

 Technology peripheralsAIWhy is DeepMind absent from the GPT feast? It turned out that I was teaching a little robot to play football.
Technology peripheralsAIWhy is DeepMind absent from the GPT feast? It turned out that I was teaching a little robot to play football.Why is DeepMind absent from the GPT feast? It turned out that I was teaching a little robot to play football.

In the view of many scholars, embodied intelligence is a very promising direction towards AGI, and the success of ChatGPT is inseparable from the RLHF technology based on reinforcement learning. DeepMind vs. OpenAI, who can achieve AGI first? The answer seems to have not been revealed yet.
We know that creating general embodied intelligence (i.e., agents that act in the physical world with an agility and dexterity and understand like animals or humans) is an important step for AI researchers and one of the long-term goals of roboticists. Time-wise, the creation of intelligent embodied agents with complex locomotion capabilities goes back many years, both in simulations and in the real world.
The pace of progress has accelerated significantly in recent years, with learning-based methods playing a major role. For example, deep reinforcement learning has been shown to be able to solve complex motion control problems of simulated characters, including complex, perception-driven whole-body control or multi-agent behavior. At the same time, deep reinforcement learning is increasingly used in physical robots. In particular, widely used high-quality quadruped robots have become demonstration targets for learning to generate a range of robust locomotor behaviors.
However, movement in static environments is only one part of the many ways that animals and humans deploy their bodies to interact with the world, and this locomotion modality has been used in much work studying whole-body control and movement manipulation. has been verified, especially for quadruped robots. Examples of related movements include climbing, soccer skills such as dribbling or catching a ball, and simple maneuvers using the legs.
Among them, for football, it shows many characteristics of human sensorimotor intelligence. The complexity of football requires a variety of highly agile and dynamic movements, including running, turning, avoiding, kicking, passing, falling and getting up, etc. These actions need to be combined in a variety of ways. Players need to predict the ball, teammates and opposing players, and adjust their actions according to the game environment. This diversity of challenges has been recognized in the robotics and AI communities, and RoboCup was born.
However, it should be noted that the agility, flexibility and quick response required to play football well, as well as the smooth transition between these elements, are very challenging and time-consuming for manual design of robots. Recently, a new paper from DeepMind (now merged with the Google Brain team to form Google DeepMind) explores the use of deep reinforcement learning to learn agile football skills for a bipedal robot.

Paper address: https://arxiv.org/pdf/2304.13653 .pdf
Project homepage: https://sites.google.com/view/op3-soccer
In this paper, researchers study full-body control and object interaction of small humanoid robots in dynamic multi-agent environments. They considered a subset of the overall football problem, training a low-cost miniature humanoid robot with 20 controllable joints to play a 1 v1 football game and observing proprioception and game state characteristics. With the built-in controller, the robot moves slowly and awkwardly. However, researchers used deep reinforcement learning to synthesize dynamic and agile context-adaptive motor skills (such as walking, running, turning, and kicking a ball and getting back up after falling) that the agent combined in a natural and smooth way into complex long-term behaviors.
In the experiment, the agent learned to predict the movement of the ball, position it, block attacks, and use bounced balls. Agents achieve these behaviors in a multi-agent environment thanks to a combination of skill reuse, end-to-end training, and simple rewards. The researchers trained agents in simulation and transferred them to physical robots, demonstrating that simulation-to-real transfer is possible even for low-cost robots.
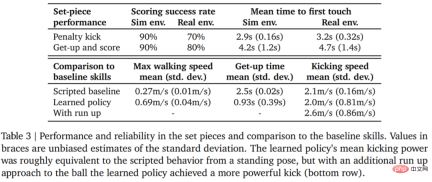
Let the data speak for itself. The robot’s walking speed increased by 156%, the time to get up was reduced by 63%, and the kicking speed was also increased by 24% compared to the baseline.
Before going into the technical interpretation, let’s take a look at some of the highlights of robots in 1v1 football matches. For example, shooting:


## Penalty kick:

Turn, dribble and kick, all in one go

 Experimental settings
Experimental settings
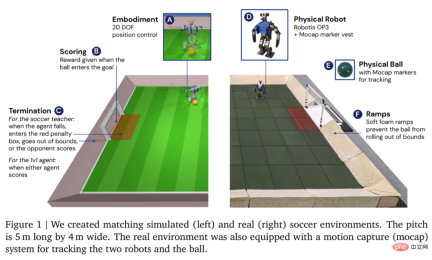
In terms of environment, DeepMind first simulates and trains the agent in a customized football environment, and then migrates the strategy to the corresponding real environment, as shown in Figure 1. The environment consisted of a football pitch 5 m long and 4 m wide, with two goals, each with an opening width of 0.8 m. In both simulated and real environments, the court is bounded by ramps to keep the ball in bounds. The real court is covered with rubber tiles to reduce the risk of damaging the robot from a fall and to increase friction on the ground.

