

 Technology peripheralsAIResearch shows reinforcement learning models are vulnerable to membership inference attacks
Technology peripheralsAIResearch shows reinforcement learning models are vulnerable to membership inference attacksResearch shows reinforcement learning models are vulnerable to membership inference attacks

Translator | Li Rui
Reviewer | Sun Shujuan
As machine learning becomes part of many applications that people use every day, people are increasingly There is increasing focus on how to identify and address security and privacy threats to machine learning models.
However, different machine learning paradigms face different security threats, and some areas of machine learning security remain under-researched. In particular, the security of reinforcement learning algorithms has not received much attention in recent years.
Researchers at McGill University, the Machine Learning Laboratory (MILA) and the University of Waterloo in Canada have conducted a new study that focuses on the privacy threats of deep reinforcement learning algorithms. Researchers propose a framework for testing the vulnerability of reinforcement learning models to membership inference attacks.
Research results show that attackers can effectively attack deep reinforcement learning (RL) systems and may obtain sensitive information used to train models. Their findings are significant because reinforcement learning techniques are now making their way into industrial and consumer applications.
Member inference attack
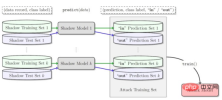
Member inference attack observes the behavior of a target machine learning model and predicts the examples used to train it .
Every machine learning model is trained on a set of examples. In some cases, training examples include sensitive information, such as health or financial data or other personally identifiable information.
Member inference attacks are a series of techniques that attempt to force a machine learning model to leak its training set data. While adversarial examples (the more well-known type of attack against machine learning) focus on changing the behavior of machine learning models and are considered a security threat, membership inference attacks focus on extracting information from the model and are more of a privacy threat .
Membership inference attacks have been well studied in supervised machine learning algorithms, where models are trained on labeled examples.
Unlike supervised learning, deep reinforcement learning systems do not use labeled examples. A reinforcement learning (RL) agent receives rewards or penalties from its interactions with the environment. It gradually learns and develops its behavior through these interactions and reinforcement signals.
The paper's authors said in written comments, "Rewards in reinforcement learning do not necessarily represent labels; therefore, they cannot serve as predictions often used in the design of membership inference attacks in other learning paradigms tags."
The researchers wrote in their paper that "there are currently no studies on the potential leakage of members of data used directly to train deep reinforcement learning agents."
Part of the reason for this lack of research is that reinforcement learning has limited real-world applications.
The authors of the research paper said, “Despite significant progress in the field of deep reinforcement learning, such as Alpha Go, Alpha Fold, and GT Sophy, deep reinforcement learning models are still not available on an industrial scale. has been widely adopted. On the other hand, data privacy is a very widely used research field. The lack of deep reinforcement learning models in actual industrial applications has greatly delayed the research of this basic and important research field, resulting in the lack of research on reinforcement learning systems. Attacks are under-researched.”
With the growing demand for industrial-scale application of reinforcement learning algorithms in real-world scenarios, there is a need to address the privacy aspects of reinforcement learning algorithms from an adversarial and algorithmic perspective. The focus and rigorous requirements of the framework are becoming increasingly apparent and relevant.
Challenges of Membership Inference in Deep Reinforcement Learning

