

 Technology peripheralsAIRead all SOTA generative models in one article: a complete review of 21 models in nine categories!
Technology peripheralsAIRead all SOTA generative models in one article: a complete review of 21 models in nine categories!Read all SOTA generative models in one article: a complete review of 21 models in nine categories!

In the past two years, there has been a surge in the release of large-scale generative models in the AI industry, especially after the open source of Stable Diffusion and the open interface of ChatGPT, which has further stimulated the industry's enthusiasm for generative models.
But there are many types of generative models and the release speed is very fast. If you are not careful, you may miss sota

Recently, from Comilla, Spain Researchers from Bishop St. John's University comprehensively reviewed the latest progress in AI in various fields, divided generative models into nine categories according to task modes and fields, and summarized 21 generative models released in 2022 to understand generation at once. The development history of the model!

Paper link: https://arxiv.org/abs/2301.04655
Generative AI classification
The model can follow the input and The output data types are classified, currently mainly including 9 categories.

Interestingly, behind these large published models, only six organizations (OpenAI, Google, DeepMind, Meta, Runway, Nvidia) are involved in deploying these latest models. Advanced models.
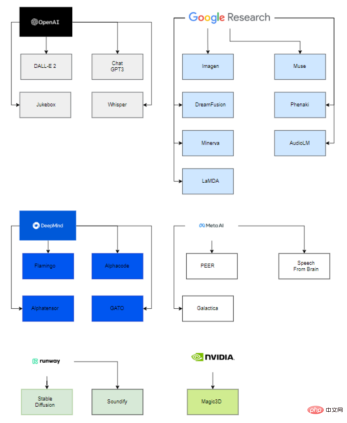
The main reason is that in order to be able to estimate the parameters of these models, one must have extremely large computing power, as well as highly skilled and experienced people in data science and data engineering. team.
Thus, only these companies, with the help of acquired startups and collaborations with academia, can successfully deploy generative AI models.
In terms of big companies getting involved in startups, you can see Microsoft investing $1 billion in OpenAI and helping them develop models; similarly, Google acquired Deepmind in 2014.
On the university side, VisualGPT was developed by King Abdullah University of Science and Technology (KAUST), Carnegie Mellon University and Nanyang Technological University, and the Human Motion Diffusion model was developed by Tel Aviv University in Israel.
Similarly, other projects are developed by a company and a university, such as Stable Diffusion is developed by Runway, Stability AI and the University of Munich; Soundify is developed by Runway and Carnegie Mellon University; DreamFusion A collaboration between Google and the University of California, Berkeley.
Text-to-image model
DALL-E 2
DALL-E 2, developed by OpenAI, is able to generate original, realistic, Realistic images and art, and OpenAI has provided an API to access the model.
What is special about DALL-E 2 is its ability to combine concepts, attributes and different styles. Its ability is derived from the language-image pre-trained model CLIP neural network, so that it can use natural language to indicate the most relevant Text snippet.
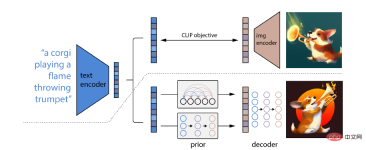
Specifically, CLIP embedding has several ideal properties: the ability to perform stable transformations of image distribution; having strong zero-shot capabilities; and achieving after fine-tuning state-of-the-art results.
To obtain a complete image generation model, the CLIP image embedding decoder module is combined with a prior model to generate relevant CLIP image embeddings from a given text caption

Other models include Imagen, Stable Diffusion, Muse
Text-to-3D model
For some industries, only 2D images can be generated and automation cannot be completed , for example, in the gaming field, 3D models need to be generated.
Dreamfusion
DreamFusion, developed by Google Research, uses a pre-trained 2D text-to-image diffusion model for text-to-3D synthesis.
Dreamfusion replaces the CLIP technique with a loss obtained from the distillation of a two-dimensional diffusion model, that is, the diffusion model can be used as a loss in a general continuous optimization problem to generate samples.

Compared with other methods, which mainly sample pixels, sampling in parameter space is much more difficult than sampling in pixel space. DreamFusion uses a differentiable generator , focuses on creating 3D models that render images from random angles.

