
Home >Web Front-end >JS Tutorial >An article to talk about cluster in Node.js
An article to talk about cluster in Node.js

- 青灯夜游forward
- 2023-01-22 05:30:013026browse

In daily work, the use of Node.js is relatively superficial. Let’s learn something a little more advanced while we are still young. Let’s start with cluster.
Nicholas Zhang San said, "It is a better way to study with questions," so let's give it a try.
When I first used cluster, I was always curious about how it could allow multiple child processes to listen to the same port without conflict, such as the following code:
const cluster = require('cluster')
const net = require('net')
const cpus = require('os').cpus()
if (cluster.isPrimary) {
for (let i = 0; i < cpus.length; i++) {
cluster.fork()
}
} else {
net
.createServer(function (socket) {
socket.on('data', function (data) {
socket.write(`Reply from ${process.pid}: ` + data.toString())
})
socket.on('end', function () {
console.log('Close')
})
socket.write('Hello!\n')
})
.listen(9999)
}This code passes through the parent processfork Multiple child processes have emerged, and these child processes all listen to the port 9999 and can provide services normally. How to do this? Let's study it. [Related tutorial recommendations: nodejs video tutorial, Programming teaching]
Prepare debugging environment
Learn Node.js official The best way to provide a library is of course to debug it, so let's prepare the environment first. Note: The operating system of this article is macOS Big Sur 11.6.6. Please prepare the corresponding environment for other systems.
Compile Node.js
Download Node.js source code
git clone https://github.com/nodejs/node.git
Then add breakpoints in the following two places to facilitate later debugging:
// lib/internal/cluster/primary.js
function queryServer(worker, message) {
debugger;
// Stop processing if worker already disconnecting
if (worker.exitedAfterDisconnect) return;
...
}// lib/internal/cluster/child.js
send(message, (reply, handle) => {
debugger
if (typeof obj._setServerData === 'function') obj._setServerData(reply.data)
if (handle) {
// Shared listen socket
shared(reply, {handle, indexesKey, index}, cb)
} else {
// Round-robin.
rr(reply, {indexesKey, index}, cb)
}
})Enter the directory and execute
./configure --debug make -j4
. Generate out/Debug/node
Prepare the IDE environment
Use vscode to debug and configurelaunch. json is enough (other IDEs are similar, please solve it by yourself):
{
"version": "0.2.0",
"configurations": [
{
"name": "Debug C++",
"type": "cppdbg",
"program": "/Users/youxingzhi/ayou/node/out/Debug/node",
"request": "launch",
"args": ["/Users/youxingzhi/ayou/node/index.js"],
"stopAtEntry": false,
"cwd": "${workspaceFolder}",
"environment": [],
"externalConsole": false,
"MIMode": "lldb"
},
{
"name": "Debug Node",
"type": "node",
"runtimeExecutable": "/Users/youxingzhi/ayou/node/out/Debug/node",
"request": "launch",
"args": ["--expose-internals", "--nolazy"],
"skipFiles": [],
"program": "${workspaceFolder}/index.js"
}
]
}The first one is used to debug C code (need to install C/C plug-in), and the second one is used to debug JS code. Next, you can start debugging. For the time being, we can use the configuration for debugging JS code.
Cluster source code debugging
Prepare the debugging code (for debugging purposes only, it is enough to start a child process here):
debugger
const cluster = require('cluster')
const net = require('net')
if (cluster.isPrimary) {
debugger
cluster.fork()
} else {
const server = net.createServer(function (socket) {
socket.on('data', function (data) {
socket.write(`Reply from ${process.pid}: ` + data.toString())
})
socket.on('end', function () {
console.log('Close')
})
socket.write('Hello!\n')
})
debugger
server.listen(9999)
}Obviously, Our program can be analyzed in two parts: parent process and child process.
The parent process is entered first:
When executing require('cluster'), lib/cluster.js will be entered This file:
const childOrPrimary = 'NODE_UNIQUE_ID' in process.env ? 'child' : 'primary'
module.exports = require(`internal/cluster/${childOrPrimary}`) will introduce different modules based on whether there is NODE_UNIQUE_ID on the current process.env. At this time, there is no such module, so it will be introduced. internal/cluster/primary.js This module:
...
const cluster = new EventEmitter();
...
module.exports = cluster
const handles = new SafeMap()
cluster.isWorker = false
cluster.isMaster = true // Deprecated alias. Must be same as isPrimary.
cluster.isPrimary = true
cluster.Worker = Worker
cluster.workers = {}
cluster.settings = {}
cluster.SCHED_NONE = SCHED_NONE // Leave it to the operating system.
cluster.SCHED_RR = SCHED_RR // Primary distributes connections.
