

 JavajavaTutorialWhat is the reason why Java cannot read non-text binary files using character streams
JavajavaTutorialWhat is the reason why Java cannot read non-text binary files using character streamsWhat is the reason why Java cannot read non-text binary files using character streams

Reading files
When I first learned the IO stream part of Java, the book said that only byte streams can be used to read non-text binary files such as pictures and videos, and character streams cannot be used, otherwise the files will be damage. So I have always remembered this, but why it cannot be used has always been a doubt of mine. Today, I thought about this problem again, so I might as well solve it in one go.
Let’s first look at a code example about copying images: Note: My computer has the path D:/DB. If you don’t have it, you must create one for the DB folder.
package dragon;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.nio.file.Path;
import java.nio.file.Paths;
public class ReadImage {
public static void main(String[] args) throws IOException {
String imgPath = "D:/DB/husky/kkk.jpeg";
String byteImgCopyPath = "D:/DB/husky/byteCopykkk.jpeg";
String charImgCopyPath = "D:/DB/husky/charCopykkk.jpeg";
Path srcPath = Paths.get(imgPath);
Path desPath2 = Paths.get(byteImgCopyPath);
Path desPath3 = Paths.get(charImgCopyPath);
byteRead(srcPath.toFile(), desPath2.toFile());
System.out.println("字节复制执行成功!");
characterRead(srcPath.toFile(), desPath3.toFile());
System.out.println("字符复制执行成功!");
}
static void byteRead(File src, File des) throws IOException {
try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream(src));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(des))) {
int hasRead = 0;
byte[] b = new byte[1024];
while ((hasRead = bis.read(b)) != -1) {
bos.write(b, 0, hasRead);
}
}
}
static void characterRead(File src, File des) throws IOException {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(src), "UTF-8"));
BufferedWriter writer = new BufferedWriter(new FileWriter(des))) {
int hasRead = 0;
char[] c = new char[1024];
while ((hasRead = reader.read(c)) != -1) {
writer.write(c, 0, hasRead);
}
}
}
}Run results: It can be seen that binary files such as images cannot be read using character streams, and byte streams must be used.

Picture size changes: It can be seen that the picture size changes after using the character stream, but not when using the byte stream.

Why is this so?
Through the above example, we can see that it is indeed impossible to copy files using character streams, and after using character streams to copy files, the size of the files will also change, which leads to the title we are going to discuss today.
Let’s first think about why text can be displayed when a text file is opened? We all know that the files processed by computers, whether text or non-text files, are ultimately stored in binary form inside the computer.
Use the hexadecimal mode of the text editor to open a text file:

Use the hexadecimal mode of the editor Open the picture file used by the above program in custom mode:
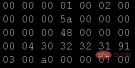
Comparing the data in the two pictures, you should not find any difference, but why can the text data be displayed? What about writing? This is a very basic question. This aspect is covered in basic courses in universities -Character Encoding Table. I first learned C language, and the earliest coding table I came into contact with was ASCII (American Standard Code for Information Interchange). Later, when I learned Java, I came into contact with Unicode (Universal Code). This name fits well with its origin. The most commonly used one at present is It is UTF-8, a variable-length character encoding for Unicode.)
Note: Using UTF-8 is also divided into BOM (Byte Order Mark, character Section order mark) and no two forms, and mixing them will lead to errors. If you are interested, you can learn about it.

