


An in-depth analysis of Tesla's autonomous driving technology solutions

01 Perception: Building a real-time 4D autonomous driving scene
1. Tesla camera layout
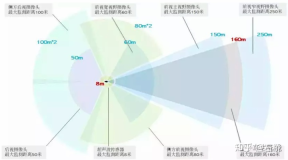
Tesla’s camera field of view can cover 360° around the car body. There is a 120° fisheye and telephoto lens in the forward direction to enhance observation. The layout is as shown in the picture above.
2. Tesla image data preprocessing
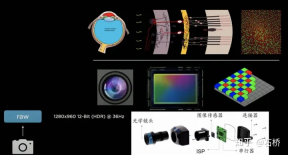
Tesla uses 36Hz 1280*960-12bit original image data, which has 4 more bits of information compared to only 8-bit ISP post-processing data, and the dynamic orientation has been expanded by 16 times. There are two reasons why Tesla handles this:
1) ISP performs automatic focus (AF), automatic exposure (AE), automatic White balance (AWB), dead pixel correction (DNS), high dynamic range imaging (HDR), color correction (CCM), etc., these meet the visualization needs of the human eye, but are not necessarily the needs of autonomous driving. Compared with rule-base ISP, neural network has more powerful processing capabilities and can better utilize the original information of images while avoiding data loss caused by ISP.
2) The existence of ISP is not conducive to high-speed transmission of data and affects the frame rate of images. It is much faster to process the original signal in network operations.
This method bypasses the traditional ISP-like expertise and directly drives the network from the back-end demand to learn stronger ISP capabilities, which can strengthen the system under low-light and low-visibility conditions. Beyond the perception of the human eye. Based on this principle, it should be a better way to use Lidar and radar raw data for network fitting.
3.backbone network: Designing Network Design Spaces
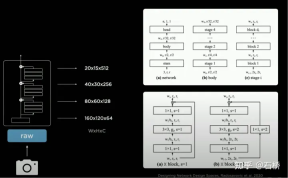
##RegNet
Tesla uses RegNet, which has a higher level of abstraction than ResNet and solves the NAS search design space (convolution, pooling and other modules: connection combination /Training Evaluation/Select Optimum) fixed and unable to create new modules, it can create a novel design space paradigm and explore more scenarios to adapt to the new "ResNet", thereby avoiding the need to specifically research and design neural network architecture. If a better BackBone comes out, this part can be replaced.
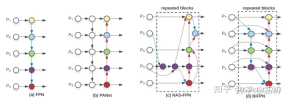
4. neckwork : EfficientDet: Scalable and Efficient Object Detection
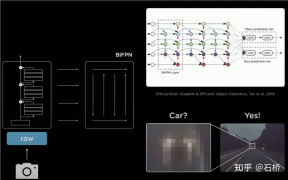
##BiFPN
- PANet is more accurate than FPN because: on the basis of FPN's top-down single path flow, an additional bottom-up path flow is added, and therefore Bringing in higher parameters and calculations;
- BiFPN removes nodes with only one input (the top layer and the bottom layer). Because the purpose of the network is to fuse features, it has no fusion ability. Just connect the nodes directly.
- BiFPN connects the input directly to the output node, integrating more features without increasing calculations.
- BiFPN stacks the basic structure in multiple layers and can integrate higher-dimensional features.
##5.BEV Fusion : FSD perception’s spatial understanding ability
 2D perception
2D perception
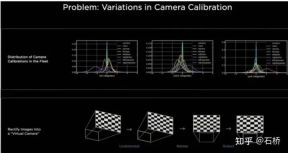
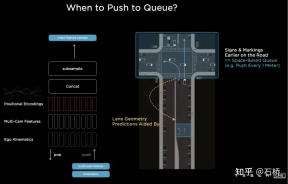
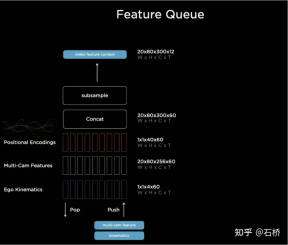
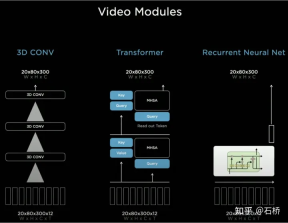
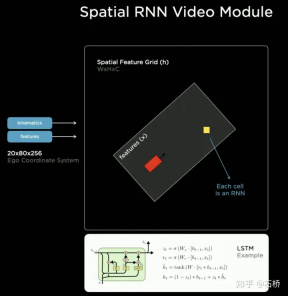
Before the emergence of BEV, the mainstream solutions for autonomous driving perception were all based on the 2D Image Space of the camera. However, the downstream applications of perception - decision-making and path planning are all performed in the 2D BEV Space where the vehicle is located. Perception and Barriers between regulation and control hinder the development of FSD. In order to eliminate this barrier, it is necessary to rearrange the perception from the 2D image space to the 2D self-vehicle reference system space, that is, the BEV space. Based on traditional technology: Will use IPM (Inverse Perspective Mapping) assuming that the ground is flat and use camera-auto The vehicle external reference converts the 2D Image Space into the 2D self-vehicle space, which is the BEV bird's-eye view space. There is an obvious flaw here: the plane assumption no longer holds true when facing ups and downs on the road. Multi-camera edge stitching problem Due to the The FOV is limited, so even if you use IPM to convert 2D Image Space to 2D BEV space, you still need to solve the BEV space splicing of multiple camera images. This actually requires a high-precision multi-camera calibration algorithm and an online real-time correction algorithm. In summary, what needs to be achieved is to map the multi-camera 2D image space features to the BEV space while solving the transformation overlap problem caused by calibration and non-planar assumptions. Tesla’s implementation of BEV Layer based on Transformer: BEV_FUSION First, each camera extracts multi-scale feature layers through the CNN backbone network and BiFPN. On the one hand, the multi-scale feature layer generates Transformer through the