...
cluster.schedulingPolicy = schedulingPolicy
cluster.setupPrimary = function (options) {
...
}
// Deprecated alias must be same as setupPrimary
cluster.setupMaster = cluster.setupPrimary
function setupSettingsNT(settings) {
...
}
function createWorkerProcess(id, env) {
...
}
function removeWorker(worker) {
...
}
function removeHandlesForWorker(worker) {
...
}
cluster.fork = function (env) {
...
}This module mainly mounts some properties and methods on the cluster object and exports them. Looking back, we continue to debug. When debugging, you will enter the if (cluster.isPrimary) branch. The code is very simple. It just fork creates a new child process:
// lib/internal/cluster/primary.js
cluster.fork = function (env) {
cluster.setupPrimary()
const id = ++ids
const workerProcess = createWorkerProcess(id, env)
const worker = new Worker({
id: id,
process: workerProcess,
})
...
worker.process.on('internalMessage', internal(worker, onmessage))
process.nextTick(emitForkNT, worker)
cluster.workers[worker.id] = worker
return worker
}cluster.setupPrimary(): Relatively simple, initialize some parameters and so on.
createWorkerProcess(id, env):
// lib/internal/cluster/primary.js
function createWorkerProcess(id, env) {
const workerEnv = {...process.env, ...env, NODE_UNIQUE_ID: `${id}`}
const execArgv = [...cluster.settings.execArgv]
...
return fork(cluster.settings.exec, cluster.settings.args, {
cwd: cluster.settings.cwd,
env: workerEnv,
serialization: cluster.settings.serialization,
silent: cluster.settings.silent,
windowsHide: cluster.settings.windowsHide,
execArgv: execArgv,
stdio: cluster.settings.stdio,
gid: cluster.settings.gid,
uid: cluster.settings.uid,
})
}As you can see, this method mainly starts a child process to execute us through fork index.js, and the environment variable NODE_UNIQUE_ID is set when starting the child process, so require('cluster')# in index.js ##, the internal/cluster/child.js module is introduced.
worker.process.on('internalMessage', internal(worker, onmessage)): Listen to the message passed by the child process and process it.
Then we enter the logic of the child process:
As mentioned before, what is introduced at this time isinternal/cluster/child.js module, we skip it first and continue down. When executing server.listen(9999), the method on Server is actually called:
// lib/net.js
Server.prototype.listen = function (...args) {
...
listenInCluster(
this,
null,
options.port | 0,
4,
backlog,
undefined,
options.exclusive
);
}You can see Finally, listenInCluster is called:
// lib/net.js
function listenInCluster(
server,
address,
port,
addressType,
backlog,
fd,
exclusive,
flags,
options
) {
exclusive = !!exclusive
if (cluster === undefined) cluster = require('cluster')
if (cluster.isPrimary || exclusive) {
// Will create a new handle
// _listen2 sets up the listened handle, it is still named like this
// to avoid breaking code that wraps this method
server._listen2(address, port, addressType, backlog, fd, flags)
return
}
const serverQuery = {
address: address,
port: port,
addressType: addressType,
fd: fd,
flags,
backlog,
...options,
}
// Get the primary's server handle, and listen on it
cluster._getServer(server, serverQuery, listenOnPrimaryHandle)
function listenOnPrimaryHandle(err, handle) {
err = checkBindError(err, port, handle)
if (err) {
const ex = exceptionWithHostPort(err, 'bind', address, port)
return server.emit('error', ex)
}
// Reuse primary's server handle
server._handle = handle
// _listen2 sets up the listened handle, it is still named like this
// to avoid breaking code that wraps this method
server._listen2(address, port, addressType, backlog, fd, flags)
}
} Since it is executed in the child process, cluster._getServer(server, serverQuery, listenOnPrimaryHandle) will be called in the end:
// lib/internal/cluster/child.js
// 这里的 cb 就是上面的 listenOnPrimaryHandle
cluster._getServer = function (obj, options, cb) {
...
send(message, (reply, handle) => {
debugger
if (typeof obj._setServerData === 'function') obj._setServerData(reply.data)
if (handle) {
// Shared listen socket
shared(reply, {handle, indexesKey, index}, cb)
} else {
// Round-robin.
rr(reply, {indexesKey, index}, cb)
}
})
...
