

 Technology peripheralsAIExploration of multi-modal technology in Taobao main search recall scenarios
Technology peripheralsAIExploration of multi-modal technology in Taobao main search recall scenariosExploration of multi-modal technology in Taobao main search recall scenarios

Search recall, as the basis of the search system, determines the upper limit of effect improvement. How to continue to bring differentiated incremental value to the existing massive recall results is the main challenge we face. The combination of multi-modal pre-training and recall opens up new horizons for us and brings significant improvement in online effects.
Preface
Multimodal pre-training is the focus of research in academia and industry. By pre-training on large-scale data, Obtaining the semantic correspondence between different modalities can improve the performance in a variety of downstream tasks such as visual question answering, visual reasoning, and image and text retrieval. Within the group, there is also some research and application of multi-modal pre-training. In the Taobao main search scenario, there is a natural cross-modal retrieval requirement between the Query entered by the user and the products to be recalled. However, in the past, more titles and statistical features were used for products. , ignoring more intuitive information such as images. But for some queries with visual elements (such as white dress, floral dress), I believe everyone will be attracted by the image first on the search results page.


▐ Technical problems and solutions
In the main There are two main problems that need to be solved when applying multi-modal technology in search and recall scenarios:- Multi-modal graphic and text pre-training models generally integrate image and text modalities. Since the main search has Query existence, on the basis of the original image and text modalities of product images and titles, additional text modalities need to be considered. At the same time, there is a semantic gap between Query and product titles. Query is relatively short and broad, while product titles are often long and filled with keywords because sellers do SEO.
- Usually the relationship between pre-training tasks and downstream tasks is that pre-training uses large-scale unlabeled data, and downstream uses a small amount of labeled data. But for main search and recall, the scale of the downstream vector recall task is huge, with data in the billions. However, limited by limited GPU resources, pre-training can only use a relatively small amount of data. In this case, whether pre-training can also bring benefits to downstream tasks.
Our solution is as follows:
- Text-Graphic Pre-training : Pass the Query and product Item through the Encoder respectively, and input them into the cross-model as twin towers State Encoder. If we look at the Query and Item towers, they interact at a later stage, similar to the two-stream model. However, looking specifically at the Item tower, the two modes of image and title interact at an early stage. This part is a single-stream model. Therefore, our model structure is different from common single-stream or dual-stream structures. The starting point of this design is to extract Query vectors and Item vectors more effectively, provide input for the downstream twin-tower vector recall model, and introduce the twin-tower inner product modeling method in the pre-training stage. In order to model the semantic connection and gap between Query and title, we share the Encoder of Query and Item twin towers, and then learn the language model separately.
- Linkage between pre-training and recall tasks : Designed for the sample construction method and loss of the downstream vector recall task The tasks and modeling methods in the pre-training stage are explained. Different from common image and text matching tasks, we use Query-Item and Query-Image matching tasks, and use the Item with the most clicks under Query as a positive sample, and use other samples in the Batch as negative samples, and use the twin towers of Query and Item. Multi-classification tasks modeled in an inner product manner. The starting point of this design is to make pre-training closer to the vector recall task, and to provide effective input for downstream tasks as much as possible under limited resources. In addition, for the vector recall task, if the pre-training input vector is fixed during the training process, it cannot be effectively adjusted for large-scale data. For this reason, we also modeled the pre-training input vector in the vector recall task. Update of training vectors.
Pre-trained model
▐ Modeling method
The multi-modal pre-training model needs to extract features from images and then fuse them with text features. There are three main ways to extract features from images: using a model trained in the CV field to extract RoI features, Grid features and Patch features of the image. From the perspective of model structure, there are two main types according to the different fusion methods of image features and text features: single-stream model or dual-stream model. In the single-stream model, image features and text features are spliced together and input into the Encoder at an early stage, while in the dual-stream model, image features and text features are input into two independent Encoder respectively, and then input into the cross-modal Encoder for processing. Fusion.
▐ Initial exploration
The way we extract image features is: divide the image For the patch sequence, use ResNet to extract the image features of each patch. In terms of model structure, we tried a single-stream structure, that is, splicing Query, title, and image together and inputting them into the Encoder. After multiple sets of experiments, we found that under this structure, it is difficult to extract pure Query vectors and Item vectors as input for the downstream twin-tower vector recall task. If you mask out unnecessary modes when extracting a certain vector, the prediction will be inconsistent with the training. This problem is similar to directly extracting the twin-tower model from an interactive model. According to our experience, this model is not as effective as the trained twin-tower model. Based on this, we propose a new model structure.
▐ Model structure
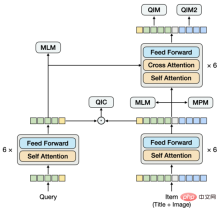
▐ Pre-training task
- Masked Language Modeling (MLM): In text Token , randomly mask out 15%, and use the remaining text and images to predict the masked text token. For Query and Title, there are respective MLM tasks. MLM minimizes cross entropy Loss:
 where represents the remaining text token
where represents the remaining text token
- Masked Patch Modeling (MPM): In the image Among the Patch Tokens, 25% are randomly masked, and the remaining images and texts are used to predict the masked image tokens. MPM minimizes KL divergence Loss: where represents the remaining image token
-
Query Item Classification (QIC ): The Item with the most clicks under a Query is used as a positive sample, and other samples in the Batch are used as negative samples. QIC reduces the dimensionality of the Query tower and Item tower [CLS] token to 256 dimensions through a linear layer, and then performs similarity calculation to obtain the predicted probability, minimizing the cross entropy Loss: where can be calculated in many ways:
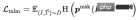
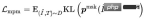
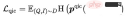


