
Home >Java >javaTutorial >How to solve the multi-thread concurrency problem of Java's HashMap
How to solve the multi-thread concurrency problem of Java's HashMap

- PHPzforward
- 2023-05-09 14:28:171687browse
Symptoms of concurrency problems
Multi-threaded put may lead to an infinite loop of get
In the past, our Java code used HashMap for some reasons, but the program at that time was single-threaded , everything is fine. Later, our program performance had problems, so we needed to become multi-threaded. So, after becoming multi-threaded, we went online and found that the program often occupied 100% of the CPU. Check the stack, and you will find that the programs are all hung in HashMap. The .get() method was installed, and the problem disappeared after restarting the program. But it will come again after a while. Moreover, this problem may be difficult to reproduce in a test environment.
If we simply look at our own code, we know that HashMap is operated by multiple threads. The Java documentation says that HashMap is not thread-safe and ConcurrentHashMap should be used. But here we can study the reasons. The simple code is as follows:
package com.king.hashmap;
import java.util.HashMap;
public class TestLock {
private HashMap map = new HashMap();
public TestLock() {
Thread t1 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.put( new Integer(i), i);
}
System.out.println( "t1 over" );
}
};
Thread t2 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.put( new Integer(i), i);
}
System.out.println( "t2 over" );
}
};
Thread t3 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.put( new Integer(i), i);
}
System.out.println( "t3 over" );
}
};
Thread t4 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.put( new Integer(i), i);
}
System.out.println( "t4 over" );
}
};
Thread t5 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.put( new Integer(i), i);
}
System.out.println( "t5 over" );
}
};
Thread t6 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.get( new Integer(i));
}
System.out.println( "t6 over" );
}
};
Thread t7 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.get( new Integer(i));
}
System.out.println( "t7 over" );
}
};
Thread t8 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.get( new Integer(i));
}
System.out.println( "t8 over" );
}
};
Thread t9 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.get( new Integer(i));
}
System.out.println( "t9 over" );
}
};
Thread t10 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.get( new Integer(i));
}
System.out.println( "t10 over" );
}
};
t1.start();
t2.start();
t3.start();
t4.start();
t5.start();
t6.start();
t7.start();
t8.start();
t9.start();
t10.start();
}
public static void main(String[] args) {
new TestLock();
}
}is to start 10 threads and continuously put content/get content into a non-thread-safe HashMap. The content of the put is very simple, and the key and value are incremented from 0. Integer (the content of this put was not done well, so that it later interfered with my idea of analyzing the problem). When performing concurrent write operations on HashMap, I thought it would only produce dirty data. However, if I run this program repeatedly, threads t1 and t2 will be hung. In most cases, one thread will be hung and the other will end successfully. , occasionally all 10 threads will be hung.
The root cause of this infinite loop lies in the operation of an unprotected shared variable - a "HashMap" data structure. After adding "synchronized" to all operation methods, everything returned to normal. Is this a jvm bug? It should be said that no, this phenomenon has been reported a long time ago. Sun engineers do not think this is a bug, but suggest that "ConcurrentHashMap" should be used in such a scenario.
Excessive CPU utilization is generally due to the occurrence of an infinite loop, causing some threads to keep running. , taking up cpu time. The cause of the problem is that HashMap is not thread-safe. When multiple threads put, it causes an infinite loop of a certain key value Entry key List, and the problem arises.
When another thread gets the key of this Entry List infinite loop, this get will always be executed. The end result is more and more threads in an infinite loop, eventually causing the server to crash. We generally think that when a HashMap inserts a certain value repeatedly, it will overwrite the previous value. This is correct. However, for multi-threaded access, due to its internal implementation mechanism (in a multi-threaded environment and without synchronization, a put operation on the same HashMap may cause two or more threads to perform rehash operations at the same time, which may lead to circular keys table appears, once the thread cannot be terminated and continues to occupy the CPU, resulting in high CPU usage), security issues may arise.
Use the jstack tool to dump the stack information of the server with the problem. If there is an infinite loop, first search for the thread of RUNNABLE and find the problem code as follows:
java.lang.Thread.State:RUNNABLE
at java.util.HashMap.get(HashMap.java:303 )
at com.sohu.twap.service.logic.TransformTweeter.doTransformTweetT5(TransformTweeter.java:183)
Appeared 23 times in total.
java.lang.Thread.State:RUNNABLE
at java.util.HashMap.put(HashMap.java:374)
at com.sohu.twap.service.logic.TransformTweeter.transformT5(TransformTweeter. java:816)
appears 3 times in total.