Other models such as Magic3D are developed by NVIDIA.
Image-to-Text model
It is also useful to obtain a text describing the image, which is equivalent to the inverse version of image generation.
Flamingo
This model was developed by Deepmind and can be performed on open-ended visual language tasks with just a few input/output example prompts- shot learning.
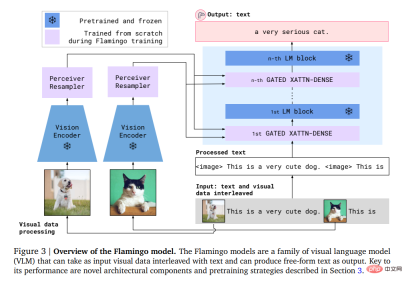
Specifically, Flamingo’s input includes an autoregressive text generation model under visual conditions, which can receive text token sequences interleaved with images or videos and generate text as output .
Users can enter a query into the model and attach a photo or video, and the model will answer with a text answer.

#The Flamingo model leverages two complementary models: a visual model that analyzes visual scenes and a large language model that performs basic forms of reasoning.
VisualGPT
VisualGPT is an image description model developed by OpenAI that leverages knowledge from the pre-trained language model GPT-2.
In order to bridge the semantic gap between different modalities, the researchers designed a new encoder-decoder attention mechanism with rectification gating function.

The biggest advantage of VisualGPT is that it does not require as much data as other image-to-text models. It can improve the data efficiency of image description models and can be applied in niche fields. Or describe rare objects.
Text-to-Video model
Phenaki
This model was developed and produced by Google Research. Given a series of text prompts, Perform realistic video synthesis.
Phenaki is the first model capable of generating videos from open-domain time-variable cues.
To solve the data problem, the researchers jointly trained on a large image-text pair dataset and a smaller number of video-text examples, ultimately achieving generalization capabilities beyond the video dataset.
Mainly image-text datasets tend to have billions of input data, while text-video datasets are much smaller, and computing videos of different lengths is also a difficult problem.

The Phenaki model contains three parts: C-ViViT encoder, training Transformer and video generator.

After converting the input token into embedding, it then passes through the temporal Transformer and spatial Transformer, and then uses a single linear projection without activation to map the token back to the pixel space.
The final model can generate videos with temporal coherence and diversity conditioned on open-domain cues, and is even able to handle some new concepts that do not exist in the dataset.
Related models include Soundify.
Text-to-Audio model
For video generation, sound is also an indispensable part.
AudioLM
This model was developed by Google and can be used to generate high-quality audio with consistency over long distances.
What’s special about AudioLM is that it maps the input audio into a discrete token sequence and uses audio generation as a language modeling task in this representation space.
By training on a large corpus of raw audio waveforms, AudioLM successfully learned to generate natural and coherent continuous speech under brief prompts. This method can even be extended to speech other than human voices, such as continuous piano music, etc., without adding symbolic representation during training.

Since audio signals involve the abstraction of multiple scales, it is very challenging to achieve high audio quality while displaying consistency across multiple scales during audio synthesis. The AudioLM model is implemented by combining recent advances in neural audio compression, self-supervised representation learning, and language modeling.
For subjective evaluation, raters are asked to listen to a 10-second sample and decide whether it is human speech or synthesized speech. Based on 1000 ratings collected, the rate is 51.2%, which is not statistically different from randomly assigned labels, i.e. humans cannot distinguish between synthetic and real samples.
Other related models include Jukebox and Whisper
Text-to-Text model
Commonly used in question and answer tasks.
ChatGPT
The popular ChatGPT was developed by OpenAI to interact with users in a conversational manner.
The user asks a question or the first half of the prompt text, and the model will complete the subsequent parts, and can identify incorrect input conditions and reject inappropriate requests.
Specifically, the algorithm behind ChatGPT is Transformer, and the training process is mainly reinforcement learning based on human feedback.
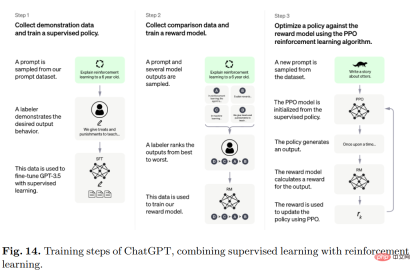
The initial model was trained using fine-tuning under supervised learning, and then humans provided conversations in which they played each other as the user and AI assistant, and then The human corrects the responses returned by the model and helps the model improve with the correct answers.
Mix the produced dataset with InstructGPT's dataset and convert it into conversational format.
Other related models include LaMDA and PEER
Text-to-Code model
is similar to text-to-text, except that it generates a special type of text, namely code.
Codex
This model, developed by OpenAI, can translate text into code.
Codex is a general programming model that can be applied to basically any programming task.
Human activities when programming can be divided into two parts: 1) decomposing a problem into simpler problems; 2) mapping these problems to already existing existing code (library, API or function) middle.
The second part is the most time-wasting part for programmers, and it is also what Codex is best at.
Training data was collected from public software repositories hosted on GitHub in May 2020, containing 179GB of Python files and fine-tuned on GPT-3 , which already contains powerful natural language representations.
Related models also include Alphacode
Text-to-Science model
Scientific research texts are also one of the goals of AI text generation, but there is still a long way to go to achieve results. Gotta go.
Galactica
This model was jointly developed by Meta AI and Papers with Code and can be used to automatically organize large-scale models of scientific text.
The main advantage of Galactica is that even after training multiple episodes, the model will still not be overfitted, and the upstream and downstream performance will improve with the reuse of tokens.
And the design of the dataset is crucial to this approach, as all data is processed in a common markdown format, enabling the mixing of knowledge from different sources.

