
Home >Java >javaTutorial >How to solve the 502 error when upgrading k8s service springboot project application
How to solve the 502 error when upgrading k8s service springboot project application

- 王林forward
- 2023-05-11 22:28:042973browse
As the development model of small steps and rapid iteration is recognized and adopted by more and more Internet companies, the frequency of application changes and upgrades becomes more and more frequent. In order to cope with different upgrade needs and ensure that the upgrade process proceeds smoothly, a series of deployment and release models have been born.
Stop release - completely stop the old version of the application instance, and then release the new version. This release model is mainly to solve the problem of incompatibility and inability to coexist between new and old versions. The disadvantage is that the service is completely unavailable for a period of time.
Blue-green release - Deploy the same number of new and old version application instances online at the same time. After the new version passes the test, the traffic will be switched to the new service instance at once. This publishing model solves the problem of complete service unavailability in downtime publishing, but it will cause relatively large resource consumption.
Rolling Release - Gradually replace application instances in batches. This release mode will not interrupt services and will not consume too many additional resources. However, because instances of the new and old versions are online at the same time, it may cause requests from the same client to switch between the old and new versions, causing compatibility issues.
Canary Release - Gradually switch traffic from the old version to the new version. If no problem is found after observing for a period of time, the traffic of the new version will be further expanded while the traffic of the old version will be reduced.
A/B testing - launch two or more versions at the same time, collect user feedback on these versions, analyze and evaluate the best version for official adoption.
K8s application upgrade
In k8s, pod is the basic unit of deployment and upgrade. Generally speaking, a pod represents an application instance, and the pod will be deployed and run in the form of Deployment, StatefulSet, DaemonSet, Job, etc. The following describes the upgrade methods of pods in these deployment forms.
Deployment
Deployment is the most common deployment form of pod. Here we will take a java application based on spring boot as an example. This application is a simple version abstracted from a real application and is very representative. It has the following characteristics:
After the application is started, it takes a certain amount of time to load the configuration. During this time Internally, services cannot be provided externally.
Being able to start an application does not mean that it can provide services normally.
The application may not automatically exit if it cannot provide services.
During the upgrade process, it is necessary to ensure that the application instance that is about to go offline will not receive new requests and have enough time to process the current request.
Parameter configuration
In order for applications with the above characteristics to achieve zero downtime and no production interruption upgrade, the relevant parameters in the Deployment need to be carefully configured. The configuration related to the upgrade here is as follows (see spring-boot-probes-v1.yaml for the complete configuration).
kind: Deployment
...
spec:
replicas: 8
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 3
maxUnavailable: 2
minReadySeconds: 120
...
template:
...
spec:
containers:
- name: spring-boot-probes
image: registry.cn-hangzhou.aliyuncs.com/log-service/spring-boot-probes:1.0.0
ports:
- containerPort: 8080
terminationGracePeriodSeconds: 60
readinessProbe:
httpGet:
path: /actuator/health
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
failureThreshold: 1
livenessProbe:
httpGet:
path: /actuator/health
port: 8080
initialDelaySeconds: 40
periodSeconds: 20
successThreshold: 1
failureThreshold: 3
...Configuration strategy
You can configure the pod replacement strategy through strategy. The main parameters are as follows.
.spec.strategy.type- Used to specify the strategy type for replacing the pod. This parameter can take the value Recreate or RollingUpdate, and the default is RollingUpdate.Recreate - K8s will first delete all original pods and then create new pods. This method is suitable for scenarios where the old and new versions are incompatible with each other and cannot coexist. However, since this method will cause the service to be completely unavailable for a period of time, it must be used with caution outside the above scenarios.
RollingUpdate - K8s will gradually replace pods in batches, which can be used to implement hot upgrade of services.
.spec.strategy.rollingUpdate.maxSurge- Specifies the maximum number of additional pods that can be created during a rolling update, either as a number or a percentage . The larger the value is set, the faster the upgrade will be, but will consume more system resources..spec.strategy.rollingUpdate.maxUnavailable- Specifies the maximum number of pods allowed to be unavailable during the rolling update process, which can be a number or a percentage. The larger the value is set, the faster the upgrade will be, but the service will be more unstable.
By adjusting maxSurge and maxUnavailable, you can meet the upgrade needs in different scenarios.
If you want to upgrade as quickly as possible while ensuring system availability and stability, you can set maxUnavailable to 0 and give maxSurge a larger value.
If system resources are tight and pod load is low, in order to speed up the upgrade, you can set maxSurge to 0 and give maxUnavailable a larger value. It should be noted that if maxSurge is 0 and maxUnavailable is DESIRED, it may cause the entire service to be unavailable. At this time, RollingUpdate will degrade to a shutdown release.