Note: Improper use of HashMap results in an infinite loop rather than a deadlock.
Multi-threaded put may cause elements to be lost
The main problem lies in the new Entry (hash, key, value, e) of the addEntry method. If both threads obtain e at the same time, Then their next elements are all e, and then when assigning values to table elements, one is successful and the other is lost.
After putting the non-null element, the result obtained is null
The code in the transfer method is as follows:
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for ( int j = 0 ; j < src.length; j++) {
Entry e = src[j];
if (e != null ) {
src[j] = null ;
do {
Entry next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null );
}
}
}In this method, assign the old array to src and traverse src, when the element of src is not null, set the element in src to null, that is, set the element in the old array to null, which is this sentence:
if (e != null ) {
src[j] = null ;If there is a get method to access this key, it still obtains the old array, and of course it cannot obtain its corresponding value.
Summary: When HashMap is not synchronized, many subtle problems will occur in concurrent programs, and it is difficult to find the cause from the surface. Therefore, if there is a counterintuitive phenomenon when using HashMap, it may be caused by concurrency.
HashMap data structure
I need to briefly talk about the classic data structure HashMap.
HashMap usually uses a pointer array (assumed to be table[]) to disperse all keys. When a key is added, the subscript i of the array will be calculated through the key through the Hash algorithm, and then Insert this into table[i]. If two different keys are counted in the same i, it is called a conflict, also called a collision. This will form a linked list on table[i].
We know that if the size of table[] is very small, such as only 2, and if 10 keys are to be put in, collisions will be very frequent, so an O(1) search algorithm becomes Without linked list traversal, the performance becomes O(n), which is a flaw of Hash tables.
所以,Hash表的尺寸和容量非常的重要。一般来说,Hash表这个容器当有数据要插入时,都会检查容量有没有超过设定的thredhold,如果超过,需要增大Hash表的尺寸,但是这样一来,整个Hash表里的元素都需要被重算一遍。这叫rehash,这个成本相当的大。
HashMap的rehash源代码
下面,我们来看一下Java的HashMap的源代码。Put一个Key,Value对到Hash表中:
public V put(K key, V value)
{
......
//算Hash值
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//如果该key已被插入,则替换掉旧的value (链接操作)
for (Entry<K,V> e = table[i]; e != null ; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess( this );
return oldValue;
}
}
modCount++;
//该key不存在,需要增加一个结点
addEntry(hash, key, value, i);
return null ;
}检查容量是否超标:
void addEntry( int hash, K key, V value, int bucketIndex)
{
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
//查看当前的size是否超过了我们设定的阈值threshold,如果超过,需要resize
if (size++ >= threshold)
resize( 2 * table.length);
}新建一个更大尺寸的hash表,然后把数据从老的Hash表中迁移到新的Hash表中。
void resize( int newCapacity)
{
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
......
