



1. Arithmetic expression evaluation
To parse this type of text, another specific grammar rule is required. We introduce here the grammatical rules Backus Normal Form (BNF) and Extended Backus Normal Form (EBNF) that can represent context free grammar. From as small as an arithmetic expression to as large as almost all programming languages, they are defined using context-free grammars.
For simple arithmetic operation expressions, it is assumed that we have used word segmentation technology to convert it into an input tokens stream, such as NUM NUM*NUM (see the previous blog post for word segmentation method).
On this basis, we define the BNF rule as follows:
expr ::= expr + term
| expr - term
| term
term ::= term * factor
| term / factor
| factor
factor ::= (expr)
| NUMOf course, this method is not concise and clear enough. What we actually use is the EBNF form:
expr ::= term { (+|-) term }*
term ::= factor { (*|/) factor }*
factor ::= (expr)
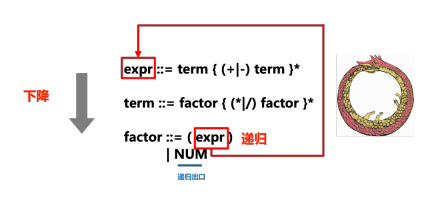
| NUM## Each rule of #BNF and EBNF (an expression in the form of ::=) can be regarded as a substitution, that is, the symbol on the left can be replaced by the symbol on the right. We try to use BNF/EBNF to match the input text with grammar rules during the parsing process to complete various substitutions and expansions. In EBNF, rules placed within {...}* are optional, and * indicates that they can be repeated zero or more times (analogous to regular expressions). The following figure vividly shows the relationship between the "recursion" and "descent" parts of the recursive descent parser (parser) and ENBF:
class ExpressionEvaluator():
...
def expr(self):
...
def term(self):
...
def factor(self):
...In the process of calling the method corresponding to a rule, if we find the next symbol If we need to use another rule to match, we will "descend" to another rule method (such as calling term in expr and factor in term), which is the "descending" part of the recursive descent. Sometimes methods that are already executing are called (for example, term is called in expr, factor is called in term, and expr is called in factor, which is equivalent to an ouroboros), which is recursive descent. The "recursive" part. For the repeated parts that appear in the grammar (such as expr ::= term { ( |-) term }*), we implement it through a while loop.
import re
import collections
# 定义匹配token的模式
NUM = r'(?P<NUM>\d+)' # \d表示匹配数字,+表示任意长度
PLUS = r'(?P<PLUS>\+)' # 注意转义
MINUS = r'(?P<MINUS>-)'
TIMES = r'(?P<TIMES>\*)' # 注意转义
DIVIDE = r'(?P<DIVIDE>/)'
LPAREN = r'(?P<LPAREN>\()' # 注意转义
RPAREN = r'(?P<RPAREN>\))' # 注意转义
WS = r'(?P<WS>\s+)' # 别忘记空格,\s表示空格,+表示任意长度
master_pat = re.compile(
'|'.join([NUM, PLUS, MINUS, TIMES, DIVIDE, LPAREN, RPAREN, WS]))
# Tokenizer
Token = collections.namedtuple('Token', ['type', 'value'])
def generate_tokens(text):
scanner = master_pat.scanner(text)
for m in iter(scanner.match, None):
tok = Token(m.lastgroup, m.group())
if tok.type != 'WS': # 过滤掉空格符
yield tokThe following is the specific implementation of the expression evaluator: class ExpressionEvaluator():
""" 递归下降的Parser实现,每个语法规则都对应一个方法,
使用 ._accept()方法来测试并接受当前处理的token,不匹配不报错,
使用 ._except()方法来测试当前处理的token,并在不匹配的时候抛出语法错误
"""
def parse(self, text):
""" 对外调用的接口 """
self.tokens = generate_tokens(text)
self.tok, self.next_tok = None, None # 已匹配的最后一个token,下一个即将匹配的token
self._next() # 转到下一个token
return self.expr() # 开始递归
def _next(self):
""" 转到下一个token """
self.tok, self.next_tok = self.next_tok, next(self.tokens, None)
def _accept(self, tok_type):
""" 如果下一个token与tok_type匹配,则转到下一个token """
if self.next_tok and self.next_tok.type == tok_type:
self._next()
return True
else:
return False
def _except(self, tok_type):
""" 检查是否匹配,如果不匹配则抛出异常 """
if not self._accept(tok_type):
raise SyntaxError("Excepted"+tok_type)
# 接下来是语法规则,每个语法规则对应一个方法
def expr(self):
""" 对应规则: expression ::= term { ('+'|'-') term }* """
exprval = self.term() # 取第一项
while self._accept("PLUS") or self._accept("DIVIDE"): # 如果下一项是"+"或"-"
op = self.tok.type
# 再取下一项,即运算符右值
right = self.term()