The sample chooses a compromise solution, setting maxSurge to 3 and maxUnavailable to 2, which balances stability, resource consumption and upgrade speed.
Configuring probes
K8s provides the following two types of probes:
ReadinessProbe - By default, once all containers in a pod are started, k8s will consider the pod to be in a ready state and send traffic to the pod. However, after some applications are started, they still need to complete the loading of data or configuration files before they can provide external services. Therefore, it is not rigorous to judge whether the container is ready by whether it is started. By configuring readiness probes for containers, k8s can more accurately determine whether the container is ready, thereby building a more robust application. K8s ensures that only when all containers in a pod pass the readiness detection, the service is allowed to send traffic to the pod. Once the readiness detection fails, k8s will stop sending traffic to the pod.
LivenessProbe - By default, k8s will consider running containers to be available. But this judgment can be problematic if the application cannot exit automatically when something goes wrong or becomes unhealthy (for example, a severe deadlock occurs). By configuring liveness probes for containers, k8s can more accurately determine whether the container is running normally. If the container fails the liveness detection, the kubelet will stop it and determine the next action based on the restart policy.
The configuration of the probe is very flexible. Users can specify the probe's detection frequency, detection success threshold, detection failure threshold, etc. For the meaning and configuration method of each parameter, please refer to the document Configure Liveness and Readiness Probes.
The sample configures the readiness probe and the liveness probe for the target container:
The initialDelaySeconds of the readiness probe is set to 30, because the application takes an average of 30 seconds time to complete the initialization work.
When configuring the liveness probe, you need to ensure that the container has enough time to reach the ready state. If the parameters initialDelaySeconds, periodSeconds, and failureThreshold are set too small, it may cause the container to be restarted before it is ready, so that the ready state can never be reached. The configuration in the example ensures that if the container is ready within 80 seconds of startup, it will not be restarted, which is a sufficient buffer relative to the average initialization time of 30 seconds.
The periodSeconds of the readiness probe is set to 10, and the failureThreshold is set to 1. In this way, when the container is abnormal, no traffic will be sent to it after about 10 seconds.
The periodSeconds of the activity probe is set to 20, and the failureThreshold is set to 3. In this way, when the container is abnormal, it will not be restarted after about 60 seconds.
Configure minReadySeconds
By default, once the newly created pod becomes ready, k8s will consider the pod to be available and delete the old pod. . But sometimes the problem may be exposed when the new pod is actually processing user requests, so a more robust approach is to observe a new pod for a period of time before deleting the old pod.
The parameter minReadySeconds can control the observation time when the pod is in the ready state. If the containers in the pod can run normally during this period, k8s will consider the new pod available and delete the old pod. When configuring this parameter, you need to weigh it carefully. If it is set too small, it may cause insufficient observation. If it is set too large, it will slow down the upgrade progress. The example sets minReadySeconds to 120 seconds, which ensures that the pod in the ready state can go through a complete liveness detection cycle.
Configuring terminationGracePeriodSeconds
When k8s is ready to delete a pod, it will send a TERM signal to the container in the pod and simultaneously remove the pod from the service's endpoint list. If the container cannot be terminated within the specified time (default 30 seconds), k8s will send the SIGKILL signal to the container to forcefully terminate the process. For the detailed process of Pod termination, please refer to the document Termination of Pods.
Since the application takes up to 40 seconds to process requests, in order to allow it to process the requests that have arrived at the server before shutting down, the sample sets a graceful shutdown time of 60 seconds. For different applications, you can adjust the value of terminationGracePeriodSeconds according to actual conditions.
Observe the upgrade behavior
The above configuration can ensure smooth upgrade of the target application. We can trigger pod upgrade by changing any field of PodTemplateSpec in Deployment and observe the upgrade behavior by running command kubectl get rs -w. The changes in the number of pod copies of the old and new versions observed here are as follows:
Create maxSurge new pods. At this time, the total number of pods reaches the upper limit allowed, that is, DESIRED maxSurge.
Immediately start the deletion process of maxUnavailable old pods without waiting for the new pod to be ready or available. At this time, the number of available pods is DESIRED - maxUnavailable.
If an old pod is completely deleted, a new pod will be added immediately.
When a new pod passes the readiness detection and becomes ready, k8s will send traffic to the pod. However, since the specified observation time has not been reached, the pod will not be considered available.
If a ready pod is running normally during the observation period, it is considered available. At this time, the deletion process of an old pod can be started again.