//创建一个新的Hash Table
Entry[] newTable = new Entry[newCapacity];
//将Old Hash Table上的数据迁移到New Hash Table上
transfer(newTable);
table = newTable;
threshold = ( int )(newCapacity * loadFactor);
}迁移的源代码,注意高亮处:
void transfer(Entry[] newTable)
{
Entry[] src = table;
int newCapacity = newTable.length;
//下面这段代码的意思是:
// 从OldTable里摘一个元素出来,然后放到NewTable中
for ( int j = 0 ; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null ) {
src[j] = null ;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null );
}
}
}好了,这个代码算是比较正常的。而且没有什么问题。
正常的ReHash过程
画了个图做了个演示。
我假设了我们的hash算法就是简单的用key mod 一下表的大小(也就是数组的长度)。
最上面的是old hash 表,其中的Hash表的size=2, 所以key = 3, 7, 5,在mod 2以后都冲突在table1这里了。
接下来的三个步骤是Hash表 resize成4,然后所有的 重新rehash的过程。
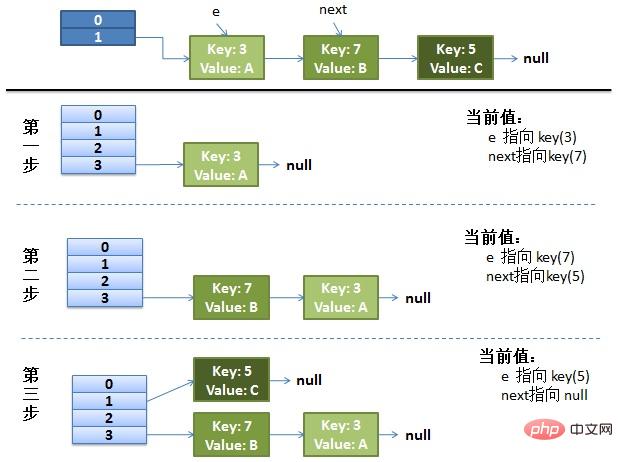
并发的Rehash过程
(1)假设我们有两个线程。我用红色和浅蓝色标注了一下。我们再回头看一下我们的 transfer代码中的这个细节:
do {
Entry<K,V> next = e.next; // <--假设线程一执行到这里就被调度挂起了
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null );而我们的线程二执行完成了。于是我们有下面的这个样子。
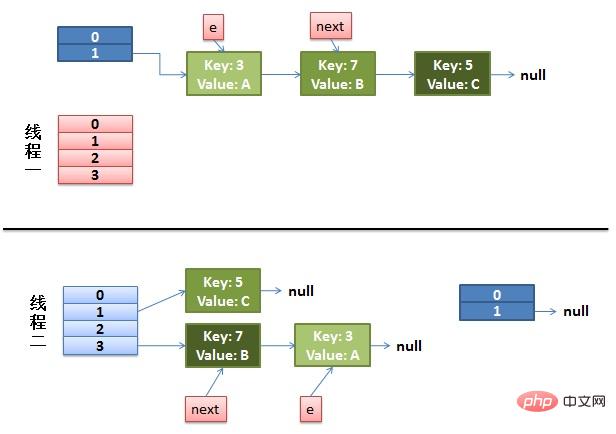
注意:因为Thread1的 e 指向了key(3),而next指向了key(7),其在线程二rehash后,指向了线程二重组后的链表。我们可以看到链表的顺序被反转后。
(2)线程一被调度回来执行。
先是执行 newTalbe[i] = e。
然后是e = next,导致了e指向了key(7)。
而下一次循环的next = e.next导致了next指向了key(3)。
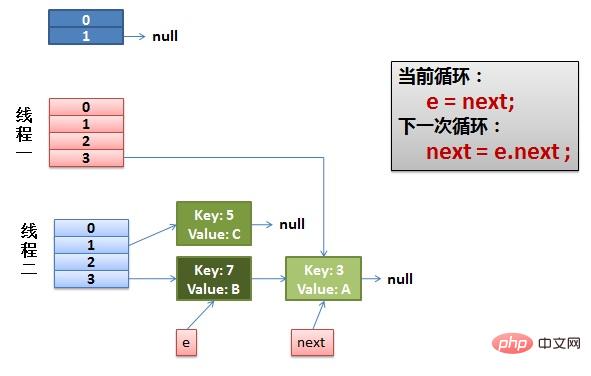
(3)一切安好。 线程一接着工作。把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移。
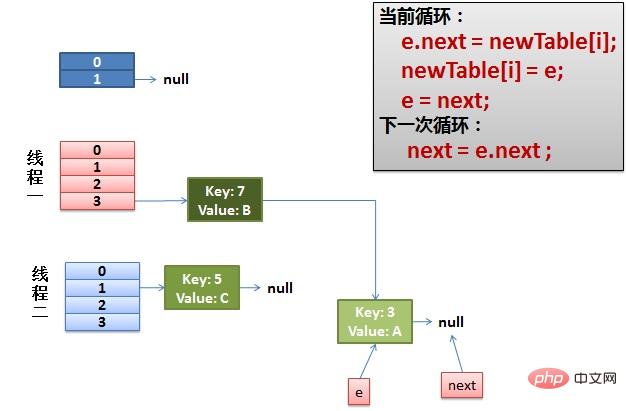
(4)环形链接出现。 e.next = newTable[i] 导致 key(3).next 指向了 key(7)。注意:此时的key(7).next 已经指向了key(3), 环形链表就这样出现了。
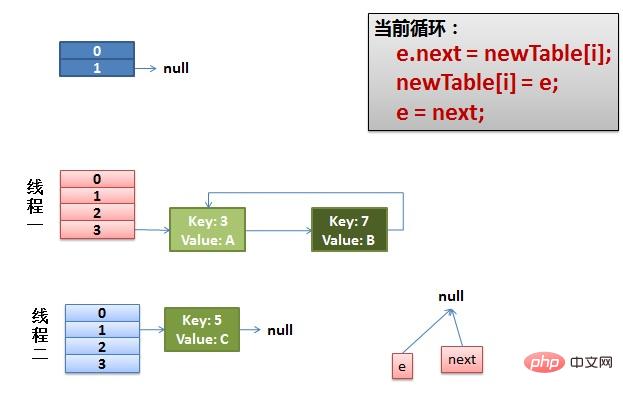
于是,当我们的线程一调用到,HashTable.get(11)时,悲剧就出现了——Infinite Loop。
三种解决方案
Hashtable替换HashMap
Hashtable 是同步的,但由迭代器返回的 Iterator 和由所有 Hashtable 的“collection 视图方法”返回的 Collection 的 listIterator 方法都是快速失败的:在创建 Iterator 之后,如果从结构上对 Hashtable 进行修改,除非通过 Iterator 自身的移除或添加方法,否则在任何时间以任何方式对其进行修改,Iterator 都将抛出 ConcurrentModificationException。因此,面对并发的修改,Iterator 很快就会完全失败,而不冒在将来某个不确定的时间发生任意不确定行为的风险。由 Hashtable 的键和值方法返回的 Enumeration 不是快速失败的。
注意,迭代器的快速失败行为无法得到保证,因为一般来说,不可能对是否出现不同步并发修改做出任何硬性保证。快速失败迭代器会尽最大努力抛出 ConcurrentModificationException。因此,为提高这类迭代器的正确性而编写一个依赖于此异常的程序是错误做法:迭代器的快速失败行为应该仅用于检测程序错误。
Collections.synchronizedMap将HashMap包装起来