MLP layer. On the other hand, the Global Pooling operation is performed on the multi-scale Feature Map to obtain a global description vector (ie, the Context Summary in the figure). At the same time, the target output BEV space is rasterized, and then each The BEV raster is position-coded, and these position codes are concatenated (Concatenate) with the global description vector, and then a layer of MLP layer is used to obtain the Query required by the Transformer. In the Cross Attention operation, the scale of Query determines the output scale after the final BEV layer (that is, the scale of the BEV grid), and Key and Value are in the 2D image coordinate space respectively. According to the principle of Transformer, Query and Key are used to establish the influence weight of each BEV raster receiving the pixels of the 2D image plane, thereby establishing the association between the BEV and the input image, and then using these weights to weight the features obtained by the features under the image plane. Value, finally obtains the Feature Map under the BEV coordinate system, completing the mission of the BEV coordinate conversion layer. Later, based on the Feature Map under BEV, the mature sensing function heads can be used to directly sense in the BEV space. The perception results in the BEV space are unified with the coordinate system of the decision-making planning, so the perception and subsequent modules are closely linked through the BEV transformation. ##Calibration Through this method, in fact, the external parameters of the camera And changes in the ground geometry are internalized into the parameters by the neural network model during the training process. One problem here is that there are slight differences in the camera external parameters of different cars using the same set of model parameters. Karparthy added a method for Tesla to deal with the differences in external parameters on AI Day: they use the calibrated external parameters to compare each vehicle. The collected images are uniformly converted to the same set of virtual standard camera layout positions through de-distortion, rotation, and distortion restoration, thus eliminating the slight differences in the external parameters of different vehicle cameras. BEV’s method is a very effective multi-camera fusion framework. Through BEV’s solution, the size estimation and tracking of large targets in close proximity across multiple cameras that were originally difficult to correctly correlate have become much easier. It is accurate and stable. At the same time, this solution also makes the algorithm more robust to the short-term occlusion and loss of one or several cameras. In short, BEV solves the problem of image fusion and splicing of multiple cameras and increases robustness. Solve the multi-camera lane line and boundary fusion Obstacles become more stable (From the PPT point of view, Tesla’s initial plan should be the main A forward camera is used for perception and lane line prediction.) The use of BEV improves perception from the 2D Image Space dispersed by multiple cameras to the 2D BEV space, but the actual environment of autonomous driving is a 4D In the problem of space, even if elevation is not considered, the one missing dimension is time. Tesla trains the neural network by using video clips with temporal information instead of images, so that the perception model has short-term memory capabilities. The method to achieve this function is to introduce feature queues in the time dimension and spatial dimension into the neural network model. . Rule: every 27 milliseconds push queue or every 1 meter traveled will be cached in the video sequence together with motion information. Regarding how to fuse timing information, Tesla has tried three mainstream solutions: 3D convolution, Transformer and RNN. These three methods all need to combine the self-vehicle motion information with single-frame perception. Karparthy said that the self-vehicle motion information only uses four-dimensional information including speed and acceleration. This motion information can be obtained from the IMU and then combined with the BEV space. Feature Map (20x80x256) and Positional Encoding are combined (Concatenate) to form a 20x80x300x12-dimensional feature vector queue. The third dimension here consists of 256-dimensional visual features, 4-dimensional kinematic features (vx, vy, ax, ay) and 40-dimensional position encoding. (Positional Encoding), so 300 = 256 4 40, the last dimension is the 12-frame time/space dimension after downsampling. 