
Detailed graphic explanation of Redis cluster and expansion

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2022-07-13 13:59:351982browse
This article brings you relevant knowledge about Redis, which mainly organizes issues related to clustering and expansion. The usual way to achieve high availability is to copy multiple copies of the database to deploy it in On different servers, one of them can continue to provide services even if one of them fails. There are three deployment modes to achieve high availability: master-slave mode, sentinel mode, and cluster mode. Let’s take a look at them together. I hope it will be helpful to everyone.

Recommended learning: Redis video tutorial
High availability of Redis
1. Why high availability is required
- Prevent single point of failure from causing the entire cluster to become unavailable
- Common practices for achieving high availability It is to copy multiple copies of the database and deploy them on different servers. If one of them hangs up, it can continue to provide services.
- Redis has three deployment modes to achieve high availability: Master-slave mode, sentinel mode, Cluster mode
2. Master-slave mode
- The master nodeis responsible forreading and writingoperations
- The slave node is only responsible for reading operations
- The data of the slave node comes from the master node , and the implementation principle is the master-slave replication mechanism
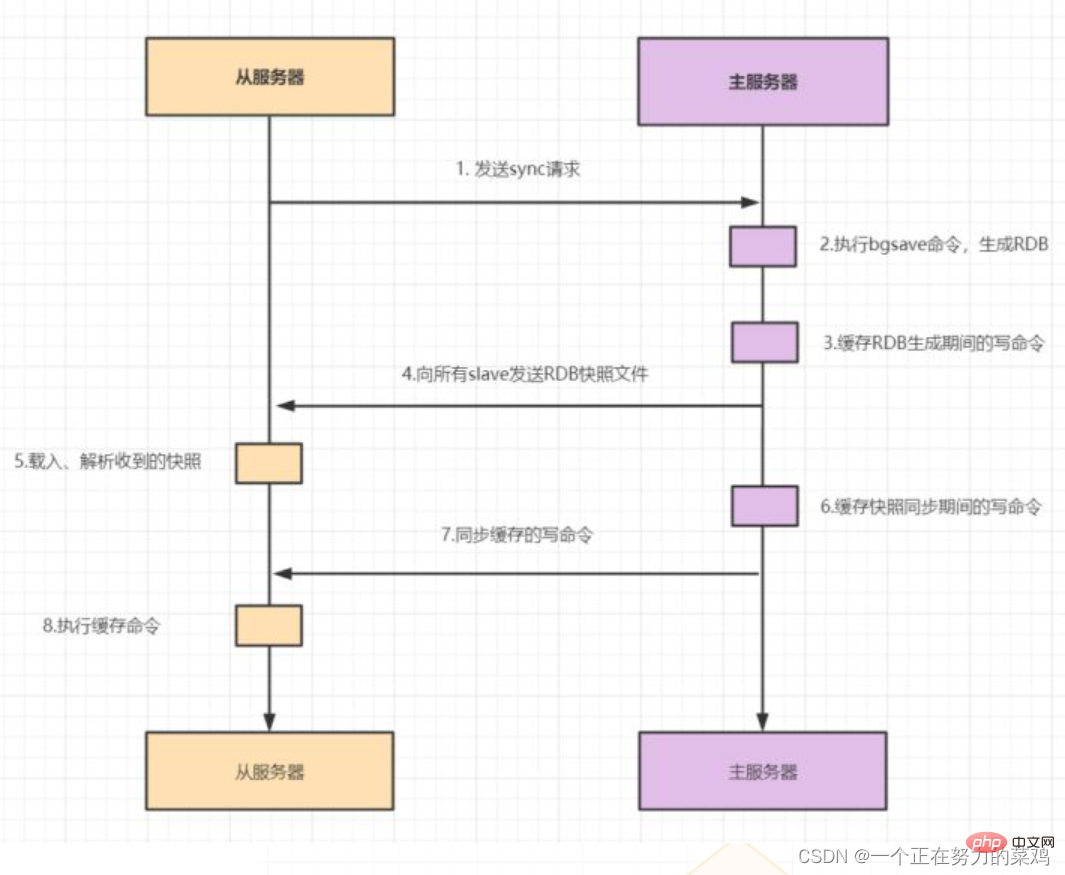
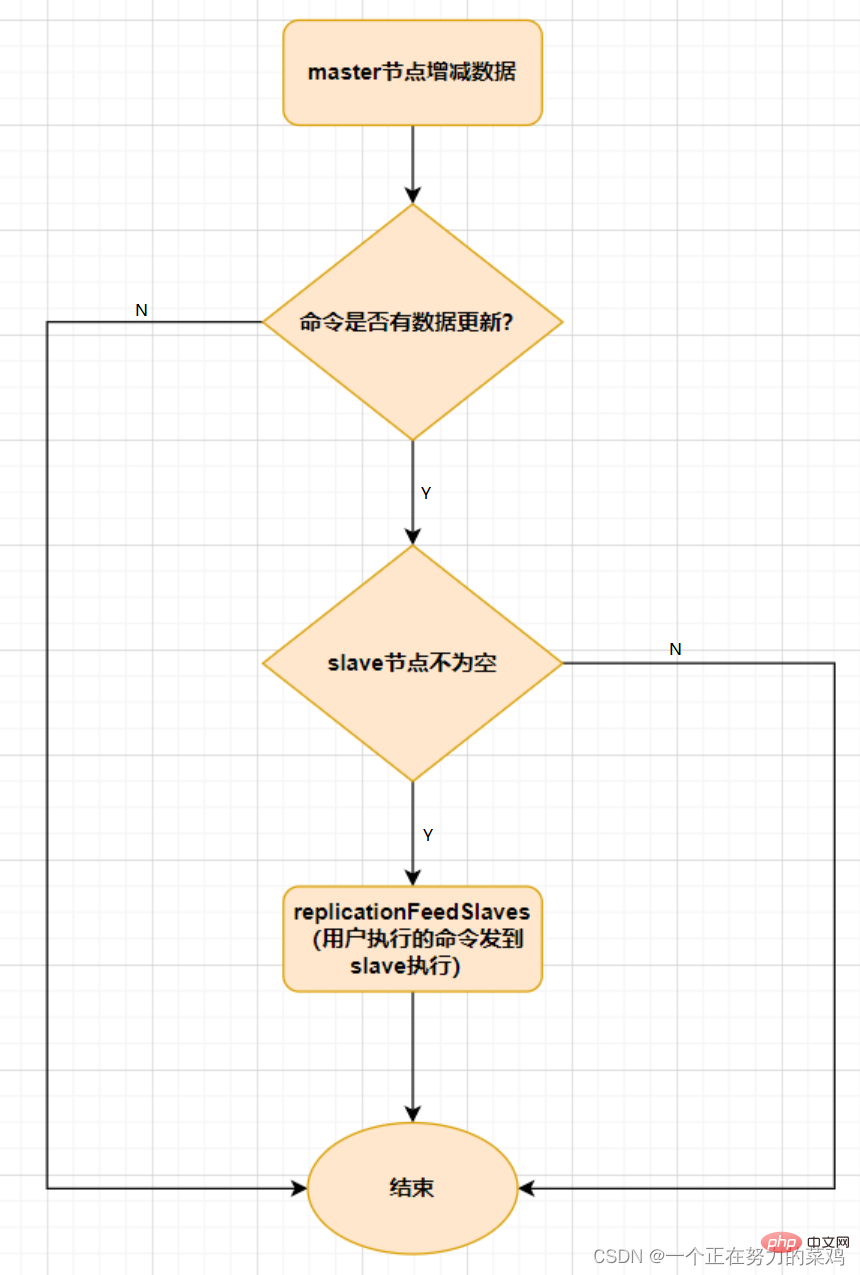
- Master-slave replication includes full replication and incremental replicationtwo kinds
-
When the slave starts to connect to the master for the first time, or it is considered to be the first Full replication is used for each connection

-
After the slave is fully synchronized with the master, if the data on the master is updated again, incremental replication will be triggered
3. Sentinel mode
- In master-slave mode, once the master node cannot provide services due to failure, it needs to be manually promoted from the slave node to the master node , and at the same time, the application side must be notified to update the master node address. Obviously, most business scenarios cannot accept this fault handling method. Redis has officially provided the Redis Sentinel (Sentinel) architecture to solve this problem since 2.8.
