

 Technology peripheralsAIThe global stock of high-quality language data is in short supply and cannot be ignored
Technology peripheralsAIThe global stock of high-quality language data is in short supply and cannot be ignoredThe global stock of high-quality language data is in short supply and cannot be ignored

As one of the three elements of artificial intelligence, data plays an important role.
But have you ever thought about: What if one day, all the data in the world is used up?
Actually, the person who asked this question definitely has no mental problem, because this day may be coming soon! ! !
Recently, researcher Pablo Villalobos and others published an article titled "Will We Run Out of Data?" The paper "Analysis of the Limitations of Dataset Scaling in Machine Learning" was published on arXiv.
Based on their previous analysis of data set size trends, they predicted the growth of data set sizes in the language and vision fields and estimated the development trend of the total stock of available unlabeled data in the next few decades. .
Their research shows that high-quality language data will be exhausted as early as 2026! The pace of machine learning development will also slow down as a result. It's really not optimistic.
Two methods are used in both directions, but the results are not optimistic
The research team of this paper consists of 11 researchers and 3 consultants, with members from all over the world, dedicated to shrinking AI Gap between technology development and AI strategy, and provide advice to key decision-makers on AI safety.

Chinchilla is a new predictive computing optimization model proposed by researchers at DeepMind.
In fact, during previous experiments on Chinchilla, a researcher once suggested that "training data will soon become a bottleneck in expanding large language models."
So they analyzed the growth in the size of machine learning datasets for natural language processing and computer vision, and used two methods to extrapolate: using historical growth rates, and for the future The predicted computational budget is estimated to calculate the optimal data set size.
Prior to this, they have been collecting data on machine learning input trends, including some training data, etc., and also by estimating the total stock of unlabeled data available on the Internet in the next few decades. , to investigate data usage growth.
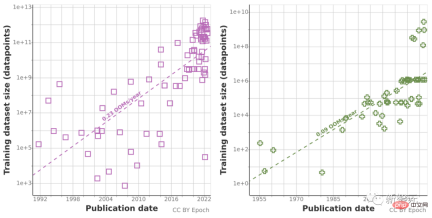
Because historical forecast trends may be "misleading" by the abnormal growth in computing volume over the past decade, the research team also used Chinchilla scaling law to Estimate the size of the data set in the next few years to improve the accuracy of the calculation results.
Ultimately, the researchers used a series of probabilistic models to estimate the total inventory of English language and image data in the next few years and compared the predictions of training data set size and total data inventory. The results are as follows As shown in the figure.

This shows that the growth rate of the data set will be much faster than the data storage.
Therefore, if the current trend continues, it will be inevitable that the data stock will be used up. The table below shows the median number of years to exhaustion at each intersection on the forecast curve.
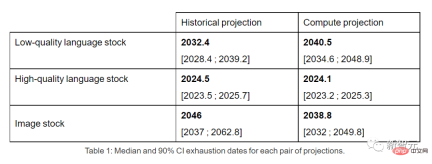
High-quality language data inventories may be exhausted by 2026 at the earliest.
In contrast, the situation of low-quality language data and image data is slightly better: the former will be used up between 2030 and 2050, and the latter will be used up between 2030 and 2060. between.
At the end of the paper, the research team concluded: If data efficiency is not significantly improved or new data sources are available, the growth trend of machine learning models that currently rely on the ever-expanding huge data sets is likely to slow down. slow.
Netizens: Worrying is unfounded, let’s find out more about Efficient Zero
However, in the comment area of this article, most netizens think that the author is unfounded.
On Reddit, a netizen named ktpr said:
"What's wrong with self-supervised learning? If the tasks are well specified , it can even be combined to expand the data set size."

A netizen named lostmsn was even more unkind. He said bluntly:
"You don't even understand Efficient Zero? I think the author has seriously lost touch with the times."
Efficient Zero is a reinforcement learning algorithm that can efficiently sample, proposed by Dr. Gao Yang of Tsinghua University.
In the case of limited data volume, Efficient Zero has solved the performance problem of reinforcement learning to a certain extent, and has been verified on the Atari Game, a universal test benchmark for algorithms.
On the blog of the author team of this paper, even they themselves admitted:
"All of our conclusions are based on the unrealistic assumption that current trends in machine learning data usage and production will continue without significant improvements in data efficiency."
"A more reliable model should take into account the improvement of machine learning data efficiency, the use of synthetic data, and other algorithmic and economic factors."
"So in practical terms, this This analysis has serious limitations. Model uncertainty is very high."
"However, overall, we still believe that by 2040, due to the lack of training data, machine learning models There is about a 20% chance that the expansion will slow down significantly."
The above is the detailed content of The global stock of high-quality language data is in short supply and cannot be ignored. For more information, please follow other related articles on the PHP Chinese website!