3D Conv, Transformer, and RNN can all process sequence information. Each of the three has its own strengths and weaknesses in different tasks, but which solution is used most of the time? In fact, there is not much difference. However, on AI Day, Karpartthy also shared a simple, effective, and very interesting and explainable solution called Spatial RNN. Different from the above three methods, Spatial RNN is because RNN originally processes sequence information serially, and the order between frames is preserved. Therefore, BEV visual features can be directly fed into the RNN network without position encoding, so you can see here The input information only includes the 20x80x256 BEV visual Feature Map and the 1x1x4 self-vehicle motion information. Spatial features in CNN often refer to features in the width and height dimensions on the image plane. Here, Spatial in Spatial RNN refers to features similar to The BEV coordinates at a certain moment are two dimensions in a local coordinate system based on the reference. The RNN layer of LSTM is used for illustration here. The advantage of LSTM is its strong interpretability. It is more appropriate to understand it as an example. The characteristic of LSTM is that the Hidden State can retain the encoding of the state of the previous N moments with variable length (that is, short-term memory), and then the current moment can determine which part of the memory state is needed through the input and Hidden State. be used, which part needs to be forgotten, etc. In Spatial RNN, the Hidden State is a rectangular grid area larger than the BEV grid space, with a size of (WxHxC) (see the figure above, WxH is greater than the BEV size of 20x80). The self-vehicle kinematic information determines the front and rear BEV features respectively. Which part of the Hidden State grid is affected, so that the continuous BEV data will continuously update the large rectangular area of the Hidden State, and the position of each update is consistent with the movement of the self-vehicle. After continuous updates, a Hidden State Feature Map similar to a local map is formed as shown in the figure below. The use of sequential queues gives the neural network the ability to obtain continuous perception results between frames, which is similar to BEV After the combination, FSD has the ability to deal with blind spots and occlusions in the field of view, and selectively read and write local maps. Because of this ability to build real-time local maps, FSD can carry out urban navigation without relying on high-precision maps. Autopilot. It has not only 3D map capabilities, but also local 4D scene construction capabilities, which can be used for prediction and so on. After Occupancy came out, it was generally believed that the solution based on Spatial RNN was changed to the transformer solution mentioned above. The 2D bird’s-eye view of BEV is obvious There is still a gap between the 3D scenes faced by real autonomous driving, so there must be situations where BEV2D perception fails in certain scenarios. In 2021, Tesla will have the ability to build in depth, so it is only a matter of time from 2D to 3D. In 2022, it will bring the Occupancy Network, which is a further expansion of the BEV network in the height direction, bringing the BEV coordinate system down The Query generated by 2D raster position encoding is upgraded to the Query generated by 3D raster position encoding, and the BEV Feature is replaced by Occupancy Feature. At CVPR2022, Ashork gave the reason for using Occupancy Feature instead of image-based depth estimation: 1) Depth estimation is OK near, but the depth at a distance is inconsistent. The closer to the ground, the fewer depth value points (this is caused by the imaging principle of the image, which is 20m away). The vertical distance represented by pixels may exceed 30cm), and the data is difficult to use in subsequent planning processes. 2) The deep network is built based on regression and is difficult to predict through occlusion, so it is difficult to predict on the boundary and may transition smoothly from the vehicle to the background. The advantages of using Occupancy are as follows: Occupancy advantages 1) Unified voxels are generated in the BEV space, and the occupancy probability of any voxel can be predicted 2) Videos from all cameras are obtained flow, and is unified (there is no lidar-camera fusion problem, the dimension of information is higher than lidar) 3) Able to predict the status of occluded objects in real time (the dynamics of Occupancy The description ability is the transition from 3D to 4D) 4) The corresponding semantic category can be generated for each voxel (the image recognition ability is much stronger than lidar) Can handle moving objects even without recognizing categories 5) The motion state of each voxel can be predicted and random motion can be modeled 6) The resolution of each position can be adjusted (that is, With BEV space zoom capability) 7) Thanks to Tesla’s hardware, Occupancy has efficient storage and computing advantages ##8 ) The calculation can be completed within 10ms, and the processing frequency can be very high (the image output capability of 36Hz is already stronger than the lidar frequency of 10Hz) The advantages of the Occupancy solution compared to the bounding box perception solution The reason is: can describe unknown objects that do not have a fixed bounding box, can change shapes at will, and move at will. It improves the description granularity of obstacles from box to voxel granularity, which can solve the problem of perception. Many long-tail problems. Let’s take a look at the overall plan of Occupancy: 