Among them represents similarity calculation, represents temperature hyperparameter, and m represent respectively Scaling factor and relaxation factor
- Query Item Matching (QIM): The Item with the most clicks under a Query is used as a positive sample, and other Items in the Batch that are most similar to the current Query are used as negative samples. QIM uses the [CLS] token of the cross-modal Encoder to calculate the prediction probability and minimize the cross entropy Loss:
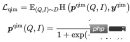
- Query Image Matching (QIM2): In the QIM sample, Mask removes the Title to strengthen the matching between Query and Image. QIM2 minimizes cross entropy Loss:
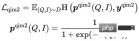
The training goal of the model is to minimize the overall Loss:
In these 5 pre-conditions In the training task, the MLM task and the MPM task are located above the Item tower, modeling the ability to use cross-modal information to recover each other after part of the Token of the Title or Image is Masked. There is an independent MLM task above the Query tower. By sharing the Encoder of the Query tower and the Item tower, the semantic relationship and gap between Query and Title are modeled. The QIC task uses the inner product of two towers to align the pre-training and downstream vector recall tasks to a certain extent, and uses AM-Softmax to close the distance between the representation of Query and the representation of the most clicked items under Query, and push away the distance between Query and the most clicked items. The distance of other Items. The QIM task is located above the cross-modal Encoder and uses cross-modal information to model the matching of Query and Item. Due to the calculation amount, the positive and negative sample ratio of the usual NSP task is 1:1. In order to further expand the distance between positive and negative samples, a difficult negative sample is constructed based on the similarity calculation results of the QIC task. The QIM2 task sits in the same position as the QIM task, explicitly modeling the incremental information brought by images relative to text.
Vector recall model
▐ Modeling method
In large-scale information retrieval systems, the recall model is at the bottom and needs to score in a massive candidate set. For performance reasons, the structure of User and Item twin towers is often used to calculate the inner product of vectors. A core issue of the vector recall model is: how to construct positive and negative samples and the scale of negative sample sampling. Our solution is to use the user's click on an Item on a page as a positive sample, sample tens of thousands of negative samples based on the click distribution in the full product pool, and use Sampled Softmax Loss to deduce from the sampling sample that the Item is in the full product pool. click probability in .