 The Hidden Dangers Of AI Internal Deployment: Governance Gaps And Catastrophic RisksApr 28, 2025 am 11:12 AM
The Hidden Dangers Of AI Internal Deployment: Governance Gaps And Catastrophic RisksApr 28, 2025 am 11:12 AMThe unchecked internal deployment of advanced AI systems poses significant risks, according to a new report from Apollo Research. This lack of oversight, prevalent among major AI firms, allows for potential catastrophic outcomes, ranging from uncont
 Building The AI PolygraphApr 28, 2025 am 11:11 AM
Building The AI PolygraphApr 28, 2025 am 11:11 AMTraditional lie detectors are outdated. Relying on the pointer connected by the wristband, a lie detector that prints out the subject's vital signs and physical reactions is not accurate in identifying lies. This is why lie detection results are not usually adopted by the court, although it has led to many innocent people being jailed. In contrast, artificial intelligence is a powerful data engine, and its working principle is to observe all aspects. This means that scientists can apply artificial intelligence to applications seeking truth through a variety of ways. One approach is to analyze the vital sign responses of the person being interrogated like a lie detector, but with a more detailed and precise comparative analysis. Another approach is to use linguistic markup to analyze what people actually say and use logic and reasoning. As the saying goes, one lie breeds another lie, and eventually
 Is AI Cleared For Takeoff In The Aerospace Industry?Apr 28, 2025 am 11:10 AM
Is AI Cleared For Takeoff In The Aerospace Industry?Apr 28, 2025 am 11:10 AMThe aerospace industry, a pioneer of innovation, is leveraging AI to tackle its most intricate challenges. Modern aviation's increasing complexity necessitates AI's automation and real-time intelligence capabilities for enhanced safety, reduced oper
 Watching Beijing's Spring Robot RaceApr 28, 2025 am 11:09 AM
Watching Beijing's Spring Robot RaceApr 28, 2025 am 11:09 AMThe rapid development of robotics has brought us a fascinating case study. The N2 robot from Noetix weighs over 40 pounds and is 3 feet tall and is said to be able to backflip. Unitree's G1 robot weighs about twice the size of the N2 and is about 4 feet tall. There are also many smaller humanoid robots participating in the competition, and there is even a robot that is driven forward by a fan. Data interpretation The half marathon attracted more than 12,000 spectators, but only 21 humanoid robots participated. Although the government pointed out that the participating robots conducted "intensive training" before the competition, not all robots completed the entire competition. Champion - Tiangong Ult developed by Beijing Humanoid Robot Innovation Center
 The Mirror Trap: AI Ethics And The Collapse Of Human ImaginationApr 28, 2025 am 11:08 AM
The Mirror Trap: AI Ethics And The Collapse Of Human ImaginationApr 28, 2025 am 11:08 AMArtificial intelligence, in its current form, isn't truly intelligent; it's adept at mimicking and refining existing data. We're not creating artificial intelligence, but rather artificial inference—machines that process information, while humans su
 New Google Leak Reveals Handy Google Photos Feature UpdateApr 28, 2025 am 11:07 AM
New Google Leak Reveals Handy Google Photos Feature UpdateApr 28, 2025 am 11:07 AMA report found that an updated interface was hidden in the code for Google Photos Android version 7.26, and each time you view a photo, a row of newly detected face thumbnails are displayed at the bottom of the screen. The new facial thumbnails are missing name tags, so I suspect you need to click on them individually to see more information about each detected person. For now, this feature provides no information other than those people that Google Photos has found in your images. This feature is not available yet, so we don't know how Google will use it accurately. Google can use thumbnails to speed up finding more photos of selected people, or may be used for other purposes, such as selecting the individual to edit. Let's wait and see. As for now
 Guide to Reinforcement Finetuning - Analytics VidhyaApr 28, 2025 am 09:30 AM
Guide to Reinforcement Finetuning - Analytics VidhyaApr 28, 2025 am 09:30 AMReinforcement finetuning has shaken up AI development by teaching models to adjust based on human feedback. It blends supervised learning foundations with reward-based updates to make them safer, more accurate, and genuinely help
 Let's Dance: Structured Movement To Fine-Tune Our Human Neural NetsApr 27, 2025 am 11:09 AM
Let's Dance: Structured Movement To Fine-Tune Our Human Neural NetsApr 27, 2025 am 11:09 AMScientists have extensively studied human and simpler neural networks (like those in C. elegans) to understand their functionality. However, a crucial question arises: how do we adapt our own neural networks to work effectively alongside novel AI s


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

WebStorm Mac version
Useful JavaScript development tools

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

SublimeText3 Chinese version
Chinese version, very easy to use

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

