

 Technology peripheralsAIA review of research progress of deep learning in time series prediction and classification in 2022
Technology peripheralsAIA review of research progress of deep learning in time series prediction and classification in 2022A review of research progress of deep learning in time series prediction and classification in 2022

The decline of transformers in time series prediction and the rise of time series embedding methods, as well as anomaly detection and classification have also made progress
The entire field has made progress in several different aspects in 2022. This article will Try to cover some of the more promising and key papers that have emerged in the past year or so, as well as the Flow Forecast [FF] forecasting framework.

Time Series Forecasting
1. Are Transformers Really Effective for Time Series Forecasting?
https://www.php.cn/link/bf4d73f316737b26f1e860da0ea63ec8
Transformer related research compares Autoformer, Pyraformer, Fedformer, etc., their effects and problems
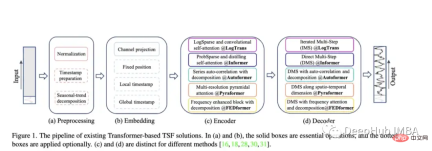
With the emergence of models such as Autoformer (Neurips 2021), Pyraformer (ICLR 2022), Fedformer (ICML 2022), EarthFormer (Neurips 2022), and Non-Stationary Transformer (Neurips), time series The Transformer family of predictive architectures continues to grow). But the ability of these models to accurately predict data and outperform existing methods remains in question, especially in light of new research (which we'll discuss later).
Autoformer: Extended and improved performance of the Informer model. Autoformer features an automatic correlation mechanism that enables the model to learn temporal dependencies better than standard attention. It aims to accurately decompose the trend and seasonal components of temporal data.

Pyraformer: The author introduces the "Pyramid Attention Module (PAM), in which the inter-scale tree structure summarizes the features at different resolutions, and the intra-scale adjacent connections pair different ranges Modeling the temporal dependence of time series.”
Fedformer: This model focuses on capturing global trends in time series data. The authors propose a seasonal trend decomposition module designed to capture the global characteristics of time series.
Earthformer: Probably the most unique of these papers, it focuses specifically on predicting Earth systems such as weather, climate, and agriculture. A new cuboid attention architecture is introduced. This paper should have great potential, because many classic Transformers have failed in research on river and flash flood prediction.
Non-Stationary Transformer: This is the latest paper using transformer for prediction. The authors aim to better tune the Transformer to handle non-stationary time series. They employ two mechanisms: destabilizing attention and a series of stabilizing mechanisms. These mechanisms can be plugged into any existing Transformer model, and the author has tested that plugging them into Informer, Autoformer, and traditional Transformer can improve performance (in the appendix, it is also shown that it can improve the performance of Fedformer).
Evaluation methodology of the paper: Similar to Informer, all these models (except Earthformer) are evaluated on electricity, transportation, finance and weather datasets. Mainly evaluated based on the mean square error (MSE) and mean absolute error (MAE) indicators:

This paper is very good, but it only compares papers related to Transformer. In fact, it should be compared with simpler methods, such as simple linear regression, LSTM/GRU, or even tree models such as XGB. Another thing is that they should not be limited to some standard data sets, because I have not seen good performance on other time series related data sets. For example, informers have huge problems accurately predicting river flow, and their performance is often poor compared to LSTM or even ordinary Transformers.
In addition, because unlike computer vision, image dimensions remain at least constant, time series data can vary greatly in length, periodicity, trend, and seasonality, so a larger range of data sets is required.
In the review for OpenReview's Non-Stationary Transformer, one commenter also expressed these issues, but it was downvoted in the final meta-review:
"Since the model belongs Transformer field, and Transformer has previously shown state-of-the-art performance in many tasks, I think there is no need to compare with other 'family' methods."
This is a very problematic argument, and leads to Research lacks applicability to the real world. As we all know: XGB's overwhelming advantage in tabular data has not changed, so what's the point of Transformer working behind closed doors? Surpassed every time and was beaten every time.
As someone who values state-of-the-art methods and innovative models in practice, when I spent months trying to get a so-called "good" model to work, I found out in the end that its performance was not as good as Simple linear regression, what's the point of these few months? What’s the point of this so-called good” model?
All transformer papers suffer from the same problem of limited evaluation. We should demand more rigorous comparisons and clear explanation of shortcomings from the beginning. A complex The model may not always initially outperform the simple model, but this needs to be explicitly stated in the paper, rather than glossed over or simply assumed that this is not the case.
But the paper is still very good, e.g. Earthformer was evaluated on the MovingMNIST data set and the N-body MNIST data set. The author used it to verify the effectiveness of cuboid attention and evaluated its precipitation immediate forecast and El Niño cycle forecast. I think it is a good one Example, integrate physical knowledge into a model architecture with attention, and then design good tests.
2. Are Transformers Effective for Time Series Forecasting (2022)?
https://www.php.cn/link/bf4d73f316737b26f1e860da0ea63ec8
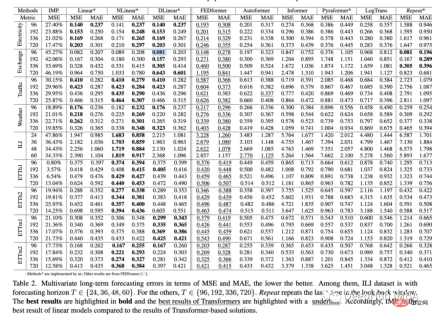
This paper explores the ability of Transformer to predict data versus baseline methods. Results This somewhat reaffirms that Transformers often perform worse than simpler models and are difficult to tune. A couple of interesting points from the paper: Attention and found: "The performance of Informer grows with progressive simplification, indicating that self-attention schemes and other complex modules are unnecessary, at least for existing LTSF benchmarks"
- Investigated adding backtracking whether windowing (look-back window) would improve the performance of Transformers and found: "The performance of SOTA Transformers dropped slightly, indicating that these models only capture similar temporal information from adjacent time series sequences. ”
- explored whether positional embeddings really capture the temporal order of time series well. They did this by randomly shuffling the input sequence into a Transformer. They found this on several datasets This reorganization did not affect the results (this coding is very troublesome).
- In the past few years, countless time series experiments of the Transformer model have resulted in unsatisfactory results in the vast majority of cases. In For a long time, we thought we must have done something wrong, or missed some small implementation details. All of these were considered ideas for the next SOTA model. But this paper has a consistent idea: If a Simple models outperform Transformers, should we continue to use them? Are all Transformers inherently flawed, or is it just the current mechanism? Should we go back to architectures like lstm, GRU, or simple feedforward models? These questions I don't even know the answer, but the overall impact of this paper remains to be seen. So far, I think the answer might be to take a step back and focus on learning efficient time series representations. After all, BERT initially succeeded in forming well in the NLP context representation.
https://www.php.cn/link/ab22e28b58c1e3de6bcef48d3f5d8b4a
This article evaluates the model's performance on five real-world datasets, including Server Machine Dataset, Pooled Server Metrics, Soil Moisture Active Passive and NeurIPS-TS (which itself consists of five different datasets). While one might be skeptical of this model, especially regarding the second paper's point of view, this assessment is quite rigorous. Neurips-TS is a recently created dataset specifically designed to provide more rigorous evaluation of anomaly detection models. This model does seem to improve performance compared to simpler anomaly detection models.
The authors propose a unique unsupervised Transformer that performs well on a plethora of anomaly detection datasets. This is one of the most promising papers in the field of time series Transformers in the past few years. Because prediction is more challenging than classification or even anomaly detection because you are trying to predict a huge range of possible values multiple time steps into the future. So much research has focused on prediction, while ignoring classification or anomaly detection. Should we start simple for Transformer?
4. WaveBound: Dynamic Error Bounds for Stable Time Series Forecasting (Neurips 2022):
##https://www.php.cn/link/ae95296e27d7f695f891cd26b4f37078
The paper introduces a new form of regularization that can improve the training of deep time series prediction models (especially the transformers mentioned above). The authors evaluate by inserting it into the existing transformer LSTNet model. They found that it significantly improved performance in most cases. Although they only tested the Autoformer model and not newer models like Fedformer. New forms of regularization or loss functions are always useful because they can usually be plugged into any existing time series model. If you combine Fedformer non-stationary mechanisms with Wavebound, you might beat simple linear regression in performance :). Time Series RepresentationAlthough Transformer does not perform well in the prediction direction, Transformer has made a lot of progress in creating useful time series representations. I think this is an impressive new area in the field of time series deep learning that should be explored more deeply. 5. TS2Vec: Towards Universal Representation of Time Series (AAAI 2022)https://www.php.cn/link/7690dd4db7a92524c684e3191919eb6b
TS2Vec is a general framework for learning time series representation/embedding. The paper itself is somewhat dated, but it did start a trend of time series representation learning papers. Evaluated using representations for prediction and anomaly detection, the model outperforms many models such as Informer and Log Transformer. 6、Learning Latent Seasonal-Trend Representations for Time Series Forecasting(Neurips 2022)https://www.php.cn/link/0c5534f554a26f7aeb7c780e12bb1525


https://www.php.cn/link/791d3a0048b9c200dceca07f99ddd178
This is a paper published at ICLR earlier in 2022, which is very similar to LaST in terms of learning season and trend representation. Since LaST has largely replaced its performance, I won't go into too much description here. But the link is above for those who want to read it.Other interesting papers
8. Domain Adaptation for Time Series Forecasting via Attention Sharing(ICML 2022)
https://www.php.cn/link /d4ea5dacfff2d8a35c0952291779290d