Citations are processed through a specific token, allowing researchers to predict a citation in any input context. The ability of Galactica models to predict citations increases with scale.
Additionally, the model uses a Transformer architecture in a decoder-only setting with GeLU activation for all sizes of the model, allowing the performance of multi-modal tasks involving SMILES chemical formulas and protein sequences.
Minerva
The main purpose of Minerva is to solve mathematical and scientific problems. For this purpose, it has collected a large amount of training data and solved quantitative reasoning problems and large-scale models. To develop questions, state-of-the-art reasoning techniques are also used.
The Minerva sampling language model architecture solves the problem of input by using step-by-step reasoning, that is, the input needs to contain calculations and symbolic operations without introducing external tools.
Other models
There are also some models that do not fall into the previously mentioned categories.
AlphaTensor
Developed by Deepmind, it is a completely revolutionary model in the industry because of its ability to discover new algorithms.
In the published example, AlphaTensor created a more efficient matrix multiplication algorithm. This algorithm is so important that everything from neural networks to scientific computing programs can benefit from this efficient multiplication calculation.
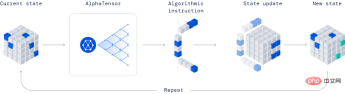
This method is based on the deep reinforcement learning method, in which the training process of the agent AlphaTensor is to play a single-player game, and the goal is to find tensor decomposition in a limited factor space.
At each step of TensorGame, players need to choose how to combine different entries of the matrix to perform multiplication, and receive bonus points based on the number of operations required to achieve the correct multiplication result. AlphaTensor uses a special neural network architecture to exploit the symmetry of the synthetic training game.
GATO
This model is a general agent developed by Deepmind. It can be used as a multi-modal, multi-task or multi-embodiment generalization strategy.
The same network with the same weight can host very different capabilities, from playing Atari games, describing pictures, chatting, stacking blocks, and more.
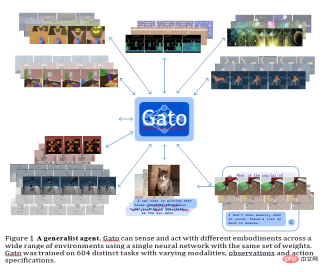
Using a single neural sequence model across all tasks has many benefits, reducing the need to hand-craft strategic models with their own inductive biases and increasing the amount of training data and Diversity.
This general-purpose agent is successful on a wide range of tasks and can be tuned with little additional data to succeed on even more tasks.
Currently GATO has approximately 1.2B parameters, which can control the model scale of real-world robots in real time.

Other published generative artificial intelligence models include generating human motion, etc.
Reference: https://arxiv.org/abs/2301.04655
The above is the detailed content of Read all SOTA generative models in one article: a complete review of 21 models in nine categories!. For more information, please follow other related articles on the PHP Chinese website!