if op == "PLUS":
exprval += right
elif op == "MINUS":
exprval -= right
return exprval
def term(self):
""" 对应规则: term ::= factor { ('*'|'/') factor }* """
termval = self.factor() # 取第一项
while self._accept("TIMES") or self._accept("DIVIDE"): # 如果下一项是"+"或"-"
op = self.tok.type
# 再取下一项,即运算符右值
right = self.factor()
if op == "TIMES":
termval *= right
elif op == "DIVIDE":
termval /= right
return termval
def factor(self):
""" 对应规则: factor ::= NUM | ( expr ) """
if self._accept("NUM"): # 递归出口
return int(self.tok.value)
elif self._accept("LPAREN"):
exprval = self.expr() # 继续递归下去求表达式值
self._except("RPAREN") # 别忘记检查是否有右括号,没有则抛出异常
return exprval
else:
raise SyntaxError("Expected NUMBER or LPAREN") We enter the following expression for testing: e = ExpressionEvaluator()
print(e.parse("2"))
print(e.parse("2+3"))
print(e.parse("2+3*4"))
print(e.parse("2+(3+4)*5"))The evaluation results are as follows:
2If the text we enter does not comply with the grammatical rules:5
14
37
print(e.parse("2 + (3 + * 4)")), a SyntaxError exception will be thrown: Expected NUMBER or LPAREN. In summary, it can be seen that our expression evaluation algorithm runs correctly.
class ExpressionTreeBuilder(ExpressionEvaluator):
def expr(self):
""" 对应规则: expression ::= term { ('+'|'-') term }* """
exprval = self.term() # 取第一项
while self._accept("PLUS") or self._accept("DIVIDE"): # 如果下一项是"+"或"-"
op = self.tok.type
# 再取下一项,即运算符右值
right = self.term()
if op == "PLUS":
exprval = ('+', exprval, right)
elif op == "MINUS":
exprval -= ('-', exprval, right)
return exprval
def term(self):
""" 对应规则: term ::= factor { ('*'|'/') factor }* """
termval = self.factor() # 取第一项
while self._accept("TIMES") or self._accept("DIVIDE"): # 如果下一项是"+"或"-"
op = self.tok.type
# 再取下一项,即运算符右值
right = self.factor()
if op == "TIMES":
termval = ('*', termval, right)
elif op == "DIVIDE":
termval = ('/', termval, right)
return termval
def factor(self):
""" 对应规则: factor ::= NUM | ( expr ) """
if self._accept("NUM"): # 递归出口
return int(self.tok.value) # 字符串转整形
elif self._accept("LPAREN"):
exprval = self.expr() # 继续递归下去求表达式值
self._except("RPAREN") # 别忘记检查是否有右括号,没有则抛出异常
return exprval
else:
raise SyntaxError("Expected NUMBER or LPAREN")Enter the following expression to test: print(e.parse("2+3"))
print(e.parse("2+3*4"))
print(e.parse("2+(3+4)*5"))
print(e.parse('2+3+4'))The following is the generated result:
(' ' , 2, 3)You can see that the expression tree is generated correctly. Our example above is very simple, but the recursive descent parser can also be used to implement quite complex parsers. For example, Python code is parsed through a recursive descent parser. If you are interested in this, you can check the(' ', 2, ('*', 3, 4))
(' ', 2, ('*', (' ', 3, 4), 5))
(' ', (' ', 2, 3), 4)
Grammar file in the Python source code to find out. However, as we will see below, writing a parser yourself comes with various pitfalls and challenges.
left recursion form cannot be solved by the recursive descent parser. The so-called left recursion means that the leftmost symbol on the right side of the rule expression is the rule header. For example, for the following rules:
items ::= items ',' item
| item To complete the analysis, you may define the following method: def items(self):
itemsval = self.items() # 取第一项,然而此处会无穷递归!
if itemsval and self._accept(','):
itemsval.append(self.item())
else:
itemsval = [self.item()] This will In the first line, self.items() is called infinitely, resulting in an infinite recursion error.
expr ::= factor { ('+'|'-'|'*'|'/') factor }*
factor ::= '(' expr ')'
| NUMPYTHON Copy full screenThis syntax can be technically implemented, but the calculation order convention is not followed, resulting in "3 4* 5" evaluates to 35 instead of 23 as expected. Therefore, separate expr and term rules are required to ensure the correctness of the calculation results. The above is the detailed content of How to implement recursive descent Parser in Python. For more information, please follow other related articles on the PHP Chinese website!