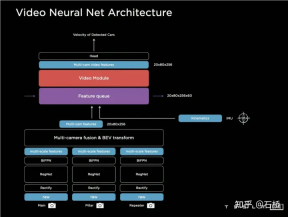
6.Video Neural Net Architecture: Spatio-temporal sequence Feature construction
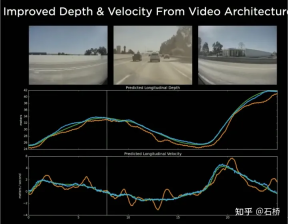
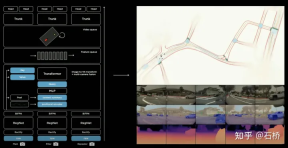
7.Occupancy Network: BEV moves from 2D to 3D

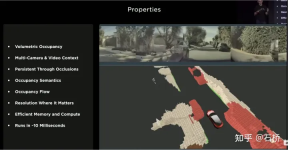

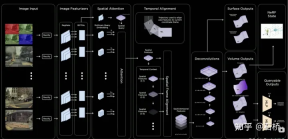
##Occupancy Network
1) Image Input: Input original image information, expanding the data dimension and dynamic range2) Image Featurers: RegNet BiFPN extracts multi-scale image features
3) Spatial Atention: Attention-based multi-camera fusion of 2D image features through spatial query with 3D spatial position
Implementation plan 1: Project the 3D spatial query onto the 2D feature map according to the internal and external parameters of each camera, and extract the features of the corresponding position.
Implementation plan 2: Use positional embedding to perform implicit mapping, that is, add reasonable positional embedding to each position of the 2D feature map, such as camera internal and external parameters, pixel coordinates, etc. Then let the model learn the correspondence between 2D and 3D features by itself
4) Temporal Alignment: Use trajectory information to splice the 3D Occupancy Features of each frame in time sequence in the spatial Channel dimension. There is a weight decay over time, and the combined features will enter the Deconvolutions module to improve the resolution
5) Volume Outputs: Output the occupancy and occupancy flow of fixed-size rasters
6) Queryable Outputs: An implicit queryable MLP decoder is designed to input any coordinate value (x, y, z) to obtain higher resolution continuous voxel semantics. Occupancy rate and occupancy flow information break the limitations of model resolution
7) Generate drivable area pavement with three-dimensional geometry and semantics, which is beneficial to control on slopes and curved roads.