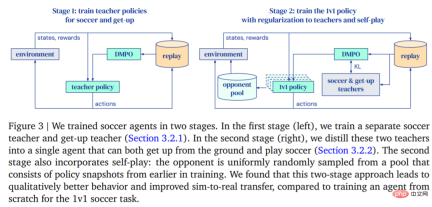
- In the first phase, DeepMind trains teacher strategies for two specific skills: getting the agent up from the ground and scoring a goal.
- In the second stage, the teacher strategy from the first stage is used to regulate the agent while the agent learns to effectively fight against increasingly powerful opponents.

After the agent is trained, the next step is to transfer the trained kicking strategy to the real robot with zero samples. In order to improve the success rate of zero-shot transfer, DeepMind reduces the gap between simulated agents and real robots through simple system identification, improves the robustness of the strategy through domain randomization and perturbation during training, and includes shaping the reward strategy to obtain different results. Behavior that is too likely to harm the robot. 1v1 Competition: The soccer agent can handle a variety of emergent behaviors, including flexible motor skills such as getting up from the ground, quickly recovering from falls, and running and turn around. During the game, the agent transitions between all these skills in a fluid manner. Experiment

Table 3 below shows the quantitative analysis results. It can be seen from the results that the reinforcement learning strategy performs better than specialized artificially designed skills, with the agent walking 156% faster and taking 63% less time to get up.

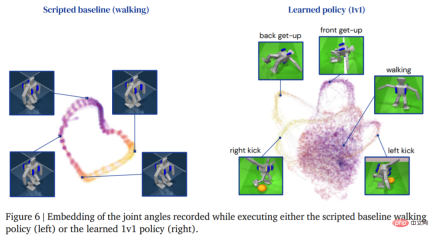
The following figure shows the walking trajectory of the agent. In contrast, the trajectory structure of the agent generated by the learning strategy Richer:
#To evaluate the reliability of the learning strategy, DeepMind designed penalty kicks and jumping shot set pieces, and Implemented in simulated and real environments. The initial configuration is shown in Figure 7.

#In the real environment, the robot scored 7 out of 10 times (70%) in the penalty kick task. Hit 8 out of 10 times (80%) on launch missions. In the simulation experiment, the agent's scores in these two tasks were more consistent, which shows that the agent's training strategy is transferred to the real environment (including real robots, balls, floor surfaces, etc.), the performance is slightly degraded, and the behavioral differences are has increased, but the robot is still able to reliably get up, kick the ball, and score. The results are shown in Figure 7 and Table 3.
The above is the detailed content of Why is DeepMind absent from the GPT feast? It turned out that I was teaching a little robot to play football.. For more information, please follow other related articles on the PHP Chinese website!