 Python vs. C : Understanding the Key DifferencesApr 21, 2025 am 12:18 AM
Python vs. C : Understanding the Key DifferencesApr 21, 2025 am 12:18 AMPython and C each have their own advantages, and the choice should be based on project requirements. 1) Python is suitable for rapid development and data processing due to its concise syntax and dynamic typing. 2)C is suitable for high performance and system programming due to its static typing and manual memory management.
 Python vs. C : Which Language to Choose for Your Project?Apr 21, 2025 am 12:17 AM
Python vs. C : Which Language to Choose for Your Project?Apr 21, 2025 am 12:17 AMChoosing Python or C depends on project requirements: 1) If you need rapid development, data processing and prototype design, choose Python; 2) If you need high performance, low latency and close hardware control, choose C.
 Reaching Your Python Goals: The Power of 2 Hours DailyApr 20, 2025 am 12:21 AM
Reaching Your Python Goals: The Power of 2 Hours DailyApr 20, 2025 am 12:21 AMBy investing 2 hours of Python learning every day, you can effectively improve your programming skills. 1. Learn new knowledge: read documents or watch tutorials. 2. Practice: Write code and complete exercises. 3. Review: Consolidate the content you have learned. 4. Project practice: Apply what you have learned in actual projects. Such a structured learning plan can help you systematically master Python and achieve career goals.
 Maximizing 2 Hours: Effective Python Learning StrategiesApr 20, 2025 am 12:20 AM
Maximizing 2 Hours: Effective Python Learning StrategiesApr 20, 2025 am 12:20 AMMethods to learn Python efficiently within two hours include: 1. Review the basic knowledge and ensure that you are familiar with Python installation and basic syntax; 2. Understand the core concepts of Python, such as variables, lists, functions, etc.; 3. Master basic and advanced usage by using examples; 4. Learn common errors and debugging techniques; 5. Apply performance optimization and best practices, such as using list comprehensions and following the PEP8 style guide.
 Choosing Between Python and C : The Right Language for YouApr 20, 2025 am 12:20 AM
Choosing Between Python and C : The Right Language for YouApr 20, 2025 am 12:20 AMPython is suitable for beginners and data science, and C is suitable for system programming and game development. 1. Python is simple and easy to use, suitable for data science and web development. 2.C provides high performance and control, suitable for game development and system programming. The choice should be based on project needs and personal interests.
 Python vs. C : A Comparative Analysis of Programming LanguagesApr 20, 2025 am 12:14 AM
Python vs. C : A Comparative Analysis of Programming LanguagesApr 20, 2025 am 12:14 AMPython is more suitable for data science and rapid development, while C is more suitable for high performance and system programming. 1. Python syntax is concise and easy to learn, suitable for data processing and scientific computing. 2.C has complex syntax but excellent performance and is often used in game development and system programming.
 2 Hours a Day: The Potential of Python LearningApr 20, 2025 am 12:14 AM
2 Hours a Day: The Potential of Python LearningApr 20, 2025 am 12:14 AMIt is feasible to invest two hours a day to learn Python. 1. Learn new knowledge: Learn new concepts in one hour, such as lists and dictionaries. 2. Practice and exercises: Use one hour to perform programming exercises, such as writing small programs. Through reasonable planning and perseverance, you can master the core concepts of Python in a short time.
 Python vs. C : Learning Curves and Ease of UseApr 19, 2025 am 12:20 AM
Python vs. C : Learning Curves and Ease of UseApr 19, 2025 am 12:20 AMPython is easier to learn and use, while C is more powerful but complex. 1. Python syntax is concise and suitable for beginners. Dynamic typing and automatic memory management make it easy to use, but may cause runtime errors. 2.C provides low-level control and advanced features, suitable for high-performance applications, but has a high learning threshold and requires manual memory and type safety management.


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

Dreamweaver Mac version
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

WebStorm Mac version
Useful JavaScript development tools