The ground is consistent with Occupancy
8) NeRF state: Nerf constructs the geometric structure of the scene, can generate images from any perspective, and can restore high-resolution real scenes.If it can be upgraded or replaced with Nerf, it will have the ability to restore real scenes, and this scene restoration capability will be past-present-future. It should be a great complement and improvement to the 4D scene autonomous driving pursued by Tesla’s technical solutions.
8.FSD Lanes Neural Network: Predicting the topological connection relationship of lanes
It is not enough to segment and identify lane lines, you also need Reasoning to obtain the topological connection relationship between lanes can be used for trajectory planning.
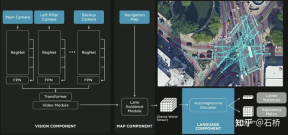
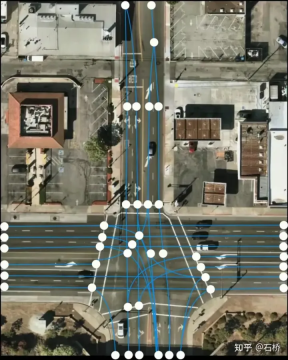
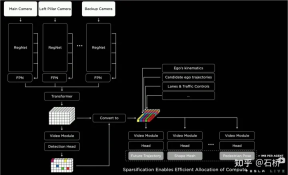
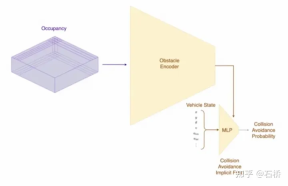
FSD lane line topological relationship awareness 1) Lane Guidance Module: Uses the geometric & topological relationship of the road in the navigation map, lane level, quantity, width, attribute information, integrates this information with the Occupancy feature to encode and generate Dense World Tensor. To the module for establishing topological relationships, the dense features of the video stream are parsed through the sequence generation paradigm to obtain sparse road topology information (lane node lane segment and connection relationship adjacent). 2) Language Component: Lane-related information includes lane node positions, attributes (starting point, intermediate point, end point, etc.), bifurcation points, converging points, and lane spline geometry The parameters are encoded into a code similar to the word token in the language model, and then processed using timing processing methods. The specific process is as follows: language of lanes process language of lanes Ultimately, language of lanes represents the topological connection relationship in the graph. Obstacle Perception FSD's Object Perception is a 2-Step method. In the first stage, the position of the obstacle in the 3D space is identified from Occupancy. In the second stage, Concat the tensors of these 3D objects to encode some kinematic information (such as self-vehicle motion, target driving lane lines, traffic lights, traffic signals, etc.) and then access the heads such as trajectory prediction, object modeling, and pedestrian pose prediction. Focusing complex sensing heads on a limited ROI area reduces processing delays. As you can see from the above figure, there are two steps of video module, which serve the prediction of the own vehicle and other vehicles respectively. Leave a question here: What is the difference between the two video modules in the picture above? Will there be any problems with efficiency? 02 Decision Planning The decision-making and planning scenario of unprotected left turn at the intersection The decision-making and planning of the above scenario The difficulty lies in: When the vehicle performs an unprotected left turn through the intersection scene, it needs to interact with pedestrians and normal straight-moving vehicles, and understand the interrelationship between multiple parties. The interaction decision with the former directly affects the interaction strategy with the latter. The final solution chosen here is: try not to interfere with the movement of other traffic participants. Decision-making and planning process Tesla uses "interactive search" to achieve this goal. A series of possible motion trajectories are searched in parallel, and the corresponding state space includes the vehicle, obstacles, drivable areas, lanes, traffic lights, etc. The solution space uses a set of target motion candidate trajectories, which branch after participating in interactive decision-making with other traffic, and then proceed with progressive decision-making and planning, and finally select the optimal trajectory. The process is as shown in the figure above: 1) Obtain the goal point or its probability distribution (big data trajectory) a priori based on road topology or human driving data 2) Generate candidate trajectories based on the goal point ( Optimization algorithm neural network) 3) Rollout and interactive decision-making along the candidate trajectory, re-plan the path, evaluate the risk and score of each path, prioritize the search for the best path and know the goal point The optimization expression of the entire decision planning: The optimization expression of the decision planning Lightweight planning trajectory query network Tesla New decision-making constraints are continuously added in an incremental manner, and the optimal solution under fewer constraints is used as the initial value to continue to solve more complex optimization problems, and finally the optimal solution is obtained. However, due to the existence of many possible branches, the entire decision-making and planning process must be very efficient. Each decision-making