}This function will eventually send the queryServer message to the parent process. After the parent process has processed it, it will call the callback function, and the callback function will call cb, which is listenOnPrimaryHandle. It seems that the logic of listen is performed in the parent process.
Next enter the parent process:
After the parent process receives the message fromqueryServer, it will eventually call queryServer this Method:
// lib/internal/cluster/primary.js
function queryServer(worker, message) {
// Stop processing if worker already disconnecting
if (worker.exitedAfterDisconnect) return
const key =
`${message.address}:${message.port}:${message.addressType}:` +
`${message.fd}:${message.index}`
let handle = handles.get(key)
if (handle === undefined) {
let address = message.address
// Find shortest path for unix sockets because of the ~100 byte limit
if (
message.port < 0 &&
typeof address === 'string' &&
process.platform !== 'win32'
) {
address = path.relative(process.cwd(), address)
if (message.address.length < address.length) address = message.address
}
// UDP is exempt from round-robin connection balancing for what should
// be obvious reasons: it's connectionless. There is nothing to send to
// the workers except raw datagrams and that's pointless.
if (
schedulingPolicy !== SCHED_RR ||
message.addressType === 'udp4' ||
message.addressType === 'udp6'
) {
handle = new SharedHandle(key, address, message)
} else {
handle = new RoundRobinHandle(key, address, message)
}
handles.set(key, handle)
}
...
}As you can see, this is mainly the processing of handle. The handle here refers to the scheduling strategy, which is divided into SharedHandle and RoundRobinHandle correspond to the two strategies of preemption and polling respectively (there are examples of comparison between the two in the supplementary section at the end of the article).
Node.js 中默认是 RoundRobinHandle 策略,可通过环境变量 NODE_CLUSTER_SCHED_POLICY 来修改,取值可以为 none(SharedHandle) 或 rr(RoundRobinHandle)。
<span style="font-size: 18px;">SharedHandle</span>
首先,我们来看一下 SharedHandle,由于我们这里是 TCP 协议,所以最后会通过 net._createServerHandle 创建一个 TCP 对象挂载在 handle 属性上(注意这里又有一个 handle,别搞混了):
// lib/internal/cluster/shared_handle.js
function SharedHandle(key, address, {port, addressType, fd, flags}) {
this.key = key
this.workers = new SafeMap()
this.handle = null
this.errno = 0
let rval
if (addressType === 'udp4' || addressType === 'udp6')
rval = dgram._createSocketHandle(address, port, addressType, fd, flags)
else rval = net._createServerHandle(address, port, addressType, fd, flags)
if (typeof rval === 'number') this.errno = rval
else this.handle = rval
}在 createServerHandle 中除了创建 TCP 对象外,还绑定了端口和地址:
// lib/net.js
function createServerHandle(address, port, addressType, fd, flags) {
...
} else {
handle = new TCP(TCPConstants.SERVER);
isTCP = true;
}
if (address || port || isTCP) {
...
err = handle.bind6(address, port, flags);
} else {
err = handle.bind(address, port);
}
}
...
return handle;
}然后,queryServer 中继续执行,会调用 add 方法,最终会将 handle 也就是 TCP 对象传递给子进程:
// lib/internal/cluster/primary.js
function queryServer(worker, message) {
...
if (!handle.data) handle.data = message.data
// Set custom server data
handle.add(worker, (errno, reply, handle) => {
const {data} = handles.get(key)
if (errno) handles.delete(key) // Gives other workers a chance to retry.
send(
worker,
{
errno,
key,
ack: message.seq,
data,
...reply,
},
handle // TCP 对象
)
})
...
}之后进入子进程:
子进程收到父进程对于 queryServer 的回复后,会调用 shared:
// lib/internal/cluster/child.js
// `obj` is a net#Server or a dgram#Socket object.
cluster._getServer = function (obj, options, cb) {
...
send(message, (reply, handle) => {
if (typeof obj._setServerData === 'function') obj._setServerData(reply.data)
if (handle) {
// Shared listen socket
shared(reply, {handle, indexesKey, index}, cb)
} else {
// Round-robin.
rr(reply, {indexesKey, index}, cb) // cb 是 listenOnPrimaryHandle
}
})
...