#The authors of the research paper say, “We are developing the first generation of privacy-preserving Our efforts on deep reinforcement learning algorithms have made us realize that from a privacy perspective, there are fundamental structural differences between traditional machine learning algorithms and reinforcement learning algorithms.”
More critically, the researchers found, the fundamental differences between deep reinforcement learning and other learning paradigms pose serious challenges in deploying deep reinforcement learning models for practical applications, given potential privacy consequences.
They said, “Based on this realization, the big question for us is: How vulnerable are deep reinforcement learning algorithms to privacy attacks such as membership inference attacks? Now Inference Attacks Attack models are specifically designed for other learning paradigms, so the vulnerability of deep reinforcement learning algorithms to such attacks is largely unknown. Given the severe privacy implications of deployment around the world, this A curiosity about the unknown and the need to increase awareness in research and industry are the main motivations for this research.”
During the training process, the reinforcement learning model went through multiple Phases, each consisting of a trajectory or sequence of actions and states. Therefore, a successful membership inference attack algorithm for reinforcement learning must learn the data points and trajectories used to train the model. On the one hand, this makes it more difficult to design membership inference algorithms for reinforcement learning systems; on the other hand, it also makes it difficult to evaluate the robustness of reinforcement learning models to such attacks.
The authors say, “Membership inference attacks (MIA) are difficult in reinforcement learning compared to other types of machine learning because the data points used during training have sequential and Time-dependent nature. The many-to-many relationship between training and prediction data points is fundamentally different from other learning paradigms."
The fundamental relationship between reinforcement learning and other machine learning paradigms The difference makes it crucial to think in new ways when designing and evaluating membership inference attacks for deep reinforcement learning.
Designing membership inference attacks against reinforcement learning systems
In their study, the researchers focused on non-policy reinforcement learning algorithms, where the data collection and model training process are separate. Reinforcement learning uses a "replay buffer" to decorrelate input trajectories and enable the reinforcement learning agent to explore many different trajectories from the same set of data.
Non-policy reinforcement learning is especially important for many real-world applications where training data pre-exists and is provided to the machine learning team that is training the reinforcement learning model. Non-policy reinforcement learning is also critical for creating membership inference attack models.
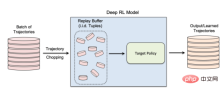
Non-policy reinforcement learning uses a "replay buffer" to reuse previously collected data during model training
The authors say, "The exploration and exploitation phases are separated in a true non-policy reinforcement learning model. Therefore, the target policy does not affect the training trajectory. This setup is particularly suitable when designing a member inference attack framework in a black-box environment , because the attacker neither knows the internal structure of the target model nor the exploration strategy used to collect training trajectories."
In a black-box membership inference attack, the attacker can only Observe the behavior of the trained reinforcement learning model. In this particular case, the attacker assumes that the target model has been trained on trajectories generated from a set of private data, which is how non-policy reinforcement learning works.
In the study, the researchers chose "batch-constrained deep Q-learning" (BCQ), an advanced non-policy reinforcement learning algorithm, showing excellent performance in control tasks. However, they show that their membership inference attack technique can be extended to other non-policy reinforcement learning models.
One way attackers can conduct membership inference attacks is to develop "shadow models". This is a classifier machine learning model that has been trained on a mixture of data from the same distribution as the target model's training data and elsewhere. After training, the shadow model can distinguish between data points that belong to the target machine learning model's training set and new data that the model has not seen before. Creating shadow models for reinforcement learning agents is tricky due to the sequential nature of target model training. The researchers achieved this through several steps.
First, they feed the reinforcement learning model trainer a new set of non-private data trajectories and observe the trajectories generated by the target model. The attack trainer then uses the training and output trajectories to train a machine learning classifier to detect the input trajectories used in training the target reinforcement learning model. Finally, the classifier is provided with new trajectories to classify as training members or new data examples.

Shadow model for training member inference attacks on reinforcement learning models
Testing member inference attacks against reinforcement learning systems
The researchers tested their membership inference attack in different modes, including different trajectory lengths, single versus multiple trajectories, and correlated versus decorrelated trajectories.
The researchers noted in their paper: "The results show that our proposed attack framework is highly effective in inferring reinforcement learning model training data points... The results obtained show that using There are high privacy risks when using deep reinforcement learning.”
Their results show that attacks with multiple trajectories are more effective than attacks with a single trajectory, and as the trajectories get longer And correlated with each other, the accuracy of the attack will also increase.
The authors say, "The natural setting is of course an individual model, and the attacker is interested in identifying the presence of a specific individual in the training set used to train the target reinforcement learning policy (in reinforcement learning the entire setting trajectories). However, the better performance of Membership Inference Attack (MIA) in collective mode shows that in addition to the temporal correlation captured by the features of the training policy, the attacker can also exploit the cross-correlation between the training trajectories of the target policy sex."
Researchers said this also means that attackers need more complex learning architectures and more sophisticated hyperparameter tuning to exploit the cross-correlation between training trajectories and trajectories time correlation within.
"Understanding these different attack modes can provide us with a deeper understanding of the impact on data security and privacy, as it gives us a better understanding of what might happen," the researchers said. Different angles of attack and the degree of impact on privacy leakage."
Member inference attacks against reinforcement learning systems in the real world
The researchers tested their attack on a reinforcement learning model trained on three tasks based on the Open AIGym and MuJoCo physics engines.
The researchers said, "Our current experiments cover three high-dimensional motion tasks, Hopper, Half-Cheetah and Ant. These tasks are all robot simulation tasks and mainly promote the experiment. Extended to real-world robot learning tasks.” Another exciting direction for application members to infer attacks is conversational systems such as Amazon Alexa, Apple’s Siri and Google Assistant. In these applications, data points are presented by the complete interaction trace between the chatbot and the end user. In this setting, the chatbot is a trained reinforcement learning policy, and the user's interactions with the robot form the input trajectory.
The authors say, “In this case, the collective pattern is the natural environment. In other words, if and only if the attacker correctly infers a batch of trajectories that represent the users in the training set , the attacker can infer the user's presence in the training set."
The team is exploring other practical applications where such attacks could affect reinforcement learning systems. They may also study how these attacks can be applied to reinforcement learning in other contexts.
The authors say, "An interesting extension of this research area is to study member inference attacks against deep reinforcement learning models in a white-box environment, where the internal structure of the target policy is also the attacker's Known."
The researchers hope their study will shed light on security and privacy issues in real-world reinforcement learning applications and raise awareness in the machine learning community to work in the field. More research.
Original title:
Reinforcement learning models are prone to membership inference attacks, author: Ben Dickson
The above is the detailed content of Research shows reinforcement learning models are vulnerable to membership inference attacks. For more information, please follow other related articles on the PHP Chinese website!

