

 Technology peripheralsAIWhen machine learning is implemented in autonomous driving, the core is not the model, but the pipeline
Technology peripheralsAIWhen machine learning is implemented in autonomous driving, the core is not the model, but the pipelineWhen machine learning is implemented in autonomous driving, the core is not the model, but the pipeline

This article is reproduced from Lei Feng.com. If you need to reprint, please go to the official website of Lei Feng.com to apply for authorization.
When I started my first job after college, I thought I knew a lot about machine learning. I had two internships at Pinterest and Khan Academy building machine learning systems. During my final year at Berkeley, I conducted research on deep learning for computer vision and worked on Caffe, one of the first popular deep learning libraries. After graduation, I joined a small startup called "Cruise", which specializes in producing self-driving cars. Now I'm at Aquarium, helping companies deploy deep learning models to solve important social problems.
Over the years I've built a pretty cool deep learning and computer vision stack. More people are using deep learning in production applications now than when I was doing research at Berkeley. Many of the problems they face now are the same ones I faced at Cruise in 2016. I have a lot of lessons learned about deep learning in production that I want to share with you, and I hope you don’t have to learn them the hard way.

Note: The author’s team developed the first machine learning model deployed on a car
1 ML The story of model deployment to self-driving cars
First, let me talk about Cruise’s first-ever ML model deployed on a car. As we developed the model, the workflow felt a lot like what I was used to during my research days. We train open source models on open source data, integrate them into the company's product software stack, and deploy them to cars. After a few weeks of work, we merged the final PR and ran the model on the car.
"Mission accomplished!" I thought to myself, we should continue to put out the next fire. Little did I know, the real work was just beginning.
The model was put into production and our QA team started to notice performance issues with it. But we had other models to build and other tasks to do, so we didn't address those issues right away. When we looked into the issues 3 months later, we discovered that the training and validation scripts had all broken because the codebase had changed since our first deployment.
After a week of fixes, we looked at the past few months of outages and realized that many of the issues observed in the production runs of the model could not be easily solved by modifying the model code and we needed to collect and tag the issues that came from our New data on company vehicles instead of relying on open source data. This means we need to establish a labeling process, including all the tools, operations and infrastructure required for the process.
After another 3 months, we ran a new model that was trained on data we randomly selected from the car. Then, mark it up with our own tools. But when we start solving simple problems, we have to become more discerning about what changes are likely to have consequences.
About 90% of problems are solved through careful data curation of difficult or rare scenarios, rather than through deep model architecture changes or hyperparameter tuning. For example, we found that the model performed poorly on rainy days (a rarity in San Francisco), so we labeled more rainy day data, retrained the model on the new data, and the model's performance improved. Likewise, we found that the model performed poorly on green frustums (less common compared to orange frustums), so we collected data on green frustums and went through the same process, and the model's performance improved.
We need to establish a process that can quickly identify and resolve these types of issues.
It took several weeks to assemble the 1.0 version of this model, and another 6 months to launch a new and improved version of the model. As we work more and more on several aspects (better labeling infrastructure, cloud data processing, training infrastructure, deployment monitoring), we are retraining and redeploying models approximately every month to every week.
As we build more model pipelines from scratch and work to improve them, we start to see some common themes. Applying what we learned to new pipelines, it became easier to run better models faster and with less effort.
2 Maintain iterative learning
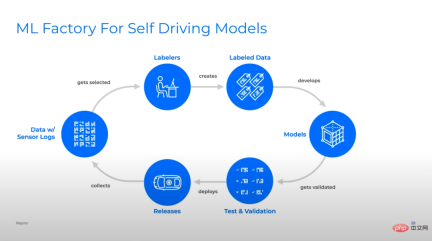
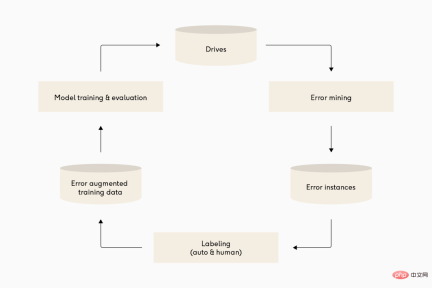
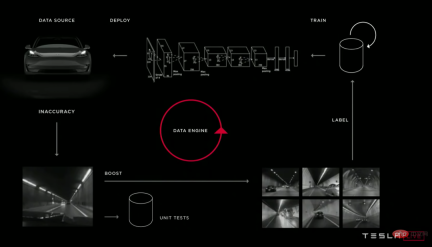
Illustration: Many different self-driving deep learning teams have quite similar iteration cycles of their model pipelines. From top to bottom: Waymo, Cruise and Tesla.
I used to think that machine learning was mainly about models. In reality, machine learning in industrial production is mostly pipeline. One of the best predictors of success is the ability to iterate efficiently on the model pipeline. This doesn’t just mean iterating quickly, it means iterating smartly, and the second part is critical, otherwise your pipeline will produce bad models very quickly.
Most traditional software emphasizes rapid iteration and agile delivery processes, because product requirements are unknown and must be discovered through adaptation, so instead of making detailed planning with unstable assumptions in the early stage, it is better to deliver quickly An MVP and iterate.