}shared 中最后会调用 cb 也就是 listenOnPrimaryHandle:
// lib/net.js
function listenOnPrimaryHandle(err, handle) {
err = checkBindError(err, port, handle)
if (err) {
const ex = exceptionWithHostPort(err, 'bind', address, port)
return server.emit('error', ex)
}
// Reuse primary's server handle 这里的 server 是 index.js 中 net.createServer 返回的那个对象
server._handle = handle
// _listen2 sets up the listened handle, it is still named like this
// to avoid breaking code that wraps this method
server._listen2(address, port, addressType, backlog, fd, flags)
}这里会把 handle 赋值给 server._handle,这里的 server 是 index.js 中 net.createServer 返回的那个对象,并调用 server._listen2,也就是 setupListenHandle:
// lib/net.js
function setupListenHandle(address, port, addressType, backlog, fd, flags) {
debug('setupListenHandle', address, port, addressType, backlog, fd)
// If there is not yet a handle, we need to create one and bind.
// In the case of a server sent via IPC, we don't need to do this.
if (this._handle) {
debug('setupListenHandle: have a handle already')
} else {
...
}
this[async_id_symbol] = getNewAsyncId(this._handle)
this._handle.onconnection = onconnection
this._handle[owner_symbol] = this
// Use a backlog of 512 entries. We pass 511 to the listen() call because
// the kernel does: backlogsize = roundup_pow_of_two(backlogsize + 1);
// which will thus give us a backlog of 512 entries.
const err = this._handle.listen(backlog || 511)
if (err) {
const ex = uvExceptionWithHostPort(err, 'listen', address, port)
this._handle.close()
this._handle = null
defaultTriggerAsyncIdScope(
this[async_id_symbol],
process.nextTick,
emitErrorNT,
this,
ex
)
return
}
}首先会执行 this._handle.onconnection = onconnection,由于客户端请求过来时会调用 this._handle(也就是 TCP 对象)上的 onconnection 方法,也就是会执行lib/net.js 中的 onconnection 方法建立连接,之后就可以通信了。为了控制篇幅,该方法就不继续往下了。
然后调用 listen 监听,注意这里参数 backlog 跟之前不同,不是表示端口,而是表示在拒绝连接之前,操作系统可以挂起的最大连接数量,也就是连接请求的排队数量。我们平时遇到的 listen EADDRINUSE: address already in use 错误就是因为这行代码返回了非 0 的错误。
如果还有其他子进程,也会同样走一遍上述的步骤,不同之处是在主进程中 queryServer 时,由于已经有 handle 了,不需要再重新创建了:
function queryServer(worker, message) {
debugger;
// Stop processing if worker already disconnecting
if (worker.exitedAfterDisconnect) return;
const key =
`${message.address}:${message.port}:${message.addressType}:` +
`${message.fd}:${message.index}`;
let handle = handles.get(key);
...
}以上内容整理成流程图如下:
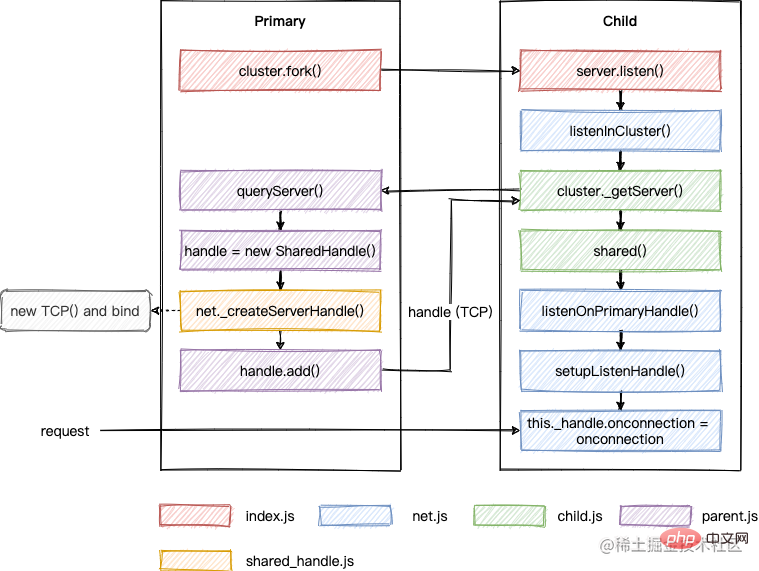
所谓的 SharedHandle,其实是在多个子进程中共享 TCP 对象的句柄,当客户端请求过来时,多个进程会去竞争该请求的处理权,会导致任务分配不均的问题,这也是为什么需要 RoundRobinHandle 的原因。接下来继续看看这种调度方式。
<span style="font-size: 18px;">RoundRobinHandle</span>
// lib/internal/cluster/round_robin_handle.js
function RoundRobinHandle(
key,
address,
{port, fd, flags, backlog, readableAll, writableAll}
) {
...