planning of the planner based on the traditional optimization algorithm takes 1 to 5ms, which is obviously not safe enough when there are high-density traffic participants. . The Neural Planner used by Tesla is a lightweight network. The query planning trajectory is trained using the driving data of human drivers in the Tesla fleet and the true value of the global optimal path planned under offline conditions without time constraints. , each decision-making planning only takes 100us. Planning decision evaluation How many queries are queried after each decision Each candidate trajectory needs to be evaluated. The evaluation is based on specifications such as collision check, comfort analysis, takeover possibility, similarity to people, etc. This helps to prune the search branch and avoid the entire decision tree from being too large. It can also The computing power is concentrated on the most likely branch. Tesla emphasized that this solution is also applicable to occlusion scenes. During the planning process, the motion status of the occluded object will be considered and planning will be performed by adding "ghosts". ghost occlusion scene also shared the network process and corresponding planning of collision avoidance at CVPR The process will not be described in detail. ##Collision Avoidance Network
Phase 1 (2018): There is only purely manual 2-dimensional image annotation, which is very inefficient Phase 2 (2019): There will be 3D labels at the beginning, but it is a single manual process Phase 3 (2020): Use BEV space for labeling and reprojection The accuracy is significantly reduced Phase 4 (2021): Multiple reconstructions are used for annotation, and accuracy, efficiency, and topological relationships have reached an extremely high level Tesla’s automatic labeling system can replace 5 million hours of manual work. Manual inspection and leak repair only require a very small part ( The process of this multi-travel trajectory reconstruction solution is as follows: (similar to an offline semantic slam system)
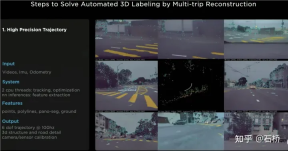
Step 1: VIO generates high-precision trajectory. Feed the video stream, IMU, and odometry to the neural network, infer and extract points, lines, ground, and segmentation features, and then use multi-camera VIO for tracking and optimization in the BEV space to output 100Hz 6dof trajectories and 3dof structures and roads. , and can also output the calibration value of the camera. The accuracy of the reconstructed trajectory is 1.3cm/m, 0.45 rad/m, which is not very high. All FSDs can run this process to obtain the preprocessed trajectory and structure information of a certain trip. (Watching the video, I feel that vio only explicitly uses point features, and may implicitly use line and surface features.)
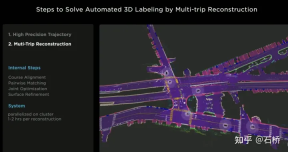
#Step 2: Multi-trip trajectory reconstruction. Multiple reconstructed data from different vehicles are grouped for rough alignment -> feature matching -> joint optimization -> road surface refinement, and then manual participation is involved to finally verify and confirm the labeling results. Here, a road surface optimization was also performed after joint optimization. It is speculated that the error of visual reconstruction is relatively large. After global optimization, there is a layered overlap problem on local roads. In order to eliminate the error of this part of global optimization misallocation, road surface optimization was added. From an algorithmic logic point of view, global optimization followed by local optimization is a must, because the requirement of autonomous driving is to be able to drive everywhere. The entire process is parallelized on the cluster.
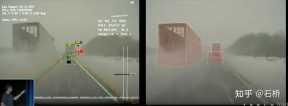
Step 3: Automatically label new trajectory data. On the pre-built map, the same reconstruction process as multiple trajectory reconstructions is performed on the new driving trajectory data, so that the aligned new trajectory data can automatically obtain semantic annotations from the pre-built map. This is actually a process of relocation to obtain semantic tags. This automatic labeling can actually only automatically label static objects, such as lane lines, road boundaries, etc. Through the perception model, semantic categories such as lane lines can actually be obtained. However, there will be integrity and misrecognition problems in harsh scenarios. These problems can be solved through this automatic annotation. However, the disadvantage is that it may not be suitable for dynamic obstacles, such as moving vehicles, pedestrians, etc. The following are usage scenarios: Automatic labeling usage scenarios Tes Many of the images shown by La have a characteristic: there is blur or stain occlusion, but it does not seriously affect the perception result. In normal use, the vehicle's camera lens can easily get dirty, but with this automatic labeling, Tesla's perception will be very robust and the maintenance cost of the camera will be reduced. Automatic