



Handling Missing Values

In data preprocessing, a critical step is to handle missing data because machine learning models will not accept NaN values as their input. There are many ways to fill in these NaN values, but we first need to understand the importance of missing values.
A very simple way is to remove all missing values from the machine learning dataset, but before doing that, check the overall percentage of NaN values that appear in the machine learning dataset. If it is less than 1%, we can remove all missing values, otherwise we need to impute the data by choosing other methods like central tendency measure, KNN Imputer, etc.
When we use numbers in features, we use mean or median. The mean is the average value we can calculate by summing all the values in a row and then dividing by their amount. The median also represents an average. The median arranges the data in order of size to form a sequence, which is the data in the middle of the sequence. When individual data in a set of data vary greatly, the median is often used to describe the central tendency of the set of data.
If there is a skewed distribution in the machine learning data set, it is often better to use the median than the mean.
Outliers/Outliers
Outliers are data points that are significantly different from other observations. Sometimes, these outliers can also be sensitive. Before dealing with outliers, it is recommended to examine the machine learning dataset.
For example:
- Outliers are significant in depth value predictions based on observed rainfall.
- Outliers in house price predictions have no meaning.
Data Leakage
What is the data leakage problem in machine learning models?
Data leaks occur when the data we use to train machine learning models contains information that the machine learning model is trying to predict. This can lead to unreliable prediction results after the model is deployed.
This problem may be caused by the data standardization or normalization method. Because most of us continue to use these methods before splitting the data into training and test sets.
Choose the right machine learning model
In real time, I feel that turning to some complex models unnecessarily may create some interpretability issues for business-oriented people. For example, linear regression will be easier to interpret than a neural network algorithm.
Select the corresponding machine learning model mainly based on the size and complexity of the data set. If we deal with complex problems, we can use some efficient machine learning models, such as SVN, KNN, random forest, etc.
Most of the time, the data exploration phase will help us choose the corresponding machine learning model. If the data is linearly separable in the visualization, then we can use linear regression. Support vector machines and KNN will be useful if we don't know anything about the data.
There is also a problem of model interpretability. For example, linear regression is easier to explain than neural network algorithms.
Validation Metrics
Metrics are quantitative measures of model predictors and real data. If the question is in regression, the key metrics are accuracy (R2 score), MAE (mean absolute error), and RMSE (root mean square error). If it is a classification problem, the key indicators are precision, recall, F1score and confusion matrix.
The above is the detailed content of Five common questions for newbies in machine learning. For more information, please follow other related articles on the PHP Chinese website!

 What are the TCL Commands in SQL? - Analytics VidhyaApr 22, 2025 am 11:07 AM
What are the TCL Commands in SQL? - Analytics VidhyaApr 22, 2025 am 11:07 AMIntroduction Transaction Control Language (TCL) commands are essential in SQL for managing changes made by Data Manipulation Language (DML) statements. These commands allow database administrators and users to control transaction processes, thereby
 How to Make Custom ChatGPT? - Analytics VidhyaApr 22, 2025 am 11:06 AM
How to Make Custom ChatGPT? - Analytics VidhyaApr 22, 2025 am 11:06 AMHarness the power of ChatGPT to create personalized AI assistants! This tutorial shows you how to build your own custom GPTs in five simple steps, even without coding skills. Key Features of Custom GPTs: Create personalized AI models for specific t
 Difference Between Method Overloading and OverridingApr 22, 2025 am 10:55 AM
Difference Between Method Overloading and OverridingApr 22, 2025 am 10:55 AMIntroduction Method overloading and overriding are core object-oriented programming (OOP) concepts crucial for writing flexible and efficient code, particularly in data-intensive fields like data science and AI. While similar in name, their mechanis
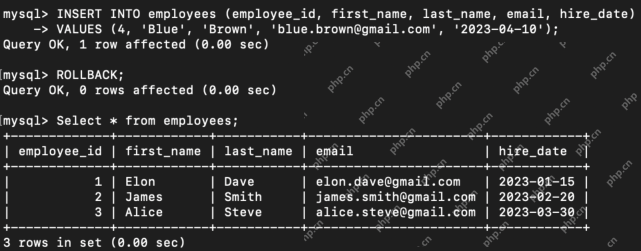
 Difference Between SQL Commit and SQL RollbackApr 22, 2025 am 10:49 AM
Difference Between SQL Commit and SQL RollbackApr 22, 2025 am 10:49 AMIntroduction Efficient database management hinges on skillful transaction handling. Structured Query Language (SQL) provides powerful tools for this, offering commands to maintain data integrity and consistency. COMMIT and ROLLBACK are central to t
 PySimpleGUI: Simplifying GUI Development in Python - Analytics VidhyaApr 22, 2025 am 10:46 AM
PySimpleGUI: Simplifying GUI Development in Python - Analytics VidhyaApr 22, 2025 am 10:46 AMPython GUI Development Simplified with PySimpleGUI Developing user-friendly graphical interfaces (GUIs) in Python can be challenging. However, PySimpleGUI offers a streamlined and accessible solution. This article explores PySimpleGUI's core functio
 8 Mind-blowing Use Cases of Claude 3.5 Sonnet - Analytics VidhyaApr 22, 2025 am 10:40 AM
8 Mind-blowing Use Cases of Claude 3.5 Sonnet - Analytics VidhyaApr 22, 2025 am 10:40 AMIntroduction Large language models (LLMs) rapidly transform how we interact with information and complete tasks. Among these, Claude 3.5 Sonnet, developed by Anthropic AI, stands out for its exceptional capabilities. Experts o
 How LLM Agents are Leading the Charge with Iterative Workflows?Apr 22, 2025 am 10:36 AM
How LLM Agents are Leading the Charge with Iterative Workflows?Apr 22, 2025 am 10:36 AMIntroduction Large Language Models (LLMs) have made significant strides in natural language processing and generation. However, the typical zero-shot approach, producing output in a single pass without refinement, has limitations. A key challenge i
 Functional Programming vs Object-Oriented ProgrammingApr 22, 2025 am 10:24 AM
Functional Programming vs Object-Oriented ProgrammingApr 22, 2025 am 10:24 AMFunctional vs. Object-Oriented Programming: A Detailed Comparison Object-oriented programming (OOP) and functional programming (FP) are the most prevalent programming paradigms, offering diverse approaches to software development. Understanding thei


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

Dreamweaver CS6
Visual web development tools

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