this.server = net.createServer(assert.fail)
...
else if (port >= 0) {
this.server.listen({
port,
host: address,
// Currently, net module only supports `ipv6Only` option in `flags`.
ipv6Only: Boolean(flags & constants.UV_TCP_IPV6ONLY),
backlog,
})
}
...
this.server.once('listening', () => {
this.handle = this.server._handle
this.handle.onconnection = (err, handle) => {
this.distribute(err, handle)
}
this.server._handle = null
this.server = null
})
}如上所示,RoundRobinHandle 会调用 net.createServer() 创建一个 server,然后调用 listen 方法,最终会来到 setupListenHandle:
// lib/net.js
function setupListenHandle(address, port, addressType, backlog, fd, flags) {
debug('setupListenHandle', address, port, addressType, backlog, fd)
// If there is not yet a handle, we need to create one and bind.
// In the case of a server sent via IPC, we don't need to do this.
if (this._handle) {
debug('setupListenHandle: have a handle already')
} else {
debug('setupListenHandle: create a handle')
let rval = null
// Try to bind to the unspecified IPv6 address, see if IPv6 is available
if (!address && typeof fd !== 'number') {
rval = createServerHandle(DEFAULT_IPV6_ADDR, port, 6, fd, flags)
if (typeof rval === 'number') {
rval = null
address = DEFAULT_IPV4_ADDR
addressType = 4
} else {
address = DEFAULT_IPV6_ADDR
addressType = 6
}
}
if (rval === null)
rval = createServerHandle(address, port, addressType, fd, flags)
if (typeof rval === 'number') {
const error = uvExceptionWithHostPort(rval, 'listen', address, port)
process.nextTick(emitErrorNT, this, error)
return
}
this._handle = rval
}
this[async_id_symbol] = getNewAsyncId(this._handle)
this._handle.onconnection = onconnection
this._handle[owner_symbol] = this
...
}且由于此时 this._handle 为空,会调用 createServerHandle() 生成一个 TCP 对象作为 _handle。之后就跟 SharedHandle 一样了,最后也会回到子进程:
// lib/internal/cluster/child.js
// `obj` is a net#Server or a dgram#Socket object.
cluster._getServer = function (obj, options, cb) {
...
send(message, (reply, handle) => {
if (typeof obj._setServerData === 'function') obj._setServerData(reply.data)
if (handle) {
// Shared listen socket
shared(reply, {handle, indexesKey, index}, cb)
} else {
// Round-robin.
rr(reply, {indexesKey, index}, cb) // cb 是 listenOnPrimaryHandle
}
})
...
}不过由于 RoundRobinHandle 不会传递 handle 给子进程,所以此时会执行 rr:
function rr(message, {indexesKey, index}, cb) {
...
// Faux handle. Mimics a TCPWrap with just enough fidelity to get away
// with it. Fools net.Server into thinking that it's backed by a real
// handle. Use a noop function for ref() and unref() because the control
// channel is going to keep the worker alive anyway.
const handle = {close, listen, ref: noop, unref: noop}
if (message.sockname) {
handle.getsockname = getsockname // TCP handles only.