The role of the character encoding table is reflected in the encoding. Quoting a passage from the encyclopedia:
The text seen on the monitor, Pictures and other information in the computer are not actually what we see. Even if you know that all the information is stored in the hard disk, you can't see anything inside when you take it apart, only some disks. Suppose you use a microscope to magnify the disk, and you will see that the surface of the disk is uneven. The convex places are magnetized, and the concave places are not magnetized. The convex places represent the number 1, and the concave places represent the number 0. The hard disk can only use 0 and 1 to represent all text, pictures and other information. So how is the letter "A" stored on the hard drive? Maybe Xiao Zhang's computer stores the letter "A" as 1100001, while Xiao Wang's computer stores the letter "A" as 11000010. In this way, the two parties will misunderstand when they exchange information. For example, Xiao Zhang sent 1100001 to Xiao Wang. Xiao Wang did not think that 1100001 was the letter "A", but probably thought it was the letter "X". So when Xiao Wang used Notepad to access 1100001 stored on the hard disk, an error message appeared on the screen. What is displayed is the letter "X". In other words, Xiao Zhang and Xiao Wang used different coding tables.
So the character encoding table is a one-to-one mapping between binary numbers and characters , for example, 65 (number) represents A, so the following code will be output on the screen A.
char c = 65; System.out.println(c);
Let’s use a loop to test it:
char c = 0;
for (int i = 9999; i < 10009; i++) {
c = (char) i;
System.out.print(c+" ");
}Test result: (Of course, this depends on your current character encoding table. If you use ASCII, it may be interesting.)

这样就解释了前面那个问题(为什么文本文件打开可以显示文字?),我们之所以可以看见文本文件的字符是因为计算机按照我们文件的编码(ASCII、UTF-8或者GBK等),从字符编码表中找出来对应的字符。 所以,当我们使用记事本打开二进制文件会看到乱码,这就是原因。文件的复制过程也是复制的二进制数据,而不是真实的文字。
因此可以这样理解文件复制的过程:
字符流:二进制数据 --编码-> 字符编码表 --解码-> 二进制数据
字节流:二进制数据 —> 二进制数据
所以问题就是出现在编码和解码的过程中,既然是字符的编码表,那它就是包含所有的字符,但是字符的数量是有限的,这就意味着它不能表示一些超过编码表的字符,因为根本不存在表中。所以,JVM 会使用一些字符进行替换,基本上都是乱码(所以大小会发生变化),而且如果有一个数据恰好是-1,那么读取就会中断,引起数据丢失。
例如如下代码使用字符流读取就会错误:
String filename = "D:/DB/fos.txt"; //文件名
byte[] b = new byte[] {-1, -1}; //两个字节,127的二进制就是 1111 1111
//数据写入文件
try (FileOutputStream fos = new FileOutputStream(filename)) {
fos.write(b, 0, b.length); //将两个127连续写入,就是 1111 1111 1111 1111
}
File file = new File(filename);
//输出文件的大小
System.out.println("file length: " + file.length());
char[] c = new char[2];
//使用字符流读取文件
try (FileReader reader = new FileReader(filename)) {
int count = reader.read(c); //Java使用Unicode编码,读取的是从 0-65535 之间的数字。
System.out.println("以文本形式输出:" + new String(c, 0, count)+" "+count);
for (char d : c) {
System.out.println("字符为:" + d);
}
}
System.out.println("表示字符:" + c[0]);
//再写入文件
try (FileWriter writer = new FileWriter(filename)) {
writer.write(c, 0, 2);
}
File f = new File(filename);
System.out.println("file length: " + f.length());结果:

说明: 我将两个1字节的-1写入(字节流)了文本文件(注意是字节:-1,不是字符:-1),然后再读取(字符流),再写入(字符流)就已经出现了问题。读取出的字符显示了一个奇怪的符号,而且它的值为:65533,这个值如果用字节表示的话,一个字节是不够的,所以文件的大小就会变化。在非文本的二进制数据中,出现这种情况都是正常的,因为本来就不是按照字符编码的。
因为字符都是正数,而非字符编码的话,字节数可能是负数(很可能),但是负数在字符看来就是正数,这也是为什么-1,被读成 65533的原因。可以看出来,读取就已经错误了。
注意: 这里的重点是对于使用字符流读取非文本文件,在读取-写入的过程中的问题。
The above is the detailed content of What is the reason why Java cannot read non-text binary files using character streams. For more information, please follow other related articles on the PHP Chinese website!