Just as traditional software requirements are complex, the domain of data input that machine learning systems must deal with is truly vast. Unlike normal software development, the quality of a machine learning model depends on its implementation in code, and the data on which the code relies. This reliance on data means that the machine learning model can "explore" the input domain through dataset construction/management, allowing it to understand the task requirements and adapt to it over time without having to modify the code.
To take advantage of this feature, machine learning requires a concept of continuous learning that emphasizes iteration over data and code. Machine learning teams must:
- Discover problems in data or model performance
- Diagnose why problems occur
- Change data or model code to resolve these problems
- Validate that the model gets better after retraining
- Deploy the new model and repeat
Teams should try to go through this cycle at least every month. If you're good, maybe do it every week.
Large companies can complete a model deployment cycle in less than a day, but building infrastructure quickly and automatically is difficult for most teams. If the model is updated less frequently than this, it can lead to code corruption (the model pipeline is interrupted due to changes in the code base) or data domain shift (the model in production cannot generalize to changes in the data over time).
Large companies can complete a model deployment cycle in a day, but for most teams, building infrastructure quickly and automatically is very difficult. Updating the model less frequently than this can lead to code corruption (the model pipeline is broken due to changes in the code base) or data domain shift (the model in production cannot generalize to changes in the data over time).
However, if done correctly, the team can get into a good rhythm where they deploy the improved model into production.
3 Building Feedback Loops
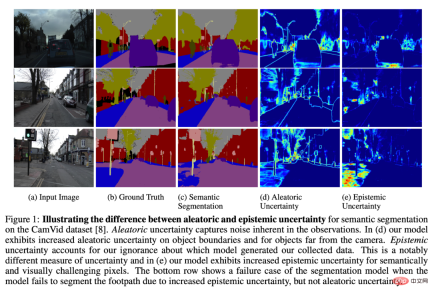
Uncertainty in calibrating models is a tantalizing area of research, where the model can flag where it thinks it might fail.
A key part of iterating effectively on a model is to focus on solving the most impactful problems. To improve a model, you need to know what's wrong with it and be able to categorize the problems according to product/business priorities. There are many ways to build feedback loops, but it starts with finding and classifying errors.
Take advantage of domain-specific feedback loops.
If anything, this can be a very powerful and effective way of getting feedback on your model. For example, prediction tasks can get labeled data "for free" by training on historical data of actual occurrences, allowing them to continuously be fed large amounts of new data and adapt to new situations fairly automatically.
Set up a workflow that allows people to review the output of your model and flag errors when they occur.
This approach is particularly useful when one can easily catch errors through many model inferences. The most common way this happens is when a customer notices an error in the model output and complains to the machine learning team. This is not to be underestimated as this channel allows you to incorporate customer feedback directly into the development cycle! A team can have humans double-check model outputs that customers might have missed: Imagine an operator watching a robot sorting packages on a conveyor belt and clicking a button when they see an error occur.
Set up a workflow that allows people to review the output of your model and flag errors when they occur. This is particularly appropriate when errors in a large number of model inferences are easily caught by human review. The most common way is when a customer notices an error in the model output and complains to the ML team. This shouldn’t be underestimated, as this channel allows you to incorporate customer feedback directly into the development cycle. A team can have humans scrutinize model output that customers may have missed: think of an operator watching a robot sort packages on a conveyor belt, Click a button every time they see an error occur.
Consider setting up automatic review when the model is run too frequently for humans to check.
This is especially useful when it is easy to write "sanity checks" against the model output. For example, flag every time the lidar object detector and the 2D image object detector are inconsistent, or the frame-to-frame detector is inconsistent with the temporal tracking system. When it works, it provides a lot of useful feedback, telling us where failure conditions are occurring. When it doesn't work, it just exposes bugs in your checking system, or misses all the times the system goes wrong, which is very low risk and high reward.
The most general (but difficult) solution is to analyze the model uncertainty on the data it is run on.
A simple example is to look at examples where a model produces low confidence output in production. This can show where the model is indeed uncertain, but is not 100% accurate. Sometimes, a model can be confidently wrong. Sometimes models are indeterminate because there is a lack of information available for good inference (e.g., noisy input data that is difficult for humans to understand). There are models that address these issues, but this is an active area of research.
Finally, you can use the model’s feedback on the training set.
For example, checking for inconsistencies between a model and its training/validation dataset (i.e., high-loss examples) indicates high-confidence failures or mislabelings. Neural network embedding analysis can provide a way to understand the pattern of failure modes in the training/validation data set and can discover differences in the raw data distribution in the training data set and the production data set.