}
assert(handles.has(key) === false)
handles.set(key, handle)
debugger
cb(0, handle)
}可以看到,这里构造了一个假的 handle,然后执行 cb 也就是 listenOnPrimaryHandle。最终跟 SharedHandle 一样会调用 setupListenHandle 执行 this._handle.onconnection = onconnection。
RoundRobinHandle 逻辑到此就结束了,好像缺了点什么的样子。回顾下,我们给每个子进程中的 server 上都挂载了一个假的 handle,但它跟绑定了端口的 TCP 对象没有任何关系,如果客户端请求过来了,是不会执行它上面的 onconnection 方法的。之所以要这样写,估计是为了保持跟之前 SharedHandle 代码逻辑的统一。
此时,我们需要回到 RoundRobinHandle,有这样一段代码:
// lib/internal/cluster/round_robin_handle.js
this.server.once('listening', () => {
this.handle = this.server._handle
this.handle.onconnection = (err, handle) => {
this.distribute(err, handle)
}
this.server._handle = null
this.server = null
})在 listen 执行完后,会触发 listening 事件的回调,这里重写了 handle 上面的 onconnection。
所以,当客户端请求过来时,会调用 distribute 在多个子进程中轮询分发,这里又有一个 handle,这里的 handle 姑且理解为 clientHandle,即客户端连接的 handle,别搞混了。总之,最后会将这个 clientHandle 发送给子进程:
// lib/internal/cluster/round_robin_handle.js
RoundRobinHandle.prototype.handoff = function (worker) {
...
const message = { act: 'newconn', key: this.key };
// 这里的 handle 是 clientHandle
sendHelper(worker.process, message, handle, (reply) => {
if (reply.accepted) handle.close();
else this.distribute(0, handle); // Worker is shutting down. Send to another.
this.handoff(worker);
});
};而子进程在 require('cluster') 时,已经监听了该事件:
// lib/internal/cluster/child.js
process.on('internalMessage', internal(worker, onmessage))
send({act: 'online'})
function onmessage(message, handle) {
if (message.act === 'newconn') onconnection(message, handle)
else if (message.act === 'disconnect')
ReflectApply(_disconnect, worker, [true])
}最终也同样会走到 net.js 中的 function onconnection(err, clientHandle) 方法。这个方法第二个参数名就叫 clientHandle,这也是为什么前面的 handle 我想叫这个名字的原因。
还是用图来总结下:
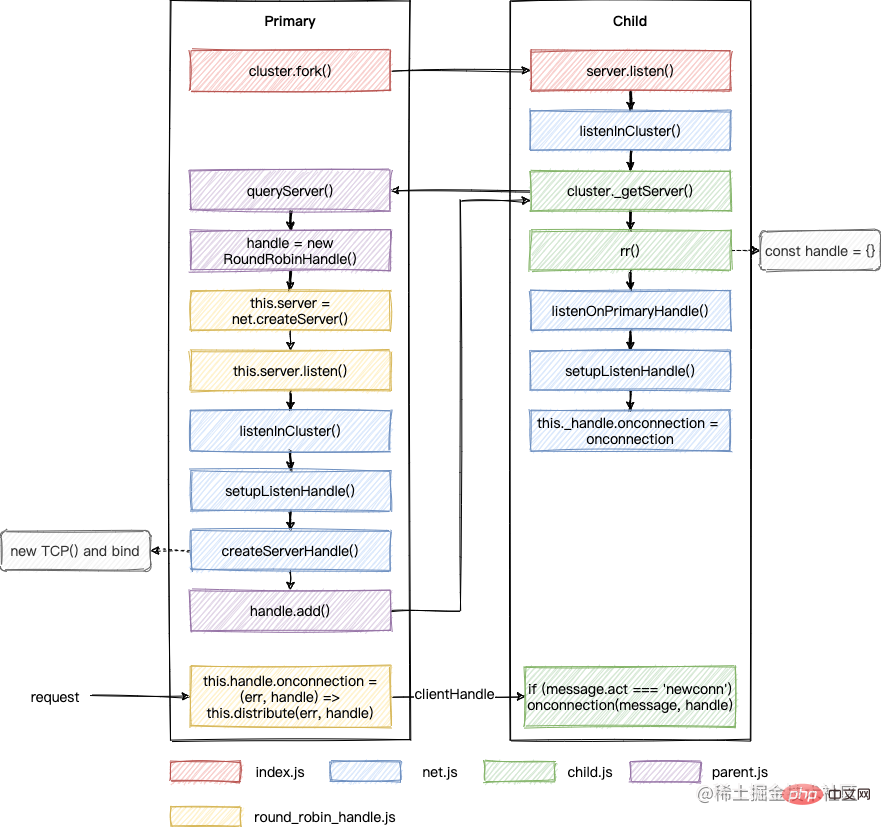
跟 SharedHandle 不同的是,该调度策略中 onconnection 最开始是在主进程中触发的,然后通过轮询算法挑选一个子进程,将 clientHandle 传递给它。
为什么端口不冲突
cluster 模块的调试就到此告一段落了,接下来我们来回答一下一开始的问题,为什么多个进程监听同一个端口没有报错?