- Sentinel mode It is a Sentinel system composed of one or more Sentinel instances. It can monitor all Redis master nodes and slave nodes , and automatically remove the offline master when the monitored master node enters the offline state. A slave node under the server is upgraded to a new master node
- However, if a sentinel process monitors the Redis node, problems (single points) may occur, so multiple sentinels can be used. Redis nodes are monitored, and each sentinel is also monitored
- Simply speaking, the sentinel mode has three functions
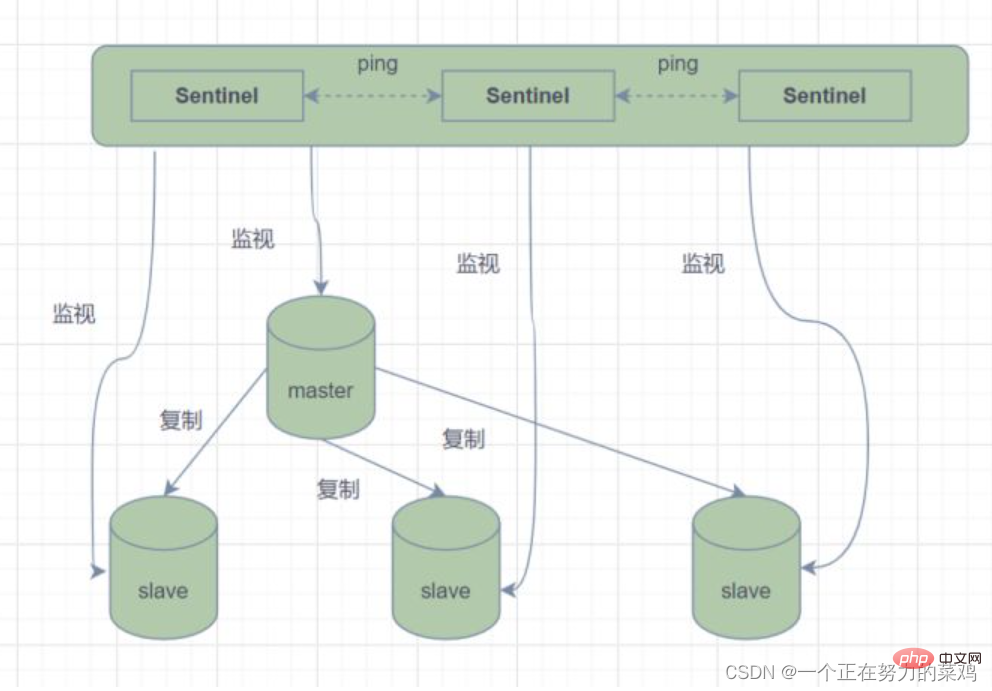
1.发送命令,等待Redis服务器(包括主服务器和从服务器)返回监控其运行状态 2.哨兵监测到主节点宕机会自动将从节点切换成主节点,然后通过发布订阅模式通知其他的从节点修改配置文件,让它们切换主机 3.哨兵之间还会相互监控,从而达到高可用
- Fault The switching process is as follows
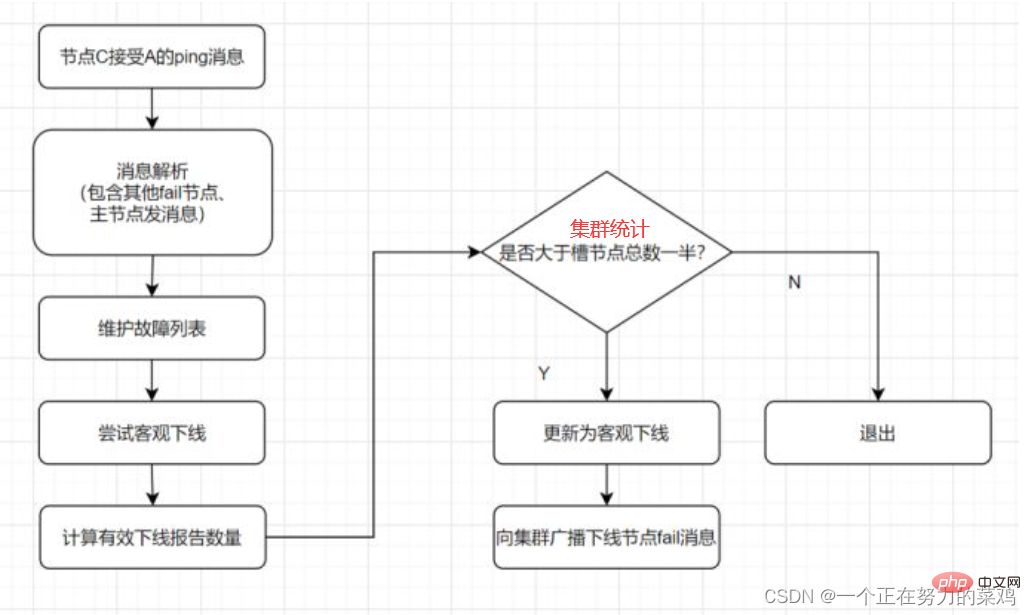
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行 failover 过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象称为主观下线 当后面的哨兵也检测到主服务器不可用并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover操作 切换成功后通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线 这样对于客户端而言,一切都是透明的
- Sentinel working mode
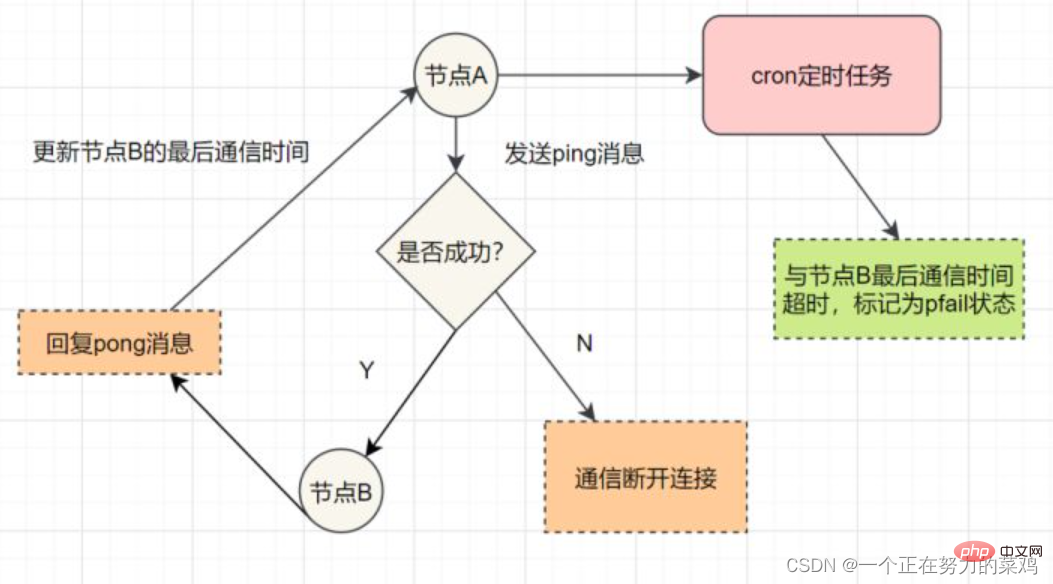
每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他Sentinel实例发送一个PING命令 如果实例距离最后一次有效回复PING命令的时间超过down-after-milliseconds选项所指定的值,则这个实例会被Sentinel标记为主观下线 如果一个Master被标记为主观下线,则正在监视这个Master的所有Sentinel要以每秒一次的频率确认Master的确进入了主观下线状态 当有足够数量的Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态,则Master会被标记为客观下线 一般情况下,每个Sentinel会以每10秒一次的频率向它已知的所有Master,Slave发送INFO命令 当Master被Sentinel标记为客观下线时,Sentinel向下线的Master的所有Slave发送INFO命令的频率会从10秒一次改为每秒一次 若没有足够数量的Sentinel同意Master已经下线,Master的客观下线状态就会被移除;若Master重新向Sentinel的PING命令返回有效回复,Master 的主观下线状态就会被移除
