
Home >Java >javaTutorial >Detailed analysis of java lexical analyzer DDL recursive application
Detailed analysis of java lexical analyzer DDL recursive application

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2022-07-25 17:35:472511browse
This article brings you relevant knowledge about java. It mainly introduces the detailed explanation of DDL recursive application of java lexical analyzer. Friends in need can refer to it. Let’s take a look at it together. I hope everyone has to help.

Recommended study: "java video tutorial"
intellij plugin
Since there is no ready-made tool, then Write one yourself
Considering that we mainly use PyCharm for development, jetbrains also provides SDK for developing plug-ins, soUI There is no need to consider additional aspects.
The usage process is very simple. You only need to import the DDL statement to generate the Model code required by Python.
For example, import the following DDL:
CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `userName` varchar(20) DEFAULT NULL COMMENT '用户名', `password` varchar(100) DEFAULT NULL COMMENT '密码', `roleId` int(11) DEFAULT NULL COMMENT '角色ID', PRIMARY KEY (`id`), ) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8
The corresponding Python code will be generated:
class User(db.Model):
__tablename__ = 'user'
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
userName = db.Column(db.String) # 用户名
password = db.Column(db.String) # 密码
roleId = db.Column(db.Integer) # 角色IDLexical analysis
It will be very easy to carefully compare the source file and the target code It is easy to find the pattern, which is nothing more than parsing out the table name, field, and field attributes (whether it is the primary key, type, length), and finally converting it into the template required by Python.