Repeat steps 3, 4, and 5 until all old pods are deleted and the available new pods reach the target number of replicas.
失败回滚
应用的升级并不总会一帆风顺,在升级过程中或升级完成后都有可能遇到新版本行为不符合预期需要回滚到稳定版本的情况。K8s 会将 PodTemplateSpec 的每一次变更(如果更新模板标签或容器镜像)都记录下来。这样,如果新版本出现问题,就可以根据版本号方便地回滚到稳定版本。回滚 Deployment 的详细操作步骤可参考文档 Rolling Back a Deployment。
StatefulSet
StatefulSet 是针对有状态 pod 常用的部署形式。针对这类 pod,k8s 同样提供了许多参数用于灵活地控制它们的升级行为。好消息是这些参数大部分都和升级 Deployment 中的 pod 相同。这里重点介绍两者存在差异的地方。
策略类型
在 k8s 1.7 及之后的版本中,StatefulSet 支持 OnDelete 和 RollingUpdate 两种策略类型。
OnDelete - 当更新了 StatefulSet 中的 PodTemplateSpec 后,只有手动删除旧的 pod 后才会创建新版本 pod。这是默认的更新策略,一方面是为了兼容 k8s 1.6 及之前的版本,另一方面也是为了支持升级过程中新老版本 pod 互不兼容、无法共存的场景。
RollingUpdate - K8s 会将 StatefulSet 管理的 pod 分批次逐步替换掉。它与 Deployment 中 RollingUpdate 的区别在于 pod 的替换是有序的。例如一个 StatefulSet 中包含 N 个 pod,在部署的时候这些 pod 被分配了从 0 开始单调递增的序号,而在滚动更新时,它们会按逆序依次被替换。
Partition
可以通过参数.spec.updateStrategy.rollingUpdate.partition实现只升级部分 pod 的目的。在配置了 partition 后,只有序号大于或等于 partition 的 pod 才会进行滚动升级,其余 pod 将保持不变。
Partition 的另一个应用是可以通过不断减少 partition 的取值实现金丝雀升级。具体操作方法可参考文档 Rolling Out a Canary。
DaemonSet
DaemonSet 保证在全部(或者一些)k8s 工作节点上运行一个 pod 的副本,常用来运行监控或日志收集程序。对于 DaemonSet 中的 pod,用于控制它们升级行为的参数与 Deployment 几乎一致,只是在策略类型方面略有差异。DaemonSet 支持 OnDelete 和 RollingUpdate 两种策略类型。