labeling does not apply to dynamic vehicles Review of 2021 AI Day shows that the above reconstruction constructs a static world, but not just lane lines and lane lines, but also vehicles and buildings. ##3D Reconstruction ##Reconstruct the static world and label it After the BEV space annotation is completed, the annotation will be mapped to the images of multiple cameras, so that one annotation in the 4D space can be applied to 2D multiple frames. Regarding scene reconstruction, the current reconstruction capability and accuracy may still not meet the expectations of Tesla engineers. Their ultimate goal is to truly restore and reconstruct all the scenes that Tesla cars have driven. Scenes, and the ability to truly change the conditions of these scenes to generate new real scenes is the ultimate goal.
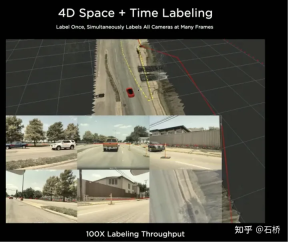
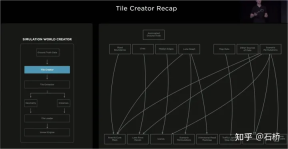
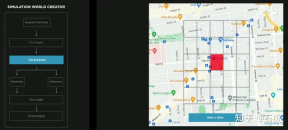
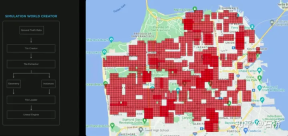
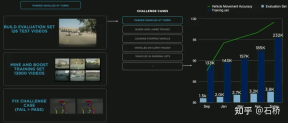
##Reconstruct the real world 04 Scene simulation: Create autonomous driving scenarios based on real road information Scene Simulation ##Simulation can obtain absolutely correct label The real scene constructed based on reconstruction is limited by data, algorithms, etc., which is currently difficult to implement on a large scale and takes a long time. For example, the simulation of a real intersection in the picture above takes 2 weeks. However, the implementation of autonomous driving relies on training and testing in different scenarios, so Tesla has built a simulation system to simulate autonomous driving scenarios. This system cannot truly simulate real-life scenarios, but the advantage is that it is 1,000 times faster than the real common reconstruction solutions mentioned above. It can provide data that is difficult to obtain or label in reality, and is still very meaningful for the training of autonomous driving. The architecture of the simulation The architecture of this simulator is as above Figure, the following steps are required during the scene creation process: Step 1: Spread the road in the simulation world, use the boundary label to generate the entity road mesh, and re-associate it with the road topology relationship . Step 2: Project the lane lines and geometric description elements on the road surface onto the lane segments to construct lane details Step 3 Step: Generate a central lane separation area in the middle boundary area of the road, and randomly generate plants and traffic signs to fill it; outside the road boundary, use a random heuristic method to generate a series of buildings, trees, traffic signs, etc. Step 4: Get the location of the traffic light or stop sign from the map, you can also get the number of lanes, road name, etc. Step 5: Use the lane map to get the location of the lane Topological relationships, generate driving directions (left and right turn markings) and auxiliary markers Step 6: Use the lane map itself to determine lane adjacency relationships and other useful information Step 7: Generate random traffic flow combinations based on lane relationships In the above process, the simulation parameters can be modified to generate changes based on a set of lane navigation map true values. Generate multiple combination scenarios. Moreover, according to the needs of training, some attributes of the true value can even be modified to create new scenarios to achieve the purpose of training. Data is divided into Tile storage A world built based on Tile granularity #The simulation constructed above is based on real road information, so many practical problems can be solved with the help of simulation . For example: autonomous driving functions can be tested in a simulated Los Angeles road environment. (The above storage method is used in simulation mapping, storage, and loading) Autonomous driving in simulation scenarios Feeling: What kind of map information is irreplaceable for autonomous driving? You can find some answers from this simulation construction process. Data closed-loop process The data engine mines data misjudged by the model from the shadow mode, recalls it and uses automatic annotation tools for label correction, and then adds it to the training and test sets, which can be continuously optimized network. This process is the key node of the data closed loop and will continue to generate corner case sample data. Data Mining for Curved Parking The picture above shows the improvement of the model through data mining for curved parking In this case, as data is continuously added to the training, the accuracy index continues to improve. 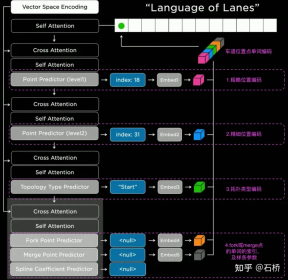
9. Object Perception: Perception and prediction of other traffic participants
1. Complex scenarios: Interaction planning with high-frequency and diverse traffic participants
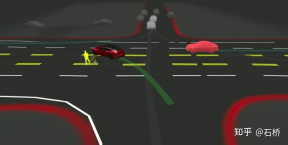
2. Traditional optimization method: [Joint multi-object trajectory planning]: Multi-object MPC