Prediction is a challenge for DNN when there is a lack of training data. This paper uses a shared attention layer for domains with rich data, and then separate modules for target domains.
The proposed model is evaluated using synthetic and real data sets. In a synthetic environment, cold-start learning and few-shot learning were tested and their models were found to outperform plain Transformer and DeepAR. For the real dataset Kaggle retail dataset was adopted and the model significantly outperformed the baseline in these experiments.
Cold start, few samples, and limited learning are extremely important topics, but few papers deal with time series. This model provides an important step toward addressing some of these issues. This means they can be evaluated on more diverse limited real-world data sets and compared to more baseline models. The benefit of fine-tuning or regularization is that it can be adjusted for any architecture.
9、When to Intervene: Learning Optimal Intervention Policies for Critical Events (Neurips 2022)
https://www.php.cn/link/f38fef4c0e4988792723c29a0bd3ca98
Although this is not a "typical" time series paper, I chose to include it in this list because the focus of the paper is on finding the best time to intervene before a machine fails. This is called OTI or Optimal Time to Intervention
One of the problems with evaluating OTI is the accuracy of the underlying survival analysis (if it is incorrect, the assessment will also be incorrect). The authors evaluated their model against two static thresholds, found that it performed well, and plotted the expected performance and hit-to-fail ratio for different policies.
This is an interesting problem and the authors propose a novel solution, with one commenter on Openreview stating: "If there was a graph showing the trade-off between failure probability and expected intervention time, the experiment might It will be more convincing, so that people can intuitively see the shape of this trade-off curve."
Recent Datasets/Benchmarks
The last is the benchmark for testing the data set
Monash Time Series Forecasting Archive (Neurips 2021): This archive is intended to form a "master list" of different time series datasets and provide a more authoritative benchmark. The repository contains over 20 different datasets spanning multiple industries including health, retail, ridesharing, demographics, and more.
https://www.php.cn/link/5d7009220a974e94404889274d3a9553
Subseasonal Forecasting Microsoft (2021): This is a publicly released data set by Microsoft , designed to promote the use of machine learning to improve subseasonal forecasts (e.g., two to six weeks ahead). Sub-seasonal forecasts help government agencies better prepare for weather events and farmers’ decisions. Microsoft has included several benchmark models for this task, and in general deep learning models perform quite poorly compared to other methods. The best DL model is a simple feedforward model, and Informer performs very poorly.
https://www.php.cn/link/c3cbd51329ff1a0169174e9a78126ee1
Revisiting Time Series Outlier Detection: This article reviews many existing anomalies/ outlier detection datasets, and 35 new synthetic datasets and 4 real-world datasets are proposed for benchmarking.
https://www.php.cn/link/03793ef7d06ffd63d34ade9d091f1ced
The open source timing prediction framework FF
Flow Forecast is An open source time series prediction framework, which includes the following models:
Vanilla LSTM (LSTM), SimpleTransformer, Multi-Head Attention, Transformer with a linear decoder, DARNN, Transformer XL, Informer, DeepAR, DSANet, SimpleLinearModel Wait
This is a good source of model code for learning to use deep learning for time prediction. If you are interested, you can take a look.
https://www.php.cn/link/fea33a31df7d05a276193d32621ecbe4
Summary
In the past two years, we has seen the rise and possible decline of Transformers in time series forecasting and the rise of time series embedding methods, with additional breakthroughs in anomaly detection and classification.
But for deep learning time series: interpretability, visualization and benchmarking methods are still lacking, because where the model is executed and where performance failures occur is very important. Additionally, more forms of regularization, preprocessing, and transfer learning to improve performance may appear in the future.
Maybe Transformer is good for time series prediction (maybe not). Just like VIT, Transformer may still be considered useless without the emergence of Patch. We will also continue to pay attention to the development or replacement of Transformer in time series.
The above is the detailed content of A review of research progress of deep learning in time series prediction and classification in 2022. For more information, please follow other related articles on the PHP Chinese website!