网上有些文章说是因为设置了 SO_REUSEADDR,但其实跟这个没关系。通过上面的分析知道,不管什么调度策略,最终都只会在主进程中对 TCP 对象 bind 一次。
我们可以修改一下源代码来测试一下:
// deps/uv/src/unix/tcp.c 下面的 SO_REUSEADDR 改成 SO_DEBUG if (setsockopt(tcp->io_watcher.fd, SOL_SOCKET, SO_REUSEADDR, &on, sizeof(on)))
编译后执行发现,我们仍然可以正常使用 cluster 模块。
那这个 SO_REUSEADDR 到底影响的是啥呢?我们继续来研究一下。
SO_REUSEADDR
首先,我们我们知道,下面的代码是会报错的:
const net = require('net') const server1 = net.createServer() const server2 = net.createServer() server1.listen(9999) server2.listen(9999)
但是,如果我稍微修改一下,就不会报错了:
const net = require('net') const server1 = net.createServer() const server2 = net.createServer() server1.listen(9999, '127.0.0.1') server2.listen(9999, '10.53.48.67')
原因在于 listen 时,如果不指定 address,则相当于绑定了所有地址,当两个 server 都这样做时,请求到来就不知道要给谁处理了。
我们可以类比成找对象,port 是对外貌的要求,address 是对城市的要求。现在甲乙都想要一个 port 是 1米7以上 不限城市的对象,那如果有一个 1米7以上 来自 深圳 的对象,就不知道介绍给谁了。而如果两者都指定了城市就好办多了。
那如果一个指定了 address,一个没有呢?就像下面这样:
const net = require('net') const server1 = net.createServer() const server2 = net.createServer() server1.listen(9999, '127.0.0.1') server2.listen(9999)
结果是:设置了 SO_REUSEADDR 可以正常运行,而修改成 SO_DEBUG 的会报错。
还是上面的例子,甲对城市没有限制,乙需要是来自 深圳 的,那当一个对象来自 深圳,我们可以选择优先介绍给乙,非 深圳 的就选择介绍给甲,这个就是 SO_REUSEADDR 的作用。
补充
<span style="font-size: 18px;">SharedHandle</span> 和 <span style="font-size: 18px;">RoundRobinHandle</span> 两种模式的对比
先准备下测试代码:
// cluster.js
const cluster = require('cluster')
const net = require('net')
if (cluster.isMaster) {
for (let i = 0; i < 4; i++) {
cluster.fork()
}
} else {
const server = net.createServer()
server.on('connection', (socket) => {
console.log(`PID: ${process.pid}!`)
})
server.listen(9997)
}// client.js
const net = require('net')
for (let i = 0; i < 20; i++) {
net.connect({port: 9997})
}RoundRobin先执行 node cluster.js,然后执行 node client.js,会看到如下输出,可以看到没有任何一个进程的 PID 是紧挨着的。至于为什么没有一直按照一样的顺序,后面再研究一下。
PID: 42904! PID: 42906! PID: 42905! PID: 42904! PID: 42907! PID: 42905! PID: 42906! PID: 42907! PID: 42904! PID: 42905! PID: 42906! PID: 42907! PID: 42904! PID: 42905! PID: 42906! PID: 42907! PID: 42904! PID: 42905! PID: 42906! PID: 42904!
Shared
先执行 NODE_CLUSTER_SCHED_POLICY=none node cluster.js,则 Node.js 会使用 SharedHandle,然后执行 node client.js,会看到如下输出,可以看到同一个 PID 连续输出了多次,所以这种策略会导致进程任务分配不均的现象。就像公司里有些人忙到 996,有些人天天摸鱼,这显然不是老板愿意看到的现象,所以不推荐使用。
PID: 42561! PID: 42562! PID: 42561! PID: 42562! PID: 42564! PID: 42561! PID: 42562! PID: 42563! PID: 42561! PID: 42562! PID: 42563! PID: 42564! PID: 42564! PID: 42564! PID: 42564! PID: 42564! PID: 42563! PID: 42563! PID: 42564! PID: 42563!
更多node相关知识,请访问:nodejs 教程!
The above is the detailed content of An article to talk about cluster in Node.js. For more information, please follow other related articles on the PHP Chinese website!