

 Technology peripheralsAIGoogle expanded the visual transfer model parameters to 22 billion, and researchers took collective action since ChatGPT became popular
Technology peripheralsAIGoogle expanded the visual transfer model parameters to 22 billion, and researchers took collective action since ChatGPT became popularGoogle expanded the visual transfer model parameters to 22 billion, and researchers took collective action since ChatGPT became popular

Similar to natural language processing, transfer of pre-trained visual backbones improves model performance on a variety of visual tasks. Larger data sets, scalable architectures, and new training methods have all driven improvements in model performance.
However, visual models still lag far behind language models. Specifically, ViT, the largest vision model to date, only has 4B parameters, while entry-level language models often exceed 10B parameters, let alone large language models with 540B parameters.
In order to explore the performance limits of AI models, Google Research recently conducted a study in the field of CV, taking the lead in expanding the Vision Transformer parameter size to 22B and proposing ViT-22B, which is similar to the previous one. Compared with the model parameter amount of 4B, it can be said that this is the largest dense ViT model so far.

Paper address: https://arxiv.org/pdf/2302.05442.pdf
Comparing the previous largest ViT-G and ViT-e, Table 1 gives the comparison results. From the following table, it can be seen that ViT-22B mainly expands the width of the model, making the parameters The volume is larger and the depth is the same as ViT-G.

##The current ViT large model
As this Zhihu netizen said, could it be that Google lost a round on ChatGPT and is bound to compete in the CV field?

How to do it? It turned out that in the early stages of the research, they discovered that training instability occurred during the expansion of ViT, which may lead to architectural changes. The researchers then carefully designed the model and trained it in parallel with unprecedented efficiency. The quality of ViT-22B was assessed through a comprehensive set of tasks, from (few-shot) classification to dense output tasks, where it met or exceeded current SOTA levels. For example, ViT-22B achieved 89.5% accuracy on ImageNet even when used as a frozen visual feature extractor. By training a text tower to match these visual features, it achieves 85.9% zero-shot accuracy on ImageNet. In addition, the model can be regarded as a teacher and used as a distillation target. The researchers trained a ViT-B student model and achieved an accuracy of 88.6% on ImageNet, reaching the SOTA level for a model of this scale.
Model ArchitectureViT-22B is a Transformer-based encoder model similar to the original Vision Transformer architecture, but contains the following three major modifications to improve Efficiency and stability in large-scale training: parallel layers, query/key (QK) normalization and omitted biases.
Parallel layer. As stated in the Wang and Komatsuzaki study, which designed a parallel structure of Attention and MLP:

This can be achieved by combining Linear projection of MLP and attention blocks to achieve additional parallelization. Notably, matrix multiplication for query/key/value projection and the first linear layer of MLP are fused into a single operation, as is the case for out-of-attention projection and the second linear layer of MLP.
QK Normalization. One difficulty in training large models is the stability of the model. In the process of extending ViT, researchers found that the training loss diverges after thousands of rounds of steps. This phenomenon is particularly prominent in the 8B parameter model. To stabilize model training, the researchers adopted the method of Gilmer et al. to apply LayerNorm normalization operations on queries and keys before dot product attention calculations to improve training stability. Specifically, the attention weight is calculated as:

omitted biases. After PaLM, the bias term is removed from the QKV projection and all layernorms are applied without bias, resulting in improved accelerator utilization (3%) without quality degradation. However, unlike PaLM, the researchers used a bias term for the MLP dense layer, and even so, this approach did not compromise speed while taking into account quality.
Figure 2 shows a ViT-22B encoder block. The embedding layer performs operations such as patch extraction, linear projection, and added position embedding based on the original ViT. The researchers used multi-head attention pooling to aggregate each token representation in the heads.

ViT-22B uses a 14 × 14 patch and an image resolution of 224 × 224. ViT-22B employs a learned one-dimensional position embedding. During fine-tuning on high-resolution images, the researchers performed two-dimensional interpolation based on where the pre-trained position embeddings were in the original image.
Training Infrastructure and Efficiency
ViT-22B uses the FLAX library, implemented as JAX, and built in Scenic. It exploits both model and data parallelism. Notably, the researchers used the jax.xmap API, which provides explicit control over sharding of all intermediates (such as weights and activations) as well as inter-chip communication. The researchers organized the chips into a 2D logical grid of size t × k, where t is the size of the data parallel axis and k is the size of the model axis. Then, for each of t groups, k devices acquire the same batch of images, with each device retaining only 1/k activations and being responsible for computing 1/k of all linear layer outputs (details below).