 Explaining the reasons why you cannot use your credit card with ChatGPT's paid plan and how to deal with itMay 14, 2025 am 03:32 AM
Explaining the reasons why you cannot use your credit card with ChatGPT's paid plan and how to deal with itMay 14, 2025 am 03:32 AMTroubleshooting Guide for Credit Card Payment with ChatGPT Paid Subscriptions Credit card payments may be problematic when using ChatGPT paid subscription. This article will discuss the reasons for credit card rejection and the corresponding solutions, from problems solved by users themselves to the situation where they need to contact a credit card company, and provide detailed guides to help you successfully use ChatGPT paid subscription. OpenAI's latest AI agent, please click ⬇️ for details of "OpenAI Deep Research" 【ChatGPT】Detailed explanation of OpenAI Deep Research: How to use and charging standards Table of contents Causes of failure in ChatGPT credit card payment Reason 1: Incorrect input of credit card information Original
 An easy-to-understand explanation of how to create a VBA macro in ChatGPT!May 14, 2025 am 02:40 AM
An easy-to-understand explanation of how to create a VBA macro in ChatGPT!May 14, 2025 am 02:40 AMFor beginners and those interested in business automation, writing VBA scripts, an extension to Microsoft Office, may find it difficult. However, ChatGPT makes it easy to streamline and automate business processes. This article explains in an easy-to-understand manner how to develop VBA scripts using ChatGPT. We will introduce in detail specific examples, from the basics of VBA to script implementation using ChatGPT integration, testing and debugging, and benefits and points to note. With the aim of improving programming skills and improving business efficiency,
 I can't use the ChatGPT plugin function! Explaining what to do in case of an errorMay 14, 2025 am 01:56 AM
I can't use the ChatGPT plugin function! Explaining what to do in case of an errorMay 14, 2025 am 01:56 AMChatGPT plugin cannot be used? This guide will help you solve your problem! Have you ever encountered a situation where the ChatGPT plugin is unavailable or suddenly fails? The ChatGPT plugin is a powerful tool to enhance the user experience, but sometimes it can fail. This article will analyze in detail the reasons why the ChatGPT plug-in cannot work properly and provide corresponding solutions. From user setup checks to server troubleshooting, we cover a variety of troubleshooting solutions to help you efficiently use plug-ins to complete daily tasks. OpenAI Deep Research, the latest AI agent released by OpenAI. For details, please click ⬇️ [ChatGPT] OpenAI Deep Research Detailed explanation:
 Does ChatGPT not follow the character count specification? A thorough explanation of how to deal with this!May 14, 2025 am 01:54 AM
Does ChatGPT not follow the character count specification? A thorough explanation of how to deal with this!May 14, 2025 am 01:54 AMWhen writing a sentence using ChatGPT, there are times when you want to specify the number of characters. However, it is difficult to accurately predict the length of sentences generated by AI, and it is not easy to match the specified number of characters. In this article, we will explain how to create a sentence with the number of characters in ChatGPT. We will introduce effective prompt writing, techniques for getting answers that suit your purpose, and teach you tips for dealing with character limits. In addition, we will explain why ChatGPT is not good at specifying the number of characters and how it works, as well as points to be careful about and countermeasures. This article
 All About Slicing Operations in PythonMay 14, 2025 am 01:48 AM
All About Slicing Operations in PythonMay 14, 2025 am 01:48 AMFor every Python programmer, whether in the domain of data science and machine learning or software development, Python slicing operations are one of the most efficient, versatile, and powerful operations. Python slicing syntax a
 An easy-to-understand explanation of how to use ChatGPT to create quotes!May 14, 2025 am 01:44 AM
An easy-to-understand explanation of how to use ChatGPT to create quotes!May 14, 2025 am 01:44 AMThe evolution of AI technology has accelerated business efficiency. What's particularly attracting attention is the creation of estimates using AI. OpenAI's AI assistant, ChatGPT, contributes to improving the estimate creation process and improving accuracy. This article explains how to create a quote using ChatGPT. We will introduce efficiency improvements through collaboration with Excel VBA, specific examples of application to system development projects, benefits of AI implementation, and future prospects. Learn how to improve operational efficiency and productivity with ChatGPT. Op
 What is ChatGPT Pro (o1 Pro)? Explaining what you can do, the prices, and the differences between them from other plans!May 14, 2025 am 01:40 AM
What is ChatGPT Pro (o1 Pro)? Explaining what you can do, the prices, and the differences between them from other plans!May 14, 2025 am 01:40 AMOpenAI's latest subscription plan, ChatGPT Pro, provides advanced AI problem resolution! In December 2024, OpenAI announced its top-of-the-line plan, the ChatGPT Pro, which costs $200 a month. In this article, we will explain its features, particularly the performance of the "o1 pro mode" and new initiatives from OpenAI. This is a must-read for researchers, engineers, and professionals aiming to utilize advanced AI. ChatGPT Pro: Unleash advanced AI power ChatGPT Pro is the latest and most advanced product from OpenAI.
 We explain how to create and correct your motivation for applying using ChatGPT! Also introduce the promptMay 14, 2025 am 01:29 AM
We explain how to create and correct your motivation for applying using ChatGPT! Also introduce the promptMay 14, 2025 am 01:29 AMIt is well known that the importance of motivation for applying when looking for a job is well known, but I'm sure there are many job seekers who struggle to create it. In this article, we will introduce effective ways to create a motivation statement using the latest AI technology, ChatGPT. We will carefully explain the specific steps to complete your motivation, including the importance of self-analysis and corporate research, points to note when using AI, and how to match your experience and skills with company needs. Through this article, learn the skills to create compelling motivation and aim for successful job hunting! OpenAI's latest AI agent, "Open


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

SublimeText3 Chinese version
Chinese version, very easy to use

WebStorm Mac version
Useful JavaScript development tools

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver Mac version
Visual web development tools