4.Cluster cluster mode
- Sentinel mode is based on master-slave mode , realizes read-write separation, can also automatically switch, and has higher system availability. However, the data stored in each node is the same, which wastes memory and is not easy to expand online. Therefore, the Cluster cluster came into being and was added in Redis 3.0. The
- Cluster cluster implements distributed storage of Redis and shards the data, that is to say stores different content on each Redis node, toSolve the problem of online expansion, and it alsoprovides replication and failover functions
- Redis Cluster cluster communicates through Gossip protocol, between nodes Continuously exchange information. The information exchanged includes node failure, new node joining, master-slave node change information, slot information, etc.. Commonly used gossip messages are ping, pong, meet, fail
ping消息:集群内交换最频繁的消息,集群内每个节点每秒向多个其他节点发送ping消息,用于检测节点是否在线和交换彼此状态信息 meet消息:通知新节点加入,消息发送者通知接收者加入到当前集群,meet消息通信正常完成后,接收节点会加入到集群中并进行周期性的ping、pong消息交换 pong消息:当接收到ping、meet消息时,作为响应消息回复给发送方确认消息正常通信;pong消息内部封装了自身状态数据,节点也可以向集群内广播自身的pong消息来通知整个集群对自身状态进行更新 fail消息:当节点判定集群内另一个节点下线时,会向集群内广播一个fail消息,其他节点接收到fail消息之后把对应节点更新为下线状态
- Hash Slot slot algorithm