represents the similarity calculation, represents the temperature Hyperparameters
▐ Initial exploration
Following the common FineTune paradigm, we tried to convert the pre-trained vectors into Directly input to the Twin Towers MLP, combined with large-scale negative sampling and Sampled Softmax to train a multi-modal vector recall model. However, in contrast to the usual small-scale downstream tasks, the training sample size of the vector recall task is huge, in the order of billions. We observed that the parameter amount of MLP cannot support the training of the model, and it will soon reach its own convergence state, but the effect is not good. At the same time, pre-trained vectors are used as inputs rather than parameters in the vector recall model and cannot be updated as training progresses. As a result, pre-training on relatively small-scale data conflicts with downstream tasks on large-scale data.
There are several solutions. One method is to integrate the pre-training model into the vector recall model. However, the number of parameters of the pre-training model is too large, and coupled with the sample size of the vector recall model, it cannot be used in the vector recall model. Under the constraints of limited resources, regular training should be carried out within a reasonable time. Another method is to construct a parameter matrix in the vector recall model, load the pre-trained vectors into the matrix, and update the parameters of the matrix as training progresses. After investigation, this method is relatively expensive in terms of engineering implementation. Based on this, we propose a model structure that simply and feasibly models pre-training vector updates.
▐ Model structure

Let’s start with Reduce the dimensionality of the pre-training vector through FC. The reason why the dimensionality is reduced here rather than in pre-training is because the current high-dimensional vector is still within the acceptable performance range for negative sample sampling. In this case, Dimensionality reduction in vector recall tasks is more consistent with training goals. At the same time, we introduce the ID Embedding matrix of Query and Item. The Embedding dimension is consistent with the dimension of the reduced pre-training vector, and then the ID and pre-training vector are merged together. The starting point of this design is to introduce a parameter amount sufficient to support large-scale training data, while allowing the pre-training vector to be adaptively updated as training progresses.
When only ID and pre-training vectors are used to fuse, the effect of the model not only exceeds the effect of the twin-tower MLP using only pre-training vectors, but also exceeds the Baseline model MGDSPR, which contains more features. Going further, introducing more features on this basis can continue to improve the effect.
Experimental Analysis
##▐ Evaluation Indicators
The effect of the pre-trained model is usually evaluated using the indicators of downstream tasks, and separate evaluation indicators are rarely used. However, in this way, the iteration cost of the pre-trained model will be relatively high, because each iteration of a version of the model requires training the corresponding vector recall task, and then evaluating the indicators of the vector recall task, and the entire process will be very long. Are there any effective metrics for evaluating pre-trained models alone? We first tried Rank@K in some papers. This indicator is mainly used to evaluate the image-text matching task: first use the pre-trained model to score the artificially constructed candidate set, and then calculate the Top K results sorted according to the score to hit the image and text. The proportion of matching positive samples. We directly applied Rank@K to the Query-item matching task and found that the results were not in line with expectations. A better pre-training model with Rank@K may achieve worse results in the downstream vector recall model and cannot guide pre-training. Iterations of training the model. Based on this, we unify the evaluation of the pre-training model and the evaluation of the vector recall model, and use the same evaluation indicators and processes, which can relatively effectively guide the iteration of the pre-training model.Recall@K : The evaluation data set is composed of the next day’s data of the training set. First, the click and transaction results of different users under the same Query Aggregate into  , and then calculate the proportion of Top K results predicted by the modelhit:
, and then calculate the proportion of Top K results predicted by the modelhit:

For the vector recall model, after Recall@K increases to a certain level, you also need to pay attention to the correlation between Query and Item. A model with poor relevance, even if it can improve search efficiency, will also face a deterioration in user experience and an increase in complaints and public opinion caused by an increase in Bad Cases. We use an offline model consistent with the online correlation model to evaluate the correlation between Query and Item and between Query and Item categories.
▐ Pre-training experiment
We select 1 from some categories A billion-level product pool is constructed to construct a pre-training data set.
Our Baseline model is an optimized FashionBert, adding QIM and QIM2 tasks. When extracting Query and Item vectors, we only use Mean Pooling for non-Padding Tokens. The following experiments explore the gains brought by modeling with two towers relative to a single tower, and give the role of key parts through ablation experiments.