Before I started, I thought it was very simple. It was nothing more than parsing strings, but in fact, after I started, I found that it was not the case; mainly there are the following problems:
- How to identify the table name?
- Similarly, how to identify the field name, and also associate the type, length, and comments of the field.
- How to identify the primary key?
To summarize in one sentence, how to identify the key information in a string through a series of rules is also what MySQL Server does.
Before we start to actually parse DDL, let’s first look at how to parse the next simple script:
x = 20
According to what we usually develop Experience, this statement is divided into the following parts:
-
xrepresents the variable -
=represents the assignment symbol -
20represents the assignment result
So our analysis result of this script should be:
VAR x
GE =
VAL 100
This parsing process is called "lexical parsing" in the compilation principle. You may be confused when you hear the words compilation principle (me too); for what I just said In that script we can write a very simple lexical parser to generate such results.
State migration
Let’s think about it before starting again. You can see that in the above results, VAR represents variables and GE represents assignment. The symbols "=" and VAL represent the assignment results. Now you need to focus on remembering these three states.
When reading and parsing characters in sequence, the program switches back and forth between these states, as shown below:
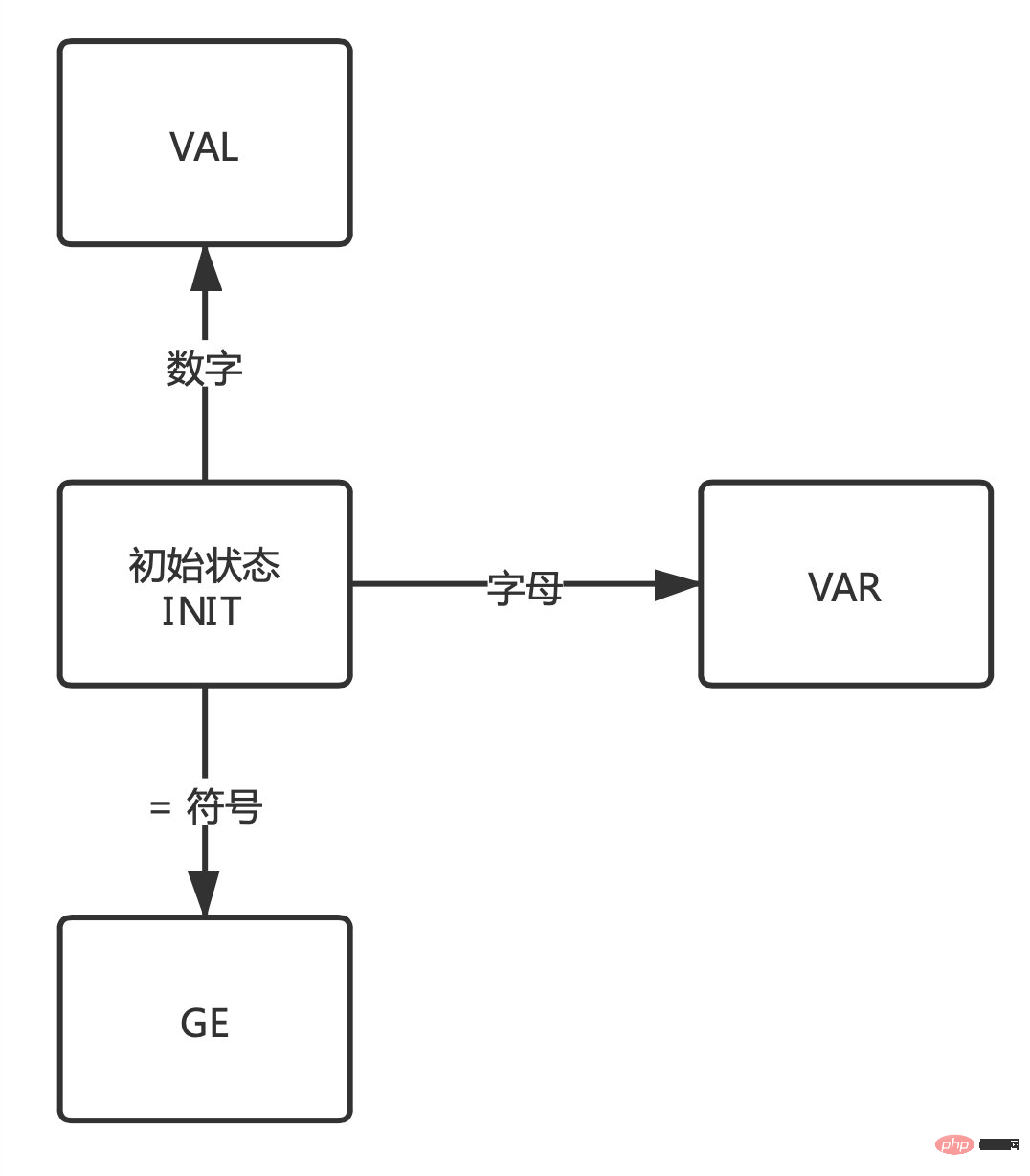
- The default is the initial state .
- When the character is a letter, it enters the
VARstate. - When the character is the "=" symbol, it enters the
GEstate.
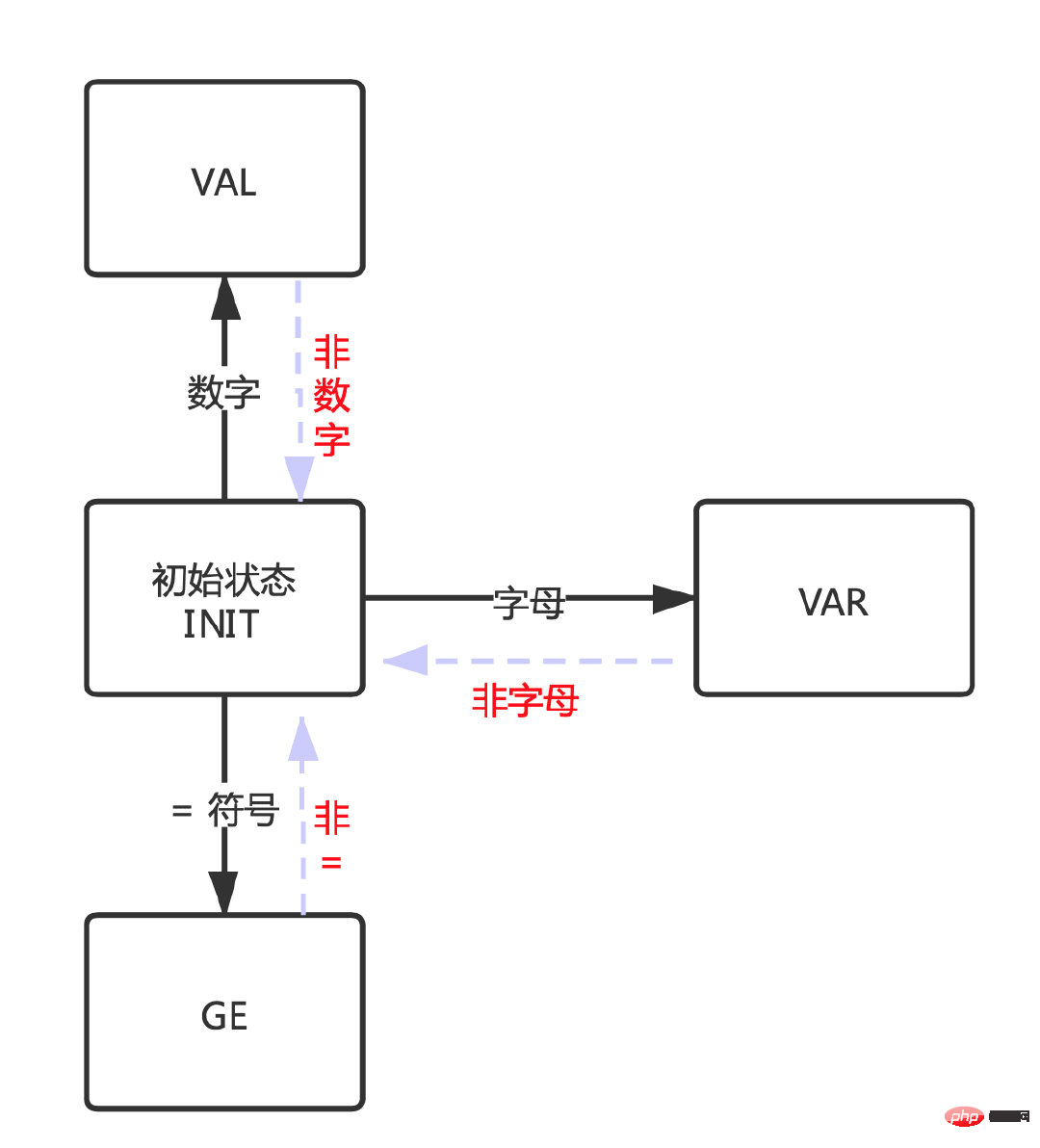
Similarly, when these states are not satisfied, it will return to the initial state to confirm the new state again.