Figure 3: Asynchronous parallel linear operations (y = Ax): overlapping communication and computation across devices Model for parallel matrix multiplication.
Asynchronous parallel linear operations. To maximize throughput, computation and communication must be considered. That is, if you want these operations to be analytically equivalent to the unsharded case, you have to communicate as little as possible, ideally letting them overlap so that you can preserve the matrix multiplication unit (where most of the FLOP's capacity resides) ) is always busy.
Parameter sharding. The model is data parallel in the first axis. Each parameter can be fully replicated on this axis, or each device can be saved with a chunk of it. The researchers chose to split some large tensors from the model parameters to be able to fit larger models and batch sizes.
Using these techniques, ViT-22B processes 1.15k tokens per second per core during training on TPUv4. The model flops utilization (MFU) of ViT-22B is 54.9%, indicating a very efficient use of the hardware. Note that PaLM reports an MFU of 46.2%, while the researchers measured an MFU of 44.0% for ViT-e (data parallelism only) on the same hardware.
Experimental results
The experiment explores the evaluation results of ViT-22B for image classification.
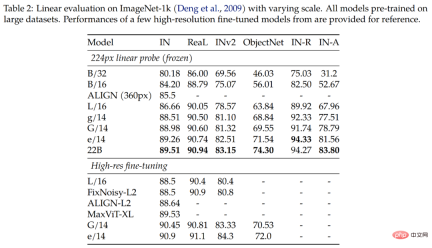
The results in Table 2 show that ViT-22B still has significant improvements in various indicators. Furthermore, studies have shown that linear probing of large models like the ViT-22B can approach or exceed the full fine-tuning performance of smaller models with high resolution, which is often cheaper and easier to do.
The study further tests linear separability on the fine-grained classification data set iNaturalist 2017, comparing ViT-22B with other ViT variants for comparison. The study tested input resolutions of 224px and 384px. The results are shown in Figure 4. The study observed that ViT-22B significantly outperforms other ViT variants, especially at the standard 224px input resolution. This shows that the large number of parameters in ViT-22B is useful for extracting detailed information from images.

Table 3 shows the zero-sample migration results of ViT-22B for CLIP, ALIGN, BASIC, CoCa, and LiT models. The bottom of Table 3 compares the three ViT model performances.
ViT-22B achieves comparable or better results in all ImageNet test sets. Notably, the zero-shot results on the ObjectNet test set are highly correlated with the ViT model size. The largest, ViT-22B, sets a new state-of-the-art on the challenging ObjectNet test set.

Out-of-distribution (OOD). The study constructs a label mapping from JFT to ImageNet, and a label mapping from ImageNet to different out-of-distribution datasets, namely ObjectNet, ImageNet-v2, ImageNet- R, and ImageNet- A.
The results that can be confirmed so far are that, consistent with the improvements on ImageNet, the extended model increases out-of-distribution performance. This works for models that have only seen JFT images, as well as models fine-tuned on ImageNet. In both cases, ViT-22B continues the trend of better OOD performance on larger models (Fig. 5, Table 11).

In addition, the researchers also studied the performance of the ViT-22B model captured in semantic segmentation and monocular depth estimation tasks. Geometric and spatial information quality.
Semantic segmentation. The researchers evaluated ViT-22B as a semantic segmentation backbone on three benchmarks: ADE20K, Pascal Context, and Pascal VOC. As can be seen from Table 4, ViT-22B backbone migration works better when only a few segmentation masks are seen.

Monocular depth estimation. Table 5 summarizes the main findings of the study. As can be observed from the top row (DPT decoder), using ViT-22B features yields the best performance (on all metrics) compared to different backbones. By comparing the ViT-22B backbone to ViT-e, a smaller model but trained on the same data as ViT-22B, we found that extending the architecture improves performance.
In addition, comparing the ViT-e backbone with ViT-L (a similar architecture to ViT-e, but with less training data), the study found that these improvements also come from extensions Data before training. These findings suggest that both larger models and larger datasets help improve performance.

