:28 AMNvidia's Enhanced Predictability and New Product Lineup at GTC 2025 Nvidia, a key player in AI infrastructure, is focusing on increased predictability for its clients. This involves consistent product delivery, meeting performance expectations, and
 Exploring the Capabilities of Google's Gemma 2 ModelsApr 22, 2025 am 11:26 AM
Exploring the Capabilities of Google's Gemma 2 ModelsApr 22, 2025 am 11:26 AMGoogle's Gemma 2: A Powerful, Efficient Language Model Google's Gemma family of language models, celebrated for efficiency and performance, has expanded with the arrival of Gemma 2. This latest release comprises two models: a 27-billion parameter ver
 The Next Wave of GenAI: Perspectives with Dr. Kirk Borne - Analytics VidhyaApr 22, 2025 am 11:21 AM
The Next Wave of GenAI: Perspectives with Dr. Kirk Borne - Analytics VidhyaApr 22, 2025 am 11:21 AMThis Leading with Data episode features Dr. Kirk Borne, a leading data scientist, astrophysicist, and TEDx speaker. A renowned expert in big data, AI, and machine learning, Dr. Borne offers invaluable insights into the current state and future traje
 AI For Runners And Athletes: We're Making Excellent ProgressApr 22, 2025 am 11:12 AM
AI For Runners And Athletes: We're Making Excellent ProgressApr 22, 2025 am 11:12 AMThere were some very insightful perspectives in this speech—background information about engineering that showed us why artificial intelligence is so good at supporting people’s physical exercise. I will outline a core idea from each contributor’s perspective to demonstrate three design aspects that are an important part of our exploration of the application of artificial intelligence in sports. Edge devices and raw personal data This idea about artificial intelligence actually contains two components—one related to where we place large language models and the other is related to the differences between our human language and the language that our vital signs “express” when measured in real time. Alexander Amini knows a lot about running and tennis, but he still
 Jamie Engstrom On Technology, Talent And Transformation At CaterpillarApr 22, 2025 am 11:10 AM
Jamie Engstrom On Technology, Talent And Transformation At CaterpillarApr 22, 2025 am 11:10 AMCaterpillar's Chief Information Officer and Senior Vice President of IT, Jamie Engstrom, leads a global team of over 2,200 IT professionals across 28 countries. With 26 years at Caterpillar, including four and a half years in her current role, Engst
 New Google Photos Update Makes Any Photo Pop With Ultra HDR QualityApr 22, 2025 am 11:09 AM
New Google Photos Update Makes Any Photo Pop With Ultra HDR QualityApr 22, 2025 am 11:09 AMGoogle Photos' New Ultra HDR Tool: A Quick Guide Enhance your photos with Google Photos' new Ultra HDR tool, transforming standard images into vibrant, high-dynamic-range masterpieces. Ideal for social media, this tool boosts the impact of any photo,


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

SublimeText3 English version
Recommended: Win version, supports code prompts!

Atom editor mac version download
The most popular open source editor