Just looking at the picture is a bit abstract, let’s look directly at the core code:
public class Result{
public TokenType tokenType ;
public StringBuilder text = new StringBuilder();
} first defines a result class to collect the final analysis results; TokenType corresponds to The three states in the figure are simply represented by enumeration values.
public enum TokenType {
INIT,
VAR,
GE,
VAL
}First corresponds to the first picture: initialization state.
Need to define a TokenType for the currently parsed character:
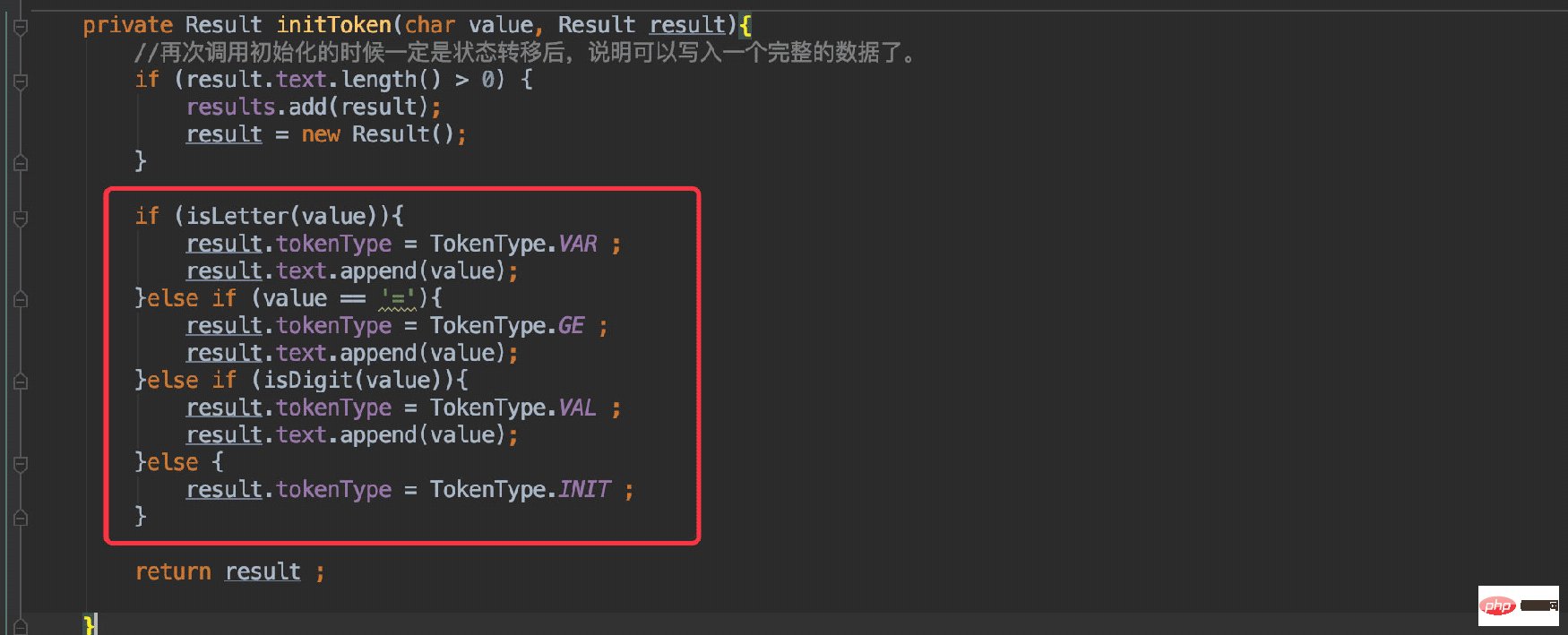
is consistent with the process described in the figure, and determines the current character given Just one status.