Caption: Most people’s time is easily removed from a typical retraining cycle. Even if this comes at the cost of less efficient machine time, it eliminates a lot of manual pain.
The main content of speeding up iteration is to reduce the amount of work required to complete an iteration cycle. However, there are always ways to make things easier, so you have to prioritize what you want to improve. I like to think of effort in two ways: clock time and human time.
Clock time refers to the time required to run certain computing tasks, such as ETL of data, training models, running inference, calculating indicators, etc. Human time refers to the time a human must actively intervene to run through the pipeline, such as manually checking results, running commands, or triggering scripts in the middle of the pipeline.
For example, multiple scripts must be run manually in sequence by manually moving files between steps, which is very common, but wasteful. Some back-of-the-napkin math: If a machine learning engineer costs $90 an hour and wastes 2 hours a week running scripts by hand, that adds up to $9,360 per person per year!
Combining multiple scripts and human interrupts into one fully automated script makes running a model pipeline loop faster and easier, saving tons of money, and making your machine learning engineers less weird.
In contrast, clock time usually needs to be "reasonable" (e.g., can be done overnight). The only exceptions are if machine learning engineers are conducting extensive experiments, or if there are extreme cost/scaling constraints. This is because clock time is generally proportional to data size and model complexity. When moving from local processing to distributed cloud processing, clock time is reduced significantly. After that, horizontal scaling in the cloud tends to solve most problems for most teams until the problem grows in size.
Unfortunately, it's not possible to completely automate some tasks. Almost all production machine learning applications are supervised learning tasks, and most rely on some amount of human interaction to tell the model what it should do. In some areas, human-computer interaction is free (e.g., social media recommendation use cases or other applications with large amounts of direct user feedback). In other cases, human time is more limited or expensive, such as when trained radiologists “label” CT scans for training data.
Either way, it is important to minimize the labor time and other costs required to improve the model. While early teams may rely on machine learning engineers to manage data sets, it is often more economical (or in the case of radiologists, necessary) to have an operational user or domain expert without machine learning knowledge do the heavy lifting of data management. . At this point, it becomes important to establish an operational process for labeling, inspecting, improving, and versioning data sets using good software tools.
5 Encourage ML engineers to keep fit

Legend: While ML engineers are lifting weights, they are also increasing the weight of their model learning
Building enough tools to support a new domain or a new user group can take a lot of time and effort, but if done well, the results will be well worth it. One of my engineers at Cruise was particularly smart (some would say lazy).
This engineer established an iterative loop in which a combination of operational feedback and metadata queries would extract and label data where model performance was poor. A team of offshore operations will then label the data and add it to a new version of the training dataset. After that, engineers set up infrastructure that allowed them to run a script on their computer and launch a series of cloud tasks to automatically retrain and validate a simple model on newly added data.
Every week, they run the retrain script. Then, while the model trained and validated itself, they hit the gym. After a few hours of fitness and dinner, they would come back to check the results. Coincidentally, new and improved data will lead to improvements to the model, and after a quick double check to make sure everything makes sense, they then ship the new model to production and the car's drivability will improve. They then spent a week improving the infrastructure, experimenting with new model architectures, and building new model pipelines. Not only did this engineer get a promotion at the end of the quarter, he was in great shape.
6 Conclusion
To summarize: During the research and prototyping phases, the focus is on building and publishing a model. However, as a system enters production, the core task is to build a system that can regularly release improved models with minimal effort. The better you get at this, the more models you can build!
To do this, we need to focus on the following:
- Run the model pipeline at a regular cadence and focus on making the shipping model better than before. Get a new and improved model into production every week or less!
- Establish a good feedback loop from model output to the development process. Find out which examples the model does poorly and add more examples to your training dataset.
- Automate particularly heavy-duty tasks in your pipeline and establish a team structure that allows your team members to focus on their areas of expertise. Tesla's Andrej Karpathy calls the ideal end state "Operation Holiday." I suggest, set up a workflow where your machine learning engineers go to the gym and let your machine learning pipeline do the heavy lifting!
Finally, it needs to be emphasized that in my experience, most problems about model performance can be solved with data, but some problems can only be solved by modifying the model code.
These changes are often very specific to the model architecture at hand, for example, after working on an image object detector for several years, I spent too much time worrying about the best previous box assignment for certain orientation ratios and improve the resolution of feature maps for small objects.
However, as Transformers show promise in becoming a universal model architecture type for many different deep learning tasks, I suspect that more of these techniques will become less relevant and the focus of machine learning development will shift further. Improve the data set.
The above is the detailed content of When machine learning is implemented in autonomous driving, the core is not the model, but the pipeline. For more information, please follow other related articles on the PHP Chinese website!