From these experiments, we can draw the following conclusions:
- Experiment 8 vs Experiment 3: Tuned Twin Towers Model , significantly higher than the single-tower Baseline in Recall@1000.
- Experiment 3 vs Experiment 1/2: For the single-tower model, how to extract the Query and Item vectors is important. We tried using [CLS] token for both Query and Item, and got poor results. Experiment 1 uses corresponding Tokens for Query and Item respectively to do Mean Pooling, and the effect is better, but further removing the Padding Token and then doing Mean Pooling will bring greater improvement. Experiment 2 verified that explicit modeling of Query-Image matching to highlight image information will bring improvements.
- Experiment 6 vs Experiment 4/5: Experiment 4 moved the MLM/MPM tasks of the Item tower to the cross-modal Encoder, and the effect will be worse, because placing these two tasks in the Item tower can enhance the Item Representation learning; in addition, cross-modal recovery based on Title and Image in the Item tower will have a stronger correspondence. Experiment 5 verified that adding L2 Norm to Query and Item vectors during training and prediction will bring improvements.
- Experiment 6/7/8: Changing the loss of the QIC task will bring improvement. Compared with Sigmoid, Softmax is closer to the downstream vector recall task, and AM-Softmax further pushes away the positive samples and negative samples. the distance between.
▐ Vector Recall Experiment
We select 1 billion level Clicked pages construct a vector recall dataset. Each page contains 3 click items as positive samples, and 10,000 negative samples are sampled from the product pool based on the click distribution. On this basis, no significant improvement in the effect was observed by further expanding the amount of training data or negative sample sampling.
Our Baseline model is the MGDSPR model of the main search. The following experiments explore the gains brought by combining multi-modal pre-training with vector recall relative to Baseline, and give the role of key parts through ablation experiments.
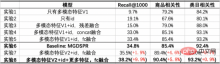
From these experiments, we can draw the following conclusions:
- Experiment 7/8 vs Experiment 6: After the fusion of multi-modal features and ID through FC, it surpassed Baseline in three indicators. While improving Recall@1000, it also improved the product relevance even more. On this basis, adding the same features as Baseline can further improve three indicators and improve Recall@1000 even more.
- Experiment 1 vs Experiment 2: Compared with only ID, only multi-modal features have lower Recall@1000, but higher correlation, and the correlation is close to the degree available online. This shows that the multi-modal recall model at this time has fewer Bad Cases from the recall results, but the efficiency of clicks and transactions is not considered enough.
- Experiment 3/4/5 vs Experiment 1/2: After fusing multi-modal features with ID, it can improve all three indicators. Among them, ID is passed through FC and then combined with the dimensionally reduced Multimodal features are added together to achieve better results. However, compared with Baseline, there is still a gap in Recall@1000.
- Experiment 7 vs Experiment 5: After superimposing the optimization of the pre-training model, the Recall@1000 and product correlation are improved, and the category correlation is basically the same.
Among the Top 1000 results of the vector recall model, we filtered out the items that the online system has been able to recall, and found that the correlation of the remaining incremental results is basically unchanged. Under a large number of Query, we see that these incremental results capture image information beyond the product Title, and play a certain role in the semantic gap between Query and Title. . query: handsome suit
##query: women’s waist-cinching shirt
Summary and Outlook
In response to the application requirements of the main search scenario, we proposed a text-image pre-training model, using the Query and Item twin-tower input cross-modal Encoder. Structure, where the Item tower is a single-flow model containing multi-modal graphics and text. Through the Query-Item and Query-Image matching tasks, as well as the Query-Item multi-classification task modeled by the inner product of Query and Item twin towers, the pre-training is closer to the downstream vector recall task. At the same time, the update of pre-trained vectors is modeled in vector recall. In the case of limited resources, pre-training using a relatively small amount of data can still improve the performance of downstream tasks that use massive data.
In other scenarios of main search, such as product understanding, relevance, and sorting, there is also a need to apply multi-modal technology. We have also participated in the exploration of these scenarios and believe that multi-modal technology will bring benefits to more and more scenarios in the future.
Team introduction
Taobao main search recall team: The team is responsible for the recall and rough sorting links in the main search link. The current main technical direction is based on full-space samples Multi-objective personalized vector recall, multi-modal recall based on large-scale pre-training, similar Query semantic rewriting based on contrastive learning, and coarse ranking models, etc.
The above is the detailed content of Exploration of multi-modal technology in Taobao main search recall scenarios. For more information, please follow other related articles on the PHP Chinese website!