3. Interactive tree search: parallel path planning and evaluation pruning
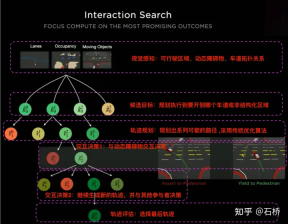


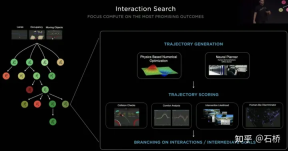



#03 Scene reconstruction & automatic annotation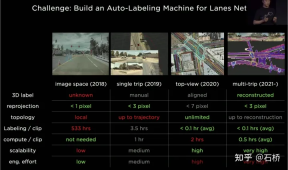




 ##Restore the real world
##Restore the real world


05 Data engine: Mining corner case data

The above is the detailed content of An in-depth analysis of Tesla's autonomous driving technology solutions. For more information, please follow other related articles on the PHP Chinese website!

 You Must Build Workplace AI Behind A Veil Of IgnoranceApr 29, 2025 am 11:15 AM
You Must Build Workplace AI Behind A Veil Of IgnoranceApr 29, 2025 am 11:15 AMIn John Rawls' seminal 1971 book The Theory of Justice, he proposed a thought experiment that we should take as the core of today's AI design and use decision-making: the veil of ignorance. This philosophy provides a simple tool for understanding equity and also provides a blueprint for leaders to use this understanding to design and implement AI equitably. Imagine that you are making rules for a new society. But there is a premise: you don’t know in advance what role you will play in this society. You may end up being rich or poor, healthy or disabled, belonging to a majority or marginal minority. Operating under this "veil of ignorance" prevents rule makers from making decisions that benefit themselves. On the contrary, people will be more motivated to formulate public
 Decisions, Decisions… Next Steps For Practical Applied AIApr 29, 2025 am 11:14 AM
Decisions, Decisions… Next Steps For Practical Applied AIApr 29, 2025 am 11:14 AMNumerous companies specialize in robotic process automation (RPA), offering bots to automate repetitive tasks—UiPath, Automation Anywhere, Blue Prism, and others. Meanwhile, process mining, orchestration, and intelligent document processing speciali
 The Agents Are Coming – More On What We Will Do Next To AI PartnersApr 29, 2025 am 11:13 AM
The Agents Are Coming – More On What We Will Do Next To AI PartnersApr 29, 2025 am 11:13 AMThe future of AI is moving beyond simple word prediction and conversational simulation; AI agents are emerging, capable of independent action and task completion. This shift is already evident in tools like Anthropic's Claude. AI Agents: Research a
 Why Empathy Is More Important Than Control For Leaders In An AI-Driven FutureApr 29, 2025 am 11:12 AM
Why Empathy Is More Important Than Control For Leaders In An AI-Driven FutureApr 29, 2025 am 11:12 AMRapid technological advancements necessitate a forward-looking perspective on the future of work. What happens when AI transcends mere productivity enhancement and begins shaping our societal structures? Topher McDougal's upcoming book, Gaia Wakes:
 AI For Product Classification: Can Machines Master Tax Law?Apr 29, 2025 am 11:11 AM
AI For Product Classification: Can Machines Master Tax Law?Apr 29, 2025 am 11:11 AMProduct classification, often involving complex codes like "HS 8471.30" from systems such as the Harmonized System (HS), is crucial for international trade and domestic sales. These codes ensure correct tax application, impacting every inv
 Could Data Center Demand Spark A Climate Tech Rebound?Apr 29, 2025 am 11:10 AM
Could Data Center Demand Spark A Climate Tech Rebound?Apr 29, 2025 am 11:10 AMThe future of energy consumption in data centers and climate technology investment This article explores the surge in energy consumption in AI-driven data centers and its impact on climate change, and analyzes innovative solutions and policy recommendations to address this challenge. Challenges of energy demand: Large and ultra-large-scale data centers consume huge power, comparable to the sum of hundreds of thousands of ordinary North American families, and emerging AI ultra-large-scale centers consume dozens of times more power than this. In the first eight months of 2024, Microsoft, Meta, Google and Amazon have invested approximately US$125 billion in the construction and operation of AI data centers (JP Morgan, 2024) (Table 1). Growing energy demand is both a challenge and an opportunity. According to Canary Media, the looming electricity
 AI And Hollywood's Next Golden AgeApr 29, 2025 am 11:09 AM
AI And Hollywood's Next Golden AgeApr 29, 2025 am 11:09 AMGenerative AI is revolutionizing film and television production. Luma's Ray 2 model, as well as Runway's Gen-4, OpenAI's Sora, Google's Veo and other new models, are improving the quality of generated videos at an unprecedented speed. These models can easily create complex special effects and realistic scenes, even short video clips and camera-perceived motion effects have been achieved. While the manipulation and consistency of these tools still need to be improved, the speed of progress is amazing. Generative video is becoming an independent medium. Some models are good at animation production, while others are good at live-action images. It is worth noting that Adobe's Firefly and Moonvalley's Ma
 Is ChatGPT Slowly Becoming AI's Biggest Yes-Man?Apr 29, 2025 am 11:08 AM
Is ChatGPT Slowly Becoming AI's Biggest Yes-Man?Apr 29, 2025 am 11:08 AMChatGPT user experience declines: is it a model degradation or user expectations? Recently, a large number of ChatGPT paid users have complained about their performance degradation, which has attracted widespread attention. Users reported slower responses to models, shorter answers, lack of help, and even more hallucinations. Some users expressed dissatisfaction on social media, pointing out that ChatGPT has become “too flattering” and tends to verify user views rather than provide critical feedback. This not only affects the user experience, but also brings actual losses to corporate customers, such as reduced productivity and waste of computing resources. Evidence of performance degradation Many users have reported significant degradation in ChatGPT performance, especially in older models such as GPT-4 (which will soon be discontinued from service at the end of this month). this


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Dreamweaver CS6
Visual web development tools

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

Atom editor mac version download
The most popular open source editor

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