 You Must Build Workplace AI Behind A Veil Of IgnoranceApr 29, 2025 am 11:15 AM
You Must Build Workplace AI Behind A Veil Of IgnoranceApr 29, 2025 am 11:15 AMIn John Rawls' seminal 1971 book The Theory of Justice, he proposed a thought experiment that we should take as the core of today's AI design and use decision-making: the veil of ignorance. This philosophy provides a simple tool for understanding equity and also provides a blueprint for leaders to use this understanding to design and implement AI equitably. Imagine that you are making rules for a new society. But there is a premise: you don’t know in advance what role you will play in this society. You may end up being rich or poor, healthy or disabled, belonging to a majority or marginal minority. Operating under this "veil of ignorance" prevents rule makers from making decisions that benefit themselves. On the contrary, people will be more motivated to formulate public
 Decisions, Decisions… Next Steps For Practical Applied AIApr 29, 2025 am 11:14 AM
Decisions, Decisions… Next Steps For Practical Applied AIApr 29, 2025 am 11:14 AMNumerous companies specialize in robotic process automation (RPA), offering bots to automate repetitive tasks—UiPath, Automation Anywhere, Blue Prism, and others. Meanwhile, process mining, orchestration, and intelligent document processing speciali
 The Agents Are Coming – More On What We Will Do Next To AI PartnersApr 29, 2025 am 11:13 AM
The Agents Are Coming – More On What We Will Do Next To AI PartnersApr 29, 2025 am 11:13 AMThe future of AI is moving beyond simple word prediction and conversational simulation; AI agents are emerging, capable of independent action and task completion. This shift is already evident in tools like Anthropic's Claude. AI Agents: Research a
 Why Empathy Is More Important Than Control For Leaders In An AI-Driven FutureApr 29, 2025 am 11:12 AM
Why Empathy Is More Important Than Control For Leaders In An AI-Driven FutureApr 29, 2025 am 11:12 AMRapid technological advancements necessitate a forward-looking perspective on the future of work. What happens when AI transcends mere productivity enhancement and begins shaping our societal structures? Topher McDougal's upcoming book, Gaia Wakes:
 AI For Product Classification: Can Machines Master Tax Law?Apr 29, 2025 am 11:11 AM
AI For Product Classification: Can Machines Master Tax Law?Apr 29, 2025 am 11:11 AMProduct classification, often involving complex codes like "HS 8471.30" from systems such as the Harmonized System (HS), is crucial for international trade and domestic sales. These codes ensure correct tax application, impacting every inv
 Could Data Center Demand Spark A Climate Tech Rebound?Apr 29, 2025 am 11:10 AM
Could Data Center Demand Spark A Climate Tech Rebound?Apr 29, 2025 am 11:10 AMThe future of energy consumption in data centers and climate technology investment This article explores the surge in energy consumption in AI-driven data centers and its impact on climate change, and analyzes innovative solutions and policy recommendations to address this challenge. Challenges of energy demand: Large and ultra-large-scale data centers consume huge power, comparable to the sum of hundreds of thousands of ordinary North American families, and emerging AI ultra-large-scale centers consume dozens of times more power than this. In the first eight months of 2024, Microsoft, Meta, Google and Amazon have invested approximately US$125 billion in the construction and operation of AI data centers (JP Morgan, 2024) (Table 1). Growing energy demand is both a challenge and an opportunity. According to Canary Media, the looming electricity
 AI And Hollywood's Next Golden AgeApr 29, 2025 am 11:09 AM
AI And Hollywood's Next Golden AgeApr 29, 2025 am 11:09 AMGenerative AI is revolutionizing film and television production. Luma's Ray 2 model, as well as Runway's Gen-4, OpenAI's Sora, Google's Veo and other new models, are improving the quality of generated videos at an unprecedented speed. These models can easily create complex special effects and realistic scenes, even short video clips and camera-perceived motion effects have been achieved. While the manipulation and consistency of these tools still need to be improved, the speed of progress is amazing. Generative video is becoming an independent medium. Some models are good at animation production, while others are good at live-action images. It is worth noting that Adobe's Firefly and Moonvalley's Ma
 Is ChatGPT Slowly Becoming AI's Biggest Yes-Man?Apr 29, 2025 am 11:08 AM
Is ChatGPT Slowly Becoming AI's Biggest Yes-Man?Apr 29, 2025 am 11:08 AMChatGPT user experience declines: is it a model degradation or user expectations? Recently, a large number of ChatGPT paid users have complained about their performance degradation, which has attracted widespread attention. Users reported slower responses to models, shorter answers, lack of help, and even more hallucinations. Some users expressed dissatisfaction on social media, pointing out that ChatGPT has become “too flattering” and tends to verify user views rather than provide critical feedback. This not only affects the user experience, but also brings actual losses to corporate customers, such as reduced productivity and waste of computing resources. Evidence of performance degradation Many users have reported significant degradation in ChatGPT performance, especially in older models such as GPT-4 (which will soon be discontinued from service at the end of this month). this


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Dreamweaver CS6
Visual web development tools

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

Atom editor mac version download
The most popular open source editor

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