 Meta's New AI Assistant: Productivity Booster Or Time Sink?May 01, 2025 am 11:18 AM
Meta's New AI Assistant: Productivity Booster Or Time Sink?May 01, 2025 am 11:18 AMMeta has joined hands with partners such as Nvidia, IBM and Dell to expand the enterprise-level deployment integration of Llama Stack. In terms of security, Meta has launched new tools such as Llama Guard 4, LlamaFirewall and CyberSecEval 4, and launched the Llama Defenders program to enhance AI security. In addition, Meta has distributed $1.5 million in Llama Impact Grants to 10 global institutions, including startups working to improve public services, health care and education. The new Meta AI application powered by Llama 4, conceived as Meta AI
 80% Of Gen Zers Would Marry An AI: StudyMay 01, 2025 am 11:17 AM
80% Of Gen Zers Would Marry An AI: StudyMay 01, 2025 am 11:17 AMJoi AI, a company pioneering human-AI interaction, has introduced the term "AI-lationships" to describe these evolving relationships. Jaime Bronstein, a relationship therapist at Joi AI, clarifies that these aren't meant to replace human c
 AI Is Making The Internet's Bot Problem Worse. This $2 Billion Startup Is On The Front LinesMay 01, 2025 am 11:16 AM
AI Is Making The Internet's Bot Problem Worse. This $2 Billion Startup Is On The Front LinesMay 01, 2025 am 11:16 AMOnline fraud and bot attacks pose a significant challenge for businesses. Retailers fight bots hoarding products, banks battle account takeovers, and social media platforms struggle with impersonators. The rise of AI exacerbates this problem, rende
 Selling To Robots: The Marketing Revolution That Will Make Or Break Your BusinessMay 01, 2025 am 11:15 AM
Selling To Robots: The Marketing Revolution That Will Make Or Break Your BusinessMay 01, 2025 am 11:15 AMAI agents are poised to revolutionize marketing, potentially surpassing the impact of previous technological shifts. These agents, representing a significant advancement in generative AI, not only process information like ChatGPT but also take actio
 How Computer Vision Technology Is Transforming NBA Playoff OfficiatingMay 01, 2025 am 11:14 AM
How Computer Vision Technology Is Transforming NBA Playoff OfficiatingMay 01, 2025 am 11:14 AMAI's Impact on Crucial NBA Game 4 Decisions Two pivotal Game 4 NBA matchups showcased the game-changing role of AI in officiating. In the first, Denver's Nikola Jokic's missed three-pointer led to a last-second alley-oop by Aaron Gordon. Sony's Haw
 How AI Is Accelerating The Future Of Regenerative MedicineMay 01, 2025 am 11:13 AM
How AI Is Accelerating The Future Of Regenerative MedicineMay 01, 2025 am 11:13 AMTraditionally, expanding regenerative medicine expertise globally demanded extensive travel, hands-on training, and years of mentorship. Now, AI is transforming this landscape, overcoming geographical limitations and accelerating progress through en
 Key Takeaways From Intel Foundry Direct Connect 2025May 01, 2025 am 11:12 AM
Key Takeaways From Intel Foundry Direct Connect 2025May 01, 2025 am 11:12 AMIntel is working to return its manufacturing process to the leading position, while trying to attract fab semiconductor customers to make chips at its fabs. To this end, Intel must build more trust in the industry, not only to prove the competitiveness of its processes, but also to demonstrate that partners can manufacture chips in a familiar and mature workflow, consistent and highly reliable manner. Everything I hear today makes me believe Intel is moving towards this goal. The keynote speech of the new CEO Tan Libo kicked off the day. Tan Libai is straightforward and concise. He outlines several challenges in Intel’s foundry services and the measures companies have taken to address these challenges and plan a successful route for Intel’s foundry services in the future. Tan Libai talked about the process of Intel's OEM service being implemented to make customers more
 AI Gone Wrong? Now There's Insurance For ThatMay 01, 2025 am 11:11 AM
AI Gone Wrong? Now There's Insurance For ThatMay 01, 2025 am 11:11 AMAddressing the growing concerns surrounding AI risks, Chaucer Group, a global specialty reinsurance firm, and Armilla AI have joined forces to introduce a novel third-party liability (TPL) insurance product. This policy safeguards businesses against


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SublimeText3 English version
Recommended: Win version, supports code prompts!

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

Dreamweaver CS6
Visual web development tools

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