返回由指定映射支持的同步(线程安全的)映射。为了保证按顺序访问,必须通过返回的映射完成对底层映射的所有访问。在返回的映射或其任意 collection 视图上进行迭代时,强制用户手工在返回的映射上进行同步:
Map m = Collections.synchronizedMap( new HashMap());
...
Set s = m.keySet(); // Needn't be in synchronized block
...
synchronized (m) { // Synchronizing on m, not s!
Iterator i = s.iterator(); // Must be in synchronized block
while (i.hasNext())
foo(i.next());
}不遵从此建议将导致无法确定的行为。如果指定映射是可序列化的,则返回的映射也将是可序列化的。
ConcurrentHashMap replaces HashMap
A hash table that supports full concurrency in retrieval and the desired adjustable concurrency in updates. This class adheres to the same functional specification as Hashtable and includes method versions corresponding to each method of Hashtable. However, although all operations are thread-safe, retrieval operations do not have to lock, and locking the entire table in a way that prevents all access is not supported. This class can be fully programmatically interoperable with a Hashtable, depending on its thread safety, independent of its synchronization details. Retrieval operations (including get) are generally not blocking and, therefore, may overlap with update operations (including put and remove). Retrieval affects the results of the most recently completed update operation. For some aggregate operations, such as putAll and clear, concurrent retrieval may only affect the insertion and removal of certain entries. Similarly, Iterators and Enumerations return the elements that affected the state of the hash table at a point in time, either when the iterator/enumeration was created or since. They do not throw ConcurrentModificationException. However, iterators are designed to be used by only one thread at a time.
The above is the detailed content of How to solve the multi-thread concurrency problem of Java's HashMap. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Implicit vs. Explicit Waits in Selenium-WebDriver: Which Should You Choose?
- How Can Multi-Catch Blocks Simplify Exception Handling in Java?
- How to Calculate the Difference Between Two Dates in Days Using Android/Java?
- What does final mean in java
- How to Manage Event Listeners in RecyclerView Item ViewHolders with FirebaseUI-Android?