Then corresponds to the second picture: the transition between states.
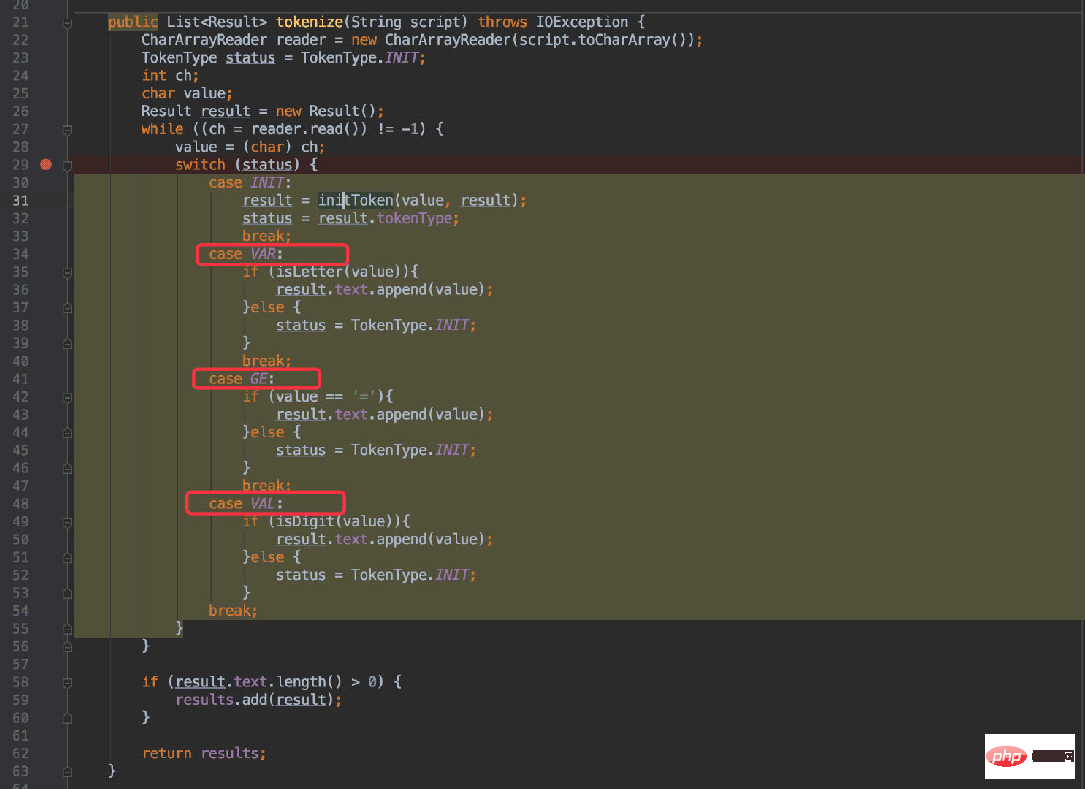
will enter different case according to different states, and judge whether it should jump to other states in different case (The state will be regenerated after entering the INIT state).
For example: x = 20:
The first choice will enter the VAR state, and then the next character is a space, naturally in line 38 Re-enter the initial state, causing the next character = to be determined again and enter the GE state.
When the script is ab = 30:
The first character is a, which also enters the VAR state, and the second character is b, which is still a letter. Therefore, when entering line 36, the status will not change, and the character b will be appended; the subsequent steps will be consistent with the previous example.