 The Hidden Dangers Of AI Internal Deployment: Governance Gaps And Catastrophic RisksApr 28, 2025 am 11:12 AM
The Hidden Dangers Of AI Internal Deployment: Governance Gaps And Catastrophic RisksApr 28, 2025 am 11:12 AMThe unchecked internal deployment of advanced AI systems poses significant risks, according to a new report from Apollo Research. This lack of oversight, prevalent among major AI firms, allows for potential catastrophic outcomes, ranging from uncont
 Building The AI PolygraphApr 28, 2025 am 11:11 AM
Building The AI PolygraphApr 28, 2025 am 11:11 AMTraditional lie detectors are outdated. Relying on the pointer connected by the wristband, a lie detector that prints out the subject's vital signs and physical reactions is not accurate in identifying lies. This is why lie detection results are not usually adopted by the court, although it has led to many innocent people being jailed. In contrast, artificial intelligence is a powerful data engine, and its working principle is to observe all aspects. This means that scientists can apply artificial intelligence to applications seeking truth through a variety of ways. One approach is to analyze the vital sign responses of the person being interrogated like a lie detector, but with a more detailed and precise comparative analysis. Another approach is to use linguistic markup to analyze what people actually say and use logic and reasoning. As the saying goes, one lie breeds another lie, and eventually
 Is AI Cleared For Takeoff In The Aerospace Industry?Apr 28, 2025 am 11:10 AM
Is AI Cleared For Takeoff In The Aerospace Industry?Apr 28, 2025 am 11:10 AMThe aerospace industry, a pioneer of innovation, is leveraging AI to tackle its most intricate challenges. Modern aviation's increasing complexity necessitates AI's automation and real-time intelligence capabilities for enhanced safety, reduced oper
 Watching Beijing's Spring Robot RaceApr 28, 2025 am 11:09 AM
Watching Beijing's Spring Robot RaceApr 28, 2025 am 11:09 AMThe rapid development of robotics has brought us a fascinating case study. The N2 robot from Noetix weighs over 40 pounds and is 3 feet tall and is said to be able to backflip. Unitree's G1 robot weighs about twice the size of the N2 and is about 4 feet tall. There are also many smaller humanoid robots participating in the competition, and there is even a robot that is driven forward by a fan. Data interpretation The half marathon attracted more than 12,000 spectators, but only 21 humanoid robots participated. Although the government pointed out that the participating robots conducted "intensive training" before the competition, not all robots completed the entire competition. Champion - Tiangong Ult developed by Beijing Humanoid Robot Innovation Center
 The Mirror Trap: AI Ethics And The Collapse Of Human ImaginationApr 28, 2025 am 11:08 AM
The Mirror Trap: AI Ethics And The Collapse Of Human ImaginationApr 28, 2025 am 11:08 AMArtificial intelligence, in its current form, isn't truly intelligent; it's adept at mimicking and refining existing data. We're not creating artificial intelligence, but rather artificial inference—machines that process information, while humans su
 New Google Leak Reveals Handy Google Photos Feature UpdateApr 28, 2025 am 11:07 AM
New Google Leak Reveals Handy Google Photos Feature UpdateApr 28, 2025 am 11:07 AMA report found that an updated interface was hidden in the code for Google Photos Android version 7.26, and each time you view a photo, a row of newly detected face thumbnails are displayed at the bottom of the screen. The new facial thumbnails are missing name tags, so I suspect you need to click on them individually to see more information about each detected person. For now, this feature provides no information other than those people that Google Photos has found in your images. This feature is not available yet, so we don't know how Google will use it accurately. Google can use thumbnails to speed up finding more photos of selected people, or may be used for other purposes, such as selecting the individual to edit. Let's wait and see. As for now
 Guide to Reinforcement Finetuning - Analytics VidhyaApr 28, 2025 am 09:30 AM
Guide to Reinforcement Finetuning - Analytics VidhyaApr 28, 2025 am 09:30 AMReinforcement finetuning has shaken up AI development by teaching models to adjust based on human feedback. It blends supervised learning foundations with reward-based updates to make them safer, more accurate, and genuinely help
 Let's Dance: Structured Movement To Fine-Tune Our Human Neural NetsApr 27, 2025 am 11:09 AM
Let's Dance: Structured Movement To Fine-Tune Our Human Neural NetsApr 27, 2025 am 11:09 AMScientists have extensively studied human and simpler neural networks (like those in C. elegans) to understand their functionality. However, a crucial question arises: how do we adapt our own neural networks to work effectively alongside novel AI s


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

WebStorm Mac version
Useful JavaScript development tools

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

SublimeText3 Chinese version
Chinese version, very easy to use

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

