
Home >Backend Development >Python Tutorial >Super simple! Remove watermarks from images and PDFs using Python
Super simple! Remove watermarks from images and PDFs using Python

- WBOYforward
- 2023-04-12 23:43:012401browse

Some pdf learning materials downloaded online will have watermarks, which greatly affects reading. For example, the picture below was cut out from a pdf file. Today we will use Python to solve this problem.

Installation module
PIL: Python Imaging Library is a very powerful image processing standard library on python, but it can only support python 2.7, so I have a volunteer The author created a pillow that supports python 3 based on PIL and added some new features.
pip install pillow
pymupdf You can use python to access files with the extension *.pdf, .xps, .oxps, .epub, .cbz or *.fb2. Many popular image formats are also supported, including multi-page TIFF images.
pip install PyMuPDF
Import the required modules
from PIL import Image from itertools import product import fitz import os
Get the RGB of the image
pdf The principle of watermark removal is similar to that of image watermark removal. The editor will first remove the above Start with the watermark of the picture.
Everyone who has studied computers knows that RGB is used to represent red, green and blue in computers, (255, 0, 0) is used to represent red, (0, 255, 0) is used to represent green, (0, 0 , 255) represents blue, (255, 255, 255) represents white, (0, 0, 0) represents black. The principle of watermark removal is to change the color of the watermark to white (255, 255, 255).
First get the width and height of the image, and use the itertools module to get the Cartesian product of width and height as pixels. The color of each pixel is composed of the first three bits of RGB and the fourth bit of Alpha channel. Alpha channel is not required, only RGB data.
def remove_img():
image_file = input("请输入图片地址:")
img = Image.open(image_file)
width, height = img.size
for pos in product(range(width), range(height)):
rgb = img.getpixel(pos)[:3]
print(rgb)
Removing watermarks from pictures
Use WeChat screenshots to check the RGB of the watermark pixels.
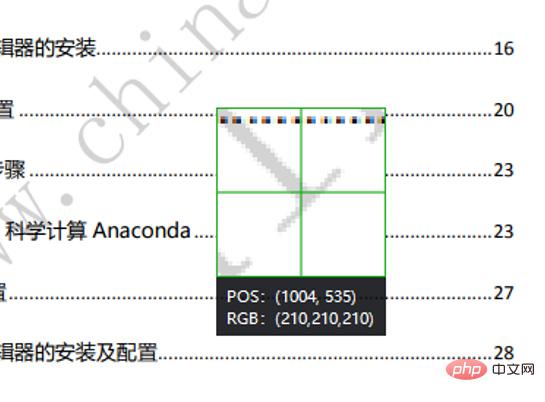
You can see that the RGB of the watermark is (210, 210, 210). Here, if the sum of RGB exceeds 620, it is judged to be a watermark point. At this time, replace the pixel color with White. Finally save the picture.
rgb = img.getpixel(pos)[:3]
if(sum(rgb) >= 620):
img.putpixel(pos, (255, 255, 255))
img.save('d:/qsy.png')
Example results:

PDF watermark removal
PDF The principle of watermark removal is roughly the same as that of image watermark removal. Use PyMuPDF After opening the pdf file, convert each page of the pdf into a picture pixmap. Pixmap has its own RGB. You only need to change the RGB in the pdf watermark to (255, 255, 255) and finally save it as a picture.
def remove_pdf():
page_num = 0
pdf_file = input("请输入 pdf 地址:")
pdf = fitz.open(pdf_file);
for page in pdf:
pixmap = page.get_pixmap()
for pos in product(range(pixmap.width), range(pixmap.height)):
rgb = pixmap.pixel(pos[0], pos[1])
if(sum(rgb) >= 620):
pixmap.set_pixel(pos[0], pos[1], (255, 255, 255))
pixmap.pil_save(f"d:/pdf_images/{page_num}.png")
print(f"第{page_num}水印去除完成")
page_num = page_num + 1
Example results:
Convert pictures to pdf
Convert pictures to pdf It should be noted that the order of pictures, the numerical file name must Convert to int type first and then sort. After opening the image with the PyMuPDF module, use the convertToPDF() function to convert the image into a single-page pdf. Insert into new pdf file.
def pic2pdf():
pic_dir = input("请输入图片文件夹路径:")
pdf = fitz.open()
img_files = sorted(os.listdir(pic_dir),key=lambda x:int(str(x).split('.')[0]))
for img in img_files:
print(img)
imgdoc = fitz.open(pic_dir + '/' + img)
pdfbytes = imgdoc.convertToPDF()
imgpdf = fitz.open("pdf", pdfbytes)
pdf.insertPDF(imgpdf)
pdf.save("d:/demo.pdf")
pdf.close()
Summary
The annoying watermarks on pdf and pictures can finally disappear in front of the powerful python. Have you guys learned enough?
The above is the detailed content of Super simple! Remove watermarks from images and PDFs using Python. For more information, please follow other related articles on the PHP Chinese website!