The study also explored on a video dataset. Table 6 shows video classification results on the Kinetics 400 and Moments in Time datasets, demonstrating that competitive results can be achieved using frozen backbones. The study first compares with ViT-e, which has the largest prior visual backbone model consisting of 4 billion parameters and is also trained on the JFT dataset. We observed that the larger ViT-22B model improved by 1.5 points on Kinetics 400 and 1.3 points on Moments in Time.
Final research noted that there is room for further improvement through complete end-to-end fine-tuning.

Please refer to the original paper for more technical details.
The above is the detailed content of Google expanded the visual transfer model parameters to 22 billion, and researchers took collective action since ChatGPT became popular. For more information, please follow other related articles on the PHP Chinese website!

 A Comprehensive Guide to ExtrapolationApr 15, 2025 am 11:38 AM
A Comprehensive Guide to ExtrapolationApr 15, 2025 am 11:38 AMIntroduction Suppose there is a farmer who daily observes the progress of crops in several weeks. He looks at the growth rates and begins to ponder about how much more taller his plants could grow in another few weeks. From th
 The Rise Of Soft AI And What It Means For Businesses TodayApr 15, 2025 am 11:36 AM
The Rise Of Soft AI And What It Means For Businesses TodayApr 15, 2025 am 11:36 AMSoft AI — defined as AI systems designed to perform specific, narrow tasks using approximate reasoning, pattern recognition, and flexible decision-making — seeks to mimic human-like thinking by embracing ambiguity. But what does this mean for busine
 Evolving Security Frameworks For The AI FrontierApr 15, 2025 am 11:34 AM
Evolving Security Frameworks For The AI FrontierApr 15, 2025 am 11:34 AMThe answer is clear—just as cloud computing required a shift toward cloud-native security tools, AI demands a new breed of security solutions designed specifically for AI's unique needs. The Rise of Cloud Computing and Security Lessons Learned In th
 3 Ways Generative AI Amplifies Entrepreneurs: Beware Of Averages!Apr 15, 2025 am 11:33 AM
3 Ways Generative AI Amplifies Entrepreneurs: Beware Of Averages!Apr 15, 2025 am 11:33 AMEntrepreneurs and using AI and Generative AI to make their businesses better. At the same time, it is important to remember generative AI, like all technologies, is an amplifier – making the good great and the mediocre, worse. A rigorous 2024 study o
 New Short Course on Embedding Models by Andrew NgApr 15, 2025 am 11:32 AM
New Short Course on Embedding Models by Andrew NgApr 15, 2025 am 11:32 AMUnlock the Power of Embedding Models: A Deep Dive into Andrew Ng's New Course Imagine a future where machines understand and respond to your questions with perfect accuracy. This isn't science fiction; thanks to advancements in AI, it's becoming a r
 Is Hallucination in Large Language Models (LLMs) Inevitable?Apr 15, 2025 am 11:31 AM
Is Hallucination in Large Language Models (LLMs) Inevitable?Apr 15, 2025 am 11:31 AMLarge Language Models (LLMs) and the Inevitable Problem of Hallucinations You've likely used AI models like ChatGPT, Claude, and Gemini. These are all examples of Large Language Models (LLMs), powerful AI systems trained on massive text datasets to
 The 60% Problem — How AI Search Is Draining Your TrafficApr 15, 2025 am 11:28 AM
The 60% Problem — How AI Search Is Draining Your TrafficApr 15, 2025 am 11:28 AMRecent research has shown that AI Overviews can cause a whopping 15-64% decline in organic traffic, based on industry and search type. This radical change is causing marketers to reconsider their whole strategy regarding digital visibility. The New
 MIT Media Lab To Put Human Flourishing At The Heart Of AI R&DApr 15, 2025 am 11:26 AM
MIT Media Lab To Put Human Flourishing At The Heart Of AI R&DApr 15, 2025 am 11:26 AMA recent report from Elon University’s Imagining The Digital Future Center surveyed nearly 300 global technology experts. The resulting report, ‘Being Human in 2035’, concluded that most are concerned that the deepening adoption of AI systems over t


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SublimeText3 Chinese version
Chinese version, very easy to use

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

WebStorm Mac version
Useful JavaScript development tools

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