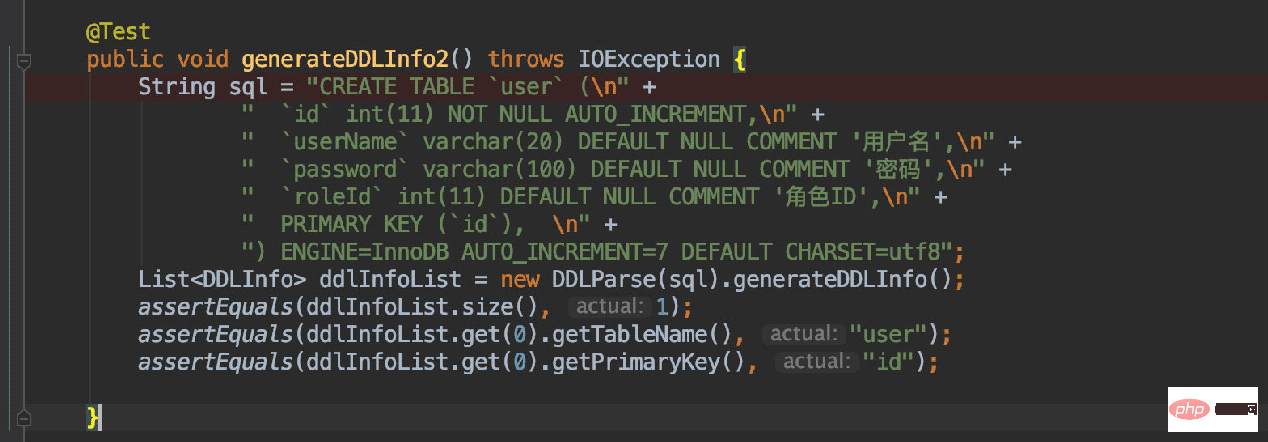
It’s useless to say more. I suggest you run the single test yourself and you will understand:
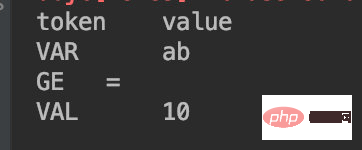
DDL 解析
简单的解析完成后来看看DDL这样的脚本应当如何解析:
CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `userName` varchar(20) DEFAULT NULL COMMENT '用户名', `password` varchar(100) DEFAULT NULL COMMENT '密码', `roleId` int(11) DEFAULT NULL COMMENT '角色ID', PRIMARY KEY (`id`), ) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8
原理类似,首先还是要看出规律(也就是语法):
- 表名是第一行语句,同时以
CREATE TABLE开头。 - 每一个字段的信息(名称、类型、长度、备注)都是以 “`” 符号开头 “,” 结尾。
- 主键是以 PRIMART 字符串开头的字段,以
)结尾。
根据我们需要解析的数据种类,我这里定义了这个枚举:
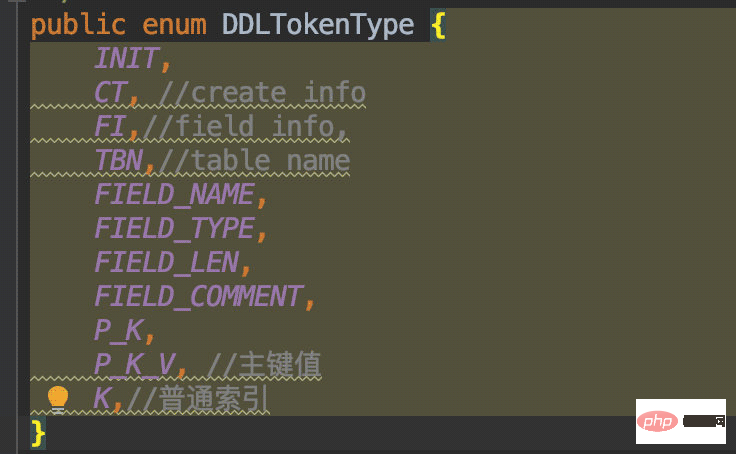
然后在初始化类型时进行判断赋值:
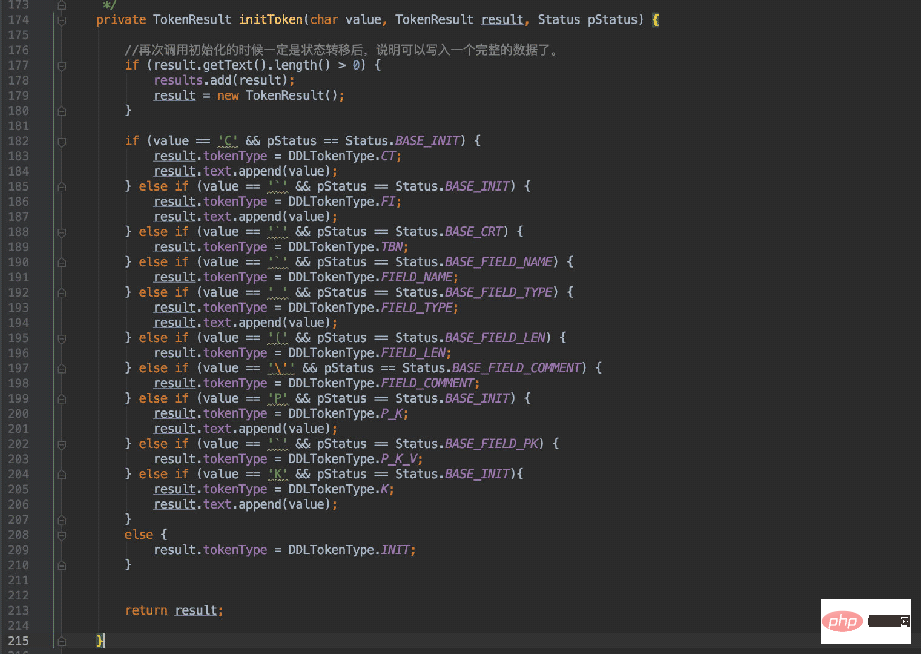
由于需要解析的数据不少,所以这里的判断条件自然也就多了。
递归解析
针对于DDL的语法规则,我们这里还有需要有特殊处理的地方;比如解析具体字段信息时如何关联起来?