 JVM performance vs other languagesMay 14, 2025 am 12:16 AM
JVM performance vs other languagesMay 14, 2025 am 12:16 AMJVM'sperformanceiscompetitivewithotherruntimes,offeringabalanceofspeed,safety,andproductivity.1)JVMusesJITcompilationfordynamicoptimizations.2)C offersnativeperformancebutlacksJVM'ssafetyfeatures.3)Pythonisslowerbuteasiertouse.4)JavaScript'sJITisles
 Java Platform Independence: Examples of useMay 14, 2025 am 12:14 AM
Java Platform Independence: Examples of useMay 14, 2025 am 12:14 AMJavaachievesplatformindependencethroughtheJavaVirtualMachine(JVM),allowingcodetorunonanyplatformwithaJVM.1)Codeiscompiledintobytecode,notmachine-specificcode.2)BytecodeisinterpretedbytheJVM,enablingcross-platformexecution.3)Developersshouldtestacross
 JVM Architecture: A Deep Dive into the Java Virtual MachineMay 14, 2025 am 12:12 AM
JVM Architecture: A Deep Dive into the Java Virtual MachineMay 14, 2025 am 12:12 AMTheJVMisanabstractcomputingmachinecrucialforrunningJavaprogramsduetoitsplatform-independentarchitecture.Itincludes:1)ClassLoaderforloadingclasses,2)RuntimeDataAreafordatastorage,3)ExecutionEnginewithInterpreter,JITCompiler,andGarbageCollectorforbytec
 JVM: Is JVM related to the OS?May 14, 2025 am 12:11 AM
JVM: Is JVM related to the OS?May 14, 2025 am 12:11 AMJVMhasacloserelationshipwiththeOSasittranslatesJavabytecodeintomachine-specificinstructions,managesmemory,andhandlesgarbagecollection.ThisrelationshipallowsJavatorunonvariousOSenvironments,butitalsopresentschallengeslikedifferentJVMbehaviorsandOS-spe
 Java: Write Once, Run Anywhere (WORA) - A Deep Dive into Platform IndependenceMay 14, 2025 am 12:05 AM
Java: Write Once, Run Anywhere (WORA) - A Deep Dive into Platform IndependenceMay 14, 2025 am 12:05 AMJava implementation "write once, run everywhere" is compiled into bytecode and run on a Java virtual machine (JVM). 1) Write Java code and compile it into bytecode. 2) Bytecode runs on any platform with JVM installed. 3) Use Java native interface (JNI) to handle platform-specific functions. Despite challenges such as JVM consistency and the use of platform-specific libraries, WORA greatly improves development efficiency and deployment flexibility.
 Java Platform Independence: Compatibility with different OSMay 13, 2025 am 12:11 AM
Java Platform Independence: Compatibility with different OSMay 13, 2025 am 12:11 AMJavaachievesplatformindependencethroughtheJavaVirtualMachine(JVM),allowingcodetorunondifferentoperatingsystemswithoutmodification.TheJVMcompilesJavacodeintoplatform-independentbytecode,whichittheninterpretsandexecutesonthespecificOS,abstractingawayOS
 What features make java still powerfulMay 13, 2025 am 12:05 AM
What features make java still powerfulMay 13, 2025 am 12:05 AMJavaispowerfulduetoitsplatformindependence,object-orientednature,richstandardlibrary,performancecapabilities,andstrongsecurityfeatures.1)PlatformindependenceallowsapplicationstorunonanydevicesupportingJava.2)Object-orientedprogrammingpromotesmodulara
 Top Java Features: A Comprehensive Guide for DevelopersMay 13, 2025 am 12:04 AM
Top Java Features: A Comprehensive Guide for DevelopersMay 13, 2025 am 12:04 AMThe top Java functions include: 1) object-oriented programming, supporting polymorphism, improving code flexibility and maintainability; 2) exception handling mechanism, improving code robustness through try-catch-finally blocks; 3) garbage collection, simplifying memory management; 4) generics, enhancing type safety; 5) ambda expressions and functional programming to make the code more concise and expressive; 6) rich standard libraries, providing optimized data structures and algorithms.


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

SublimeText3 Chinese version
Chinese version, very easy to use

WebStorm Mac version
Useful JavaScript development tools

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver Mac version
Visual web development tools