 The AI Skills Gap Is Slowing Down Supply ChainsApr 26, 2025 am 11:13 AM
The AI Skills Gap Is Slowing Down Supply ChainsApr 26, 2025 am 11:13 AMThe term "AI-ready workforce" is frequently used, but what does it truly mean in the supply chain industry? According to Abe Eshkenazi, CEO of the Association for Supply Chain Management (ASCM), it signifies professionals capable of critic
 How One Company Is Quietly Working To Transform AI ForeverApr 26, 2025 am 11:12 AM
How One Company Is Quietly Working To Transform AI ForeverApr 26, 2025 am 11:12 AMThe decentralized AI revolution is quietly gaining momentum. This Friday in Austin, Texas, the Bittensor Endgame Summit marks a pivotal moment, transitioning decentralized AI (DeAI) from theory to practical application. Unlike the glitzy commercial
 Nvidia Releases NeMo Microservices To Streamline AI Agent DevelopmentApr 26, 2025 am 11:11 AM
Nvidia Releases NeMo Microservices To Streamline AI Agent DevelopmentApr 26, 2025 am 11:11 AMEnterprise AI faces data integration challenges The application of enterprise AI faces a major challenge: building systems that can maintain accuracy and practicality by continuously learning business data. NeMo microservices solve this problem by creating what Nvidia describes as "data flywheel", allowing AI systems to remain relevant through continuous exposure to enterprise information and user interaction. This newly launched toolkit contains five key microservices: NeMo Customizer handles fine-tuning of large language models with higher training throughput. NeMo Evaluator provides simplified evaluation of AI models for custom benchmarks. NeMo Guardrails implements security controls to maintain compliance and appropriateness
 AI Paints A New Picture For The Future Of Art And DesignApr 26, 2025 am 11:10 AM
AI Paints A New Picture For The Future Of Art And DesignApr 26, 2025 am 11:10 AMAI: The Future of Art and Design Artificial intelligence (AI) is changing the field of art and design in unprecedented ways, and its impact is no longer limited to amateurs, but more profoundly affecting professionals. Artwork and design schemes generated by AI are rapidly replacing traditional material images and designers in many transactional design activities such as advertising, social media image generation and web design. However, professional artists and designers also find the practical value of AI. They use AI as an auxiliary tool to explore new aesthetic possibilities, blend different styles, and create novel visual effects. AI helps artists and designers automate repetitive tasks, propose different design elements and provide creative input. AI supports style transfer, which is to apply a style of image
 How Zoom Is Revolutionizing Work With Agentic AI: From Meetings To MilestonesApr 26, 2025 am 11:09 AM
How Zoom Is Revolutionizing Work With Agentic AI: From Meetings To MilestonesApr 26, 2025 am 11:09 AMZoom, initially known for its video conferencing platform, is leading a workplace revolution with its innovative use of agentic AI. A recent conversation with Zoom's CTO, XD Huang, revealed the company's ambitious vision. Defining Agentic AI Huang d
 The Existential Threat To UniversitiesApr 26, 2025 am 11:08 AM
The Existential Threat To UniversitiesApr 26, 2025 am 11:08 AMWill AI revolutionize education? This question is prompting serious reflection among educators and stakeholders. The integration of AI into education presents both opportunities and challenges. As Matthew Lynch of The Tech Edvocate notes, universit
 The Prototype: American Scientists Are Looking For Jobs AbroadApr 26, 2025 am 11:07 AM
The Prototype: American Scientists Are Looking For Jobs AbroadApr 26, 2025 am 11:07 AMThe development of scientific research and technology in the United States may face challenges, perhaps due to budget cuts. According to Nature, the number of American scientists applying for overseas jobs increased by 32% from January to March 2025 compared with the same period in 2024. A previous poll showed that 75% of the researchers surveyed were considering searching for jobs in Europe and Canada. Hundreds of NIH and NSF grants have been terminated in the past few months, with NIH’s new grants down by about $2.3 billion this year, a drop of nearly one-third. The leaked budget proposal shows that the Trump administration is considering sharply cutting budgets for scientific institutions, with a possible reduction of up to 50%. The turmoil in the field of basic research has also affected one of the major advantages of the United States: attracting overseas talents. 35
 All About Open AI's Latest GPT 4.1 Family - Analytics VidhyaApr 26, 2025 am 10:19 AM
All About Open AI's Latest GPT 4.1 Family - Analytics VidhyaApr 26, 2025 am 10:19 AMOpenAI unveils the powerful GPT-4.1 series: a family of three advanced language models designed for real-world applications. This significant leap forward offers faster response times, enhanced comprehension, and drastically reduced costs compared t


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

SublimeText3 Chinese version
Chinese version, very easy to use

Notepad++7.3.1
Easy-to-use and free code editor

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