举个例子:
`userName` varchar(20) DEFAULT NULL COMMENT '用户名', `password` varchar(100) DEFAULT NULL COMMENT '密码',
这里我们解析出来的数据得有一个映射关系:
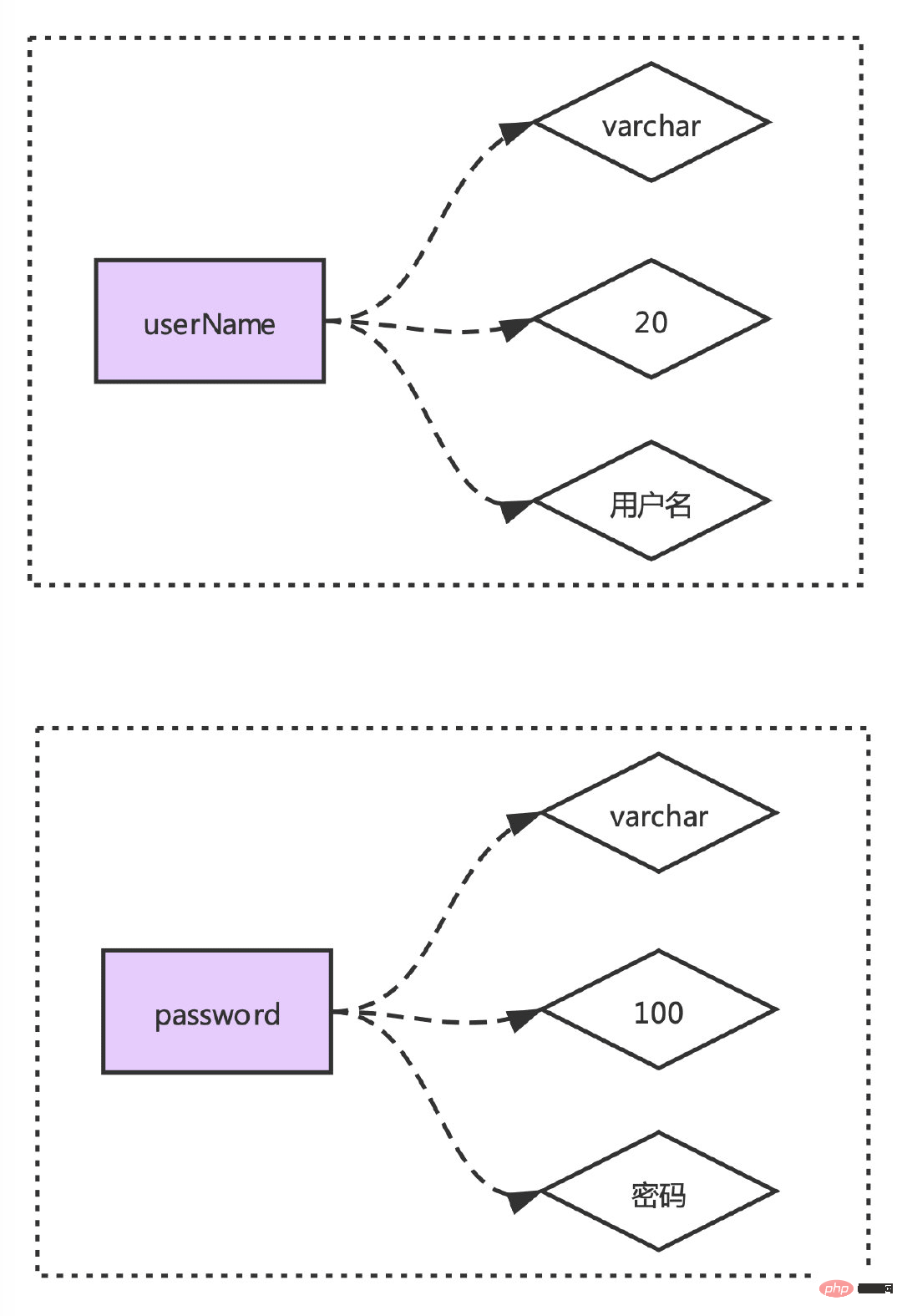
所以我们只能一个字段的全部信息解析完成并且关联好之后才能解析下一个字段。
于是这里我采用了递归的方式进行解析(不一定是最好的,欢迎大家提出更优的方案)。
} else if (value == '`' && pStatus == Status.BASE_INIT) {
result.tokenType = DDLTokenType.FI;
result.text.append(value);
}当当前字符为 ”`“ 符号时,将状态置为 “FI”(FieldInfo),同时当解析到为 “,” 符号时便进入递归处理。
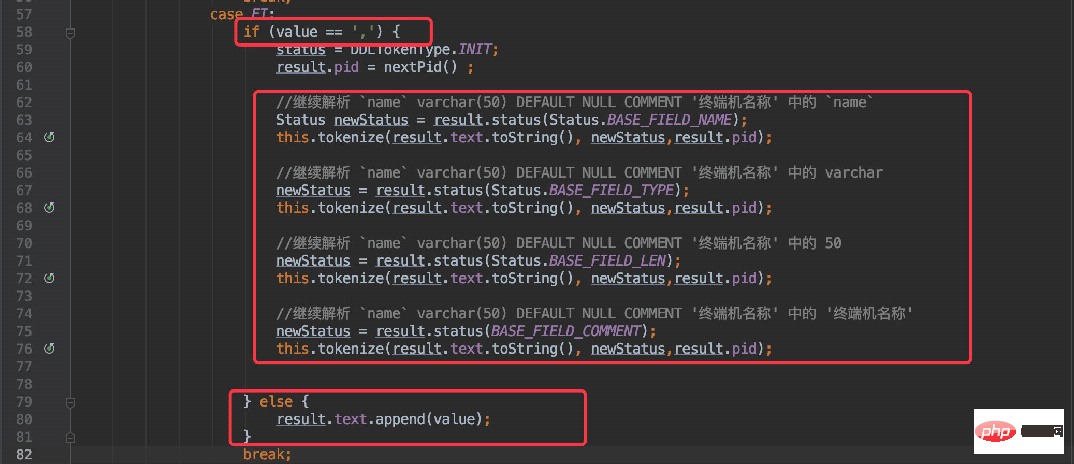
可以理解为将这一段字符串单独提取出来处理:
`userName` varchar(20) DEFAULT NULL COMMENT '用户名',