 The Hidden Dangers Of AI Internal Deployment: Governance Gaps And Catastrophic RisksApr 28, 2025 am 11:12 AM
The Hidden Dangers Of AI Internal Deployment: Governance Gaps And Catastrophic RisksApr 28, 2025 am 11:12 AMThe unchecked internal deployment of advanced AI systems poses significant risks, according to a new report from Apollo Research. This lack of oversight, prevalent among major AI firms, allows for potential catastrophic outcomes, ranging from uncont
 Building The AI PolygraphApr 28, 2025 am 11:11 AM
Building The AI PolygraphApr 28, 2025 am 11:11 AMTraditional lie detectors are outdated. Relying on the pointer connected by the wristband, a lie detector that prints out the subject's vital signs and physical reactions is not accurate in identifying lies. This is why lie detection results are not usually adopted by the court, although it has led to many innocent people being jailed. In contrast, artificial intelligence is a powerful data engine, and its working principle is to observe all aspects. This means that scientists can apply artificial intelligence to applications seeking truth through a variety of ways. One approach is to analyze the vital sign responses of the person being interrogated like a lie detector, but with a more detailed and precise comparative analysis. Another approach is to use linguistic markup to analyze what people actually say and use logic and reasoning. As the saying goes, one lie breeds another lie, and eventually
 Is AI Cleared For Takeoff In The Aerospace Industry?Apr 28, 2025 am 11:10 AM
Is AI Cleared For Takeoff In The Aerospace Industry?Apr 28, 2025 am 11:10 AMThe aerospace industry, a pioneer of innovation, is leveraging AI to tackle its most intricate challenges. Modern aviation's increasing complexity necessitates AI's automation and real-time intelligence capabilities for enhanced safety, reduced oper
 Watching Beijing's Spring Robot RaceApr 28, 2025 am 11:09 AM
Watching Beijing's Spring Robot RaceApr 28, 2025 am 11:09 AMThe rapid development of robotics has brought us a fascinating case study. The N2 robot from Noetix weighs over 40 pounds and is 3 feet tall and is said to be able to backflip. Unitree's G1 robot weighs about twice the size of the N2 and is about 4 feet tall. There are also many smaller humanoid robots participating in the competition, and there is even a robot that is driven forward by a fan. Data interpretation The half marathon attracted more than 12,000 spectators, but only 21 humanoid robots participated. Although the government pointed out that the participating robots conducted "intensive training" before the competition, not all robots completed the entire competition. Champion - Tiangong Ult developed by Beijing Humanoid Robot Innovation Center
 The Mirror Trap: AI Ethics And The Collapse Of Human ImaginationApr 28, 2025 am 11:08 AM
The Mirror Trap: AI Ethics And The Collapse Of Human ImaginationApr 28, 2025 am 11:08 AMArtificial intelligence, in its current form, isn't truly intelligent; it's adept at mimicking and refining existing data. We're not creating artificial intelligence, but rather artificial inference—machines that process information, while humans su
 New Google Leak Reveals Handy Google Photos Feature UpdateApr 28, 2025 am 11:07 AM
New Google Leak Reveals Handy Google Photos Feature UpdateApr 28, 2025 am 11:07 AMA report found that an updated interface was hidden in the code for Google Photos Android version 7.26, and each time you view a photo, a row of newly detected face thumbnails are displayed at the bottom of the screen. The new facial thumbnails are missing name tags, so I suspect you need to click on them individually to see more information about each detected person. For now, this feature provides no information other than those people that Google Photos has found in your images. This feature is not available yet, so we don't know how Google will use it accurately. Google can use thumbnails to speed up finding more photos of selected people, or may be used for other purposes, such as selecting the individual to edit. Let's wait and see. As for now
 Guide to Reinforcement Finetuning - Analytics VidhyaApr 28, 2025 am 09:30 AM
Guide to Reinforcement Finetuning - Analytics VidhyaApr 28, 2025 am 09:30 AMReinforcement finetuning has shaken up AI development by teaching models to adjust based on human feedback. It blends supervised learning foundations with reward-based updates to make them safer, more accurate, and genuinely help
 Let's Dance: Structured Movement To Fine-Tune Our Human Neural NetsApr 27, 2025 am 11:09 AM
Let's Dance: Structured Movement To Fine-Tune Our Human Neural NetsApr 27, 2025 am 11:09 AMScientists have extensively studied human and simpler neural networks (like those in C. elegans) to understand their functionality. However, a crucial question arises: how do we adapt our own neural networks to work effectively alongside novel AI s


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Dreamweaver CS6
Visual web development tools

WebStorm Mac version
Useful JavaScript development tools

Atom editor mac version download
The most popular open source editor

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