OnDelete - 当更新了 DaemonSet 中的 PodTemplateSpec 后,只有手动删除旧的 pod 后才会创建新版本 pod。这是默认的更新策略,一方面是为了兼容 k8s 1.5 及之前的版本,另一方面也是为了支持升级过程中新老版本 pod 互不兼容、无法共存的场景。
RollingUpdate - 其含义和可配参数与 Deployment 的 RollingUpdate 一致。
滚动更新 DaemonSet 的具体操作步骤可参考文档 Perform a Rolling Update on a DaemonSet。
Job
Deployment、StatefulSet、DaemonSet 一般用于部署运行常驻进程,而 Job 中的 pod 在执行完特定任务后就会退出,因此不存在滚动更新的概念。当您更改了一个 Job 中的 PodTemplateSpec 后,需要手动删掉老的 Job 和 pod,并以新的配置重新运行该 job。
总结
K8s 提供的功能可以让大部分应用实现零宕机时间和无生产中断的升级,但也存在一些没有解决的问题,主要包括以下几点:
目前 k8s 原生仅支持停机发布、滚动发布两类部署升级策略。如果应用有蓝绿发布、金丝雀发布、A/B 测试等需求,需要进行二次开发或使用一些第三方工具。
K8s 虽然提供了回滚功能,但回滚操作必须手动完成,无法根据条件自动回滚。
有些应用在扩容或缩容时同样需要分批逐步执行,k8s 还未提供类似的功能。
实例配置:
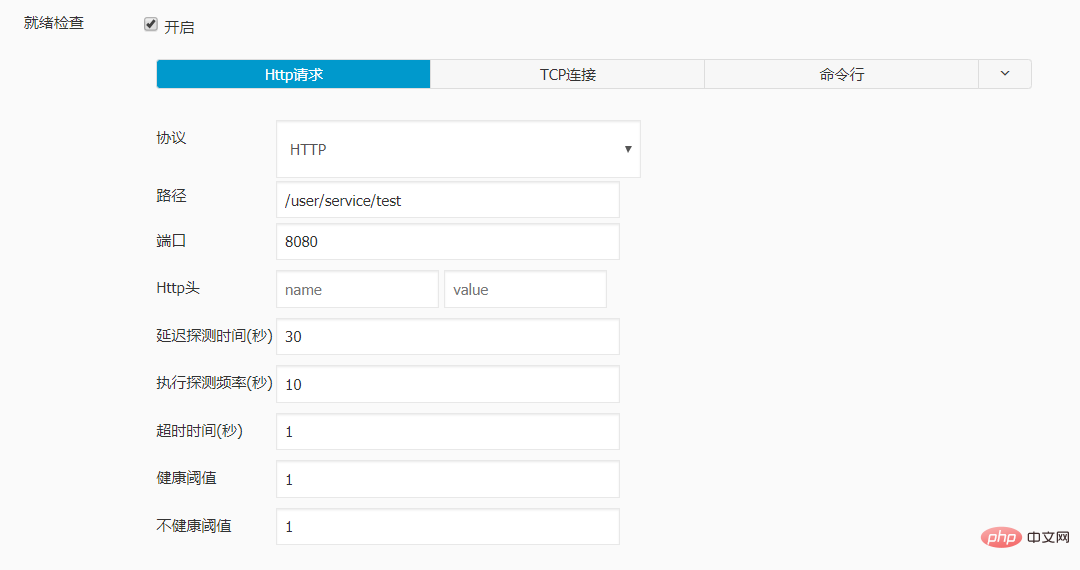
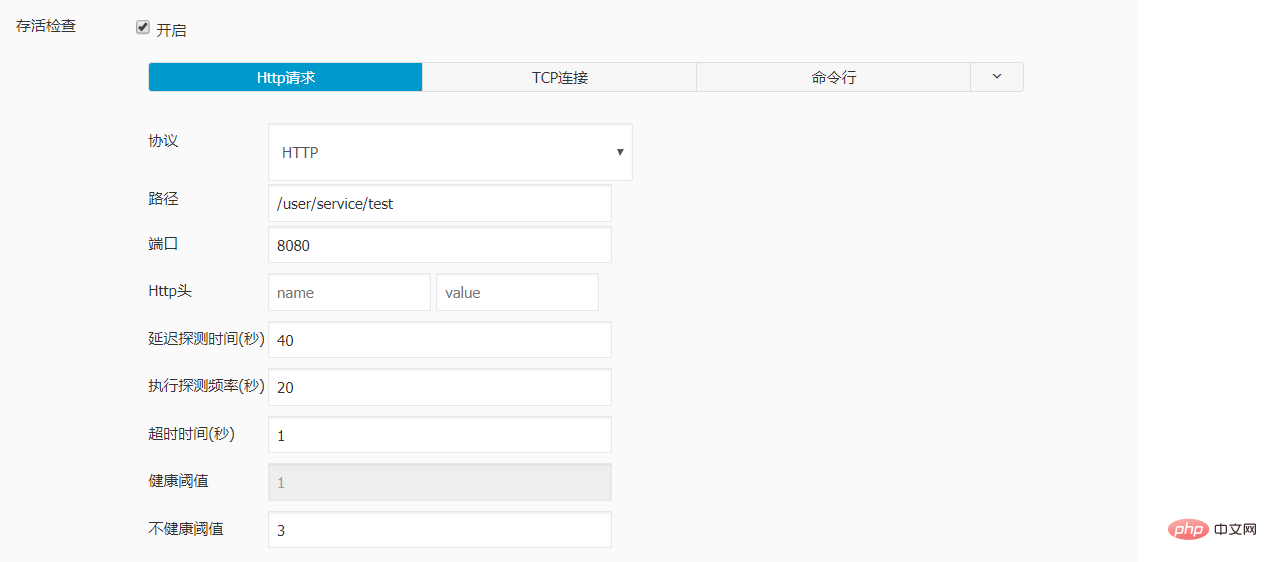
livenessProbe:
failureThreshold: 3
httpGet:
path: /user/service/test
port: 8080
scheme: HTTP
initialDelaySeconds: 40
periodSeconds: 20
successThreshold: 1
timeoutSeconds: 1
name: dataline-dev
ports:
- containerPort: 8080
protocol: TCP
readinessProbe:
failureThreshold: 1
httpGet:
path: /user/service/test
port: 8080
scheme: HTTP
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1经测试 , 再对sprintboot 应用进行更新时, 访问不再出现502的报错。
The above is the detailed content of How to solve the 502 error when upgrading k8s service springboot project application. For more information, please follow other related articles on the PHP Chinese website!