接着再将这段字符递归调用当前方法再次进行解析,这时便按照字段名称、类型、长度、注释的规则解析即可。
同时既然存在递归,还需要将子递归的数据关联起来,所以我在返回结果中新增了一个pid的字段,这个也容易理解。
默认值为 0,一旦递归后便自增 +1,保证每次递归的数据都是唯一的。
用同样的方法在解析主键时也是先将整个字符串提取出来:
PRIMARY KEY (`id`)
只不过是 “P” 打头 “)” 结尾。
} else if (value == 'P' && pStatus == Status.BASE_INIT) {
result.tokenType = DDLTokenType.P_K;
result.text.append(value);
}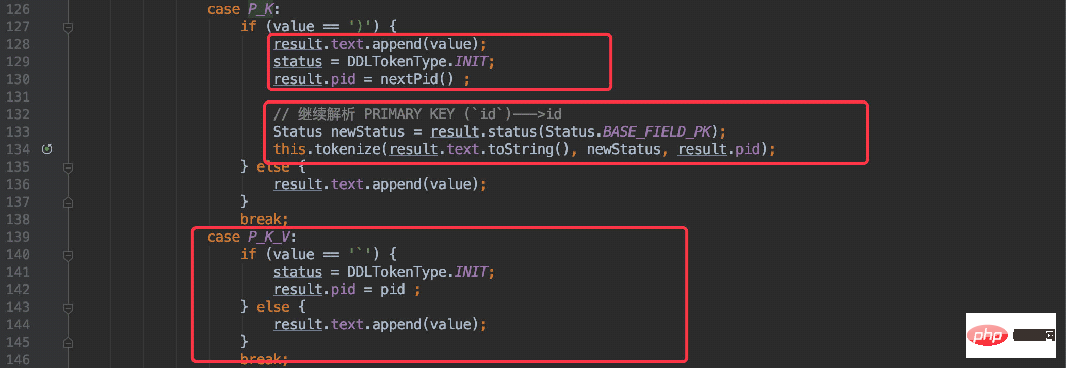
也是将整段字符串递归解析,再递归的过程中进行状态切换P_K ---> P_K_V最终获取到主键。
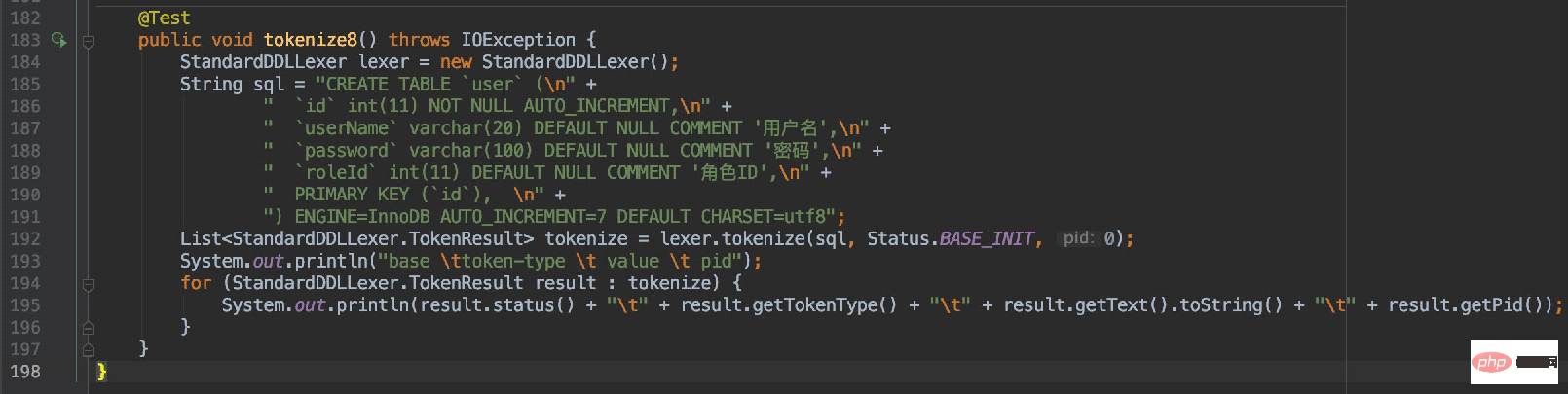
所以通过对刚才那段DDL解析得到的结果如下:
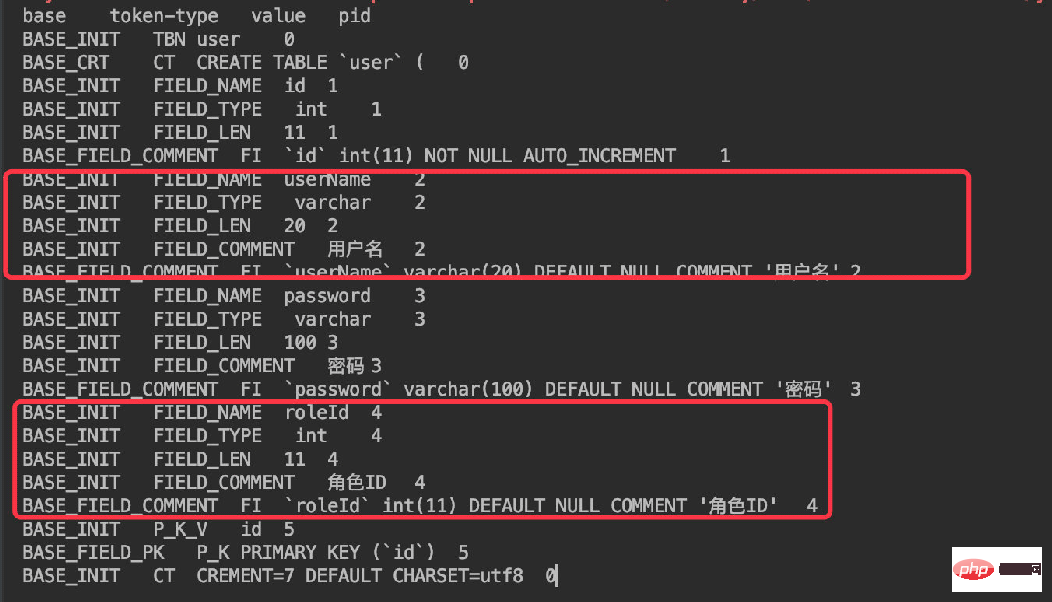
这样每个字段也通过了pid进行了区分关联。
所以现在只需要对这个词法解析器进行封装,便可以提供一个简单的API来获取表中的数据了。
推荐学习:《java视频教程》
The above is the detailed content of Detailed analysis of java lexical analyzer DDL recursive application. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Detailed example of implementing a simple version of the library management system in Java
- How does JavaScript process the addition, deletion, modification and query of tree-structured data?
- A brief introduction to Java Servlet programs
- Summary of 10,000-word graphic JavaScript notes
- Briefly summarize the four creation methods of java thread pool