既然是分布式存储,Cluster集群使用的分布式算法是一致性Hash嘛?并不是,而是Hash Slot插槽算法 插槽算法把整个数据库被分为16384个slot(槽),每个进入Redis的键值对根据key进行散列,分配到这16384插槽中的一个 使用的哈希映射也比较简单,用CRC16算法计算出一个16位的值,再对16384取模,数据库中的每个键都属于这16384个槽的其中一个,集群中的每个节点都可以处理这16384个槽 集群中的每个节点负责一部分的hash槽,比如当前集群有A、B、C个节点,每个节点上的哈希槽数 =16384/3,那么就有: 节点A负责0~5460号哈希槽 节点B负责5461~10922号哈希槽 节点C负责10923~16383号哈希槽Redis Cluster集群中,需要确保16384个槽对应的node都正常工作,如果某个node出现故障,它负责的slot也会失效,整个集群将不能工作 为了保证高可用,Cluster集群引入了主从复制,一个主节点对应一个或者多个从节点,当其它主节点ping一个主节点A时,如果半数以上的主节点与 A通信超时,那么认为主节点A宕机,如果主节点宕机时,就会启用从节点Redis的每一个节点上都有两个玩意,一个是插槽slot(0~16383),另外一个是cluster,可以理解为一个集群管理的插件,当我们存取的key到达时,Redis会根据Hash Slot插槽算法取到编号在0~16383之间的哈希槽,通过这个值去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作
5. Failover issues after achieving high availability
-
Subjective offline : A node thinks that another node is unavailable, that is, offline. This state is not the final fault determination. It can only represent the opinion of one node. There may be misjudgment
-
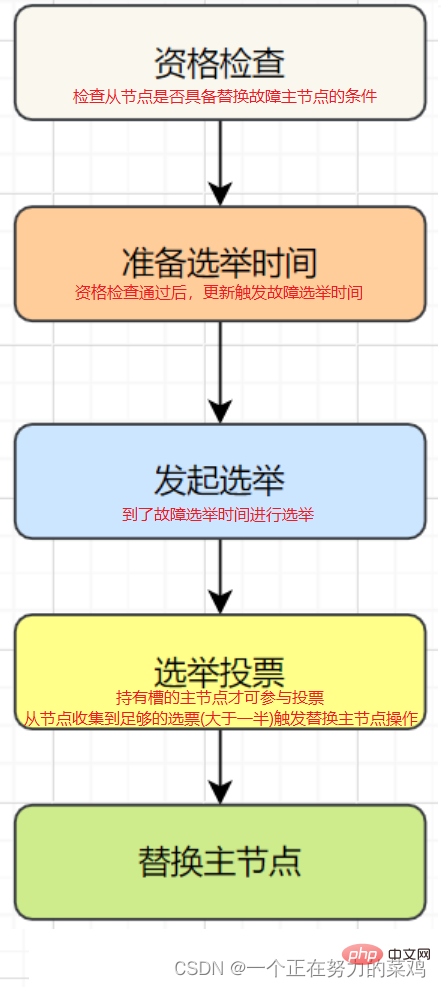
Objective offline: Marks a node as being truly offline. Multiple nodes in the cluster consider the node to be unavailable, thus reaching a consensus. If the master node holding the slot fails, it is necessary to Perform failover for the node
-
Failure recovery: After the fault is discovered, if the offline node is the master node, you need to choose a replacement from its slave node It is used to ensure the high availability of the cluster
A series of problems caused by Redis distributed locks and their solutions
1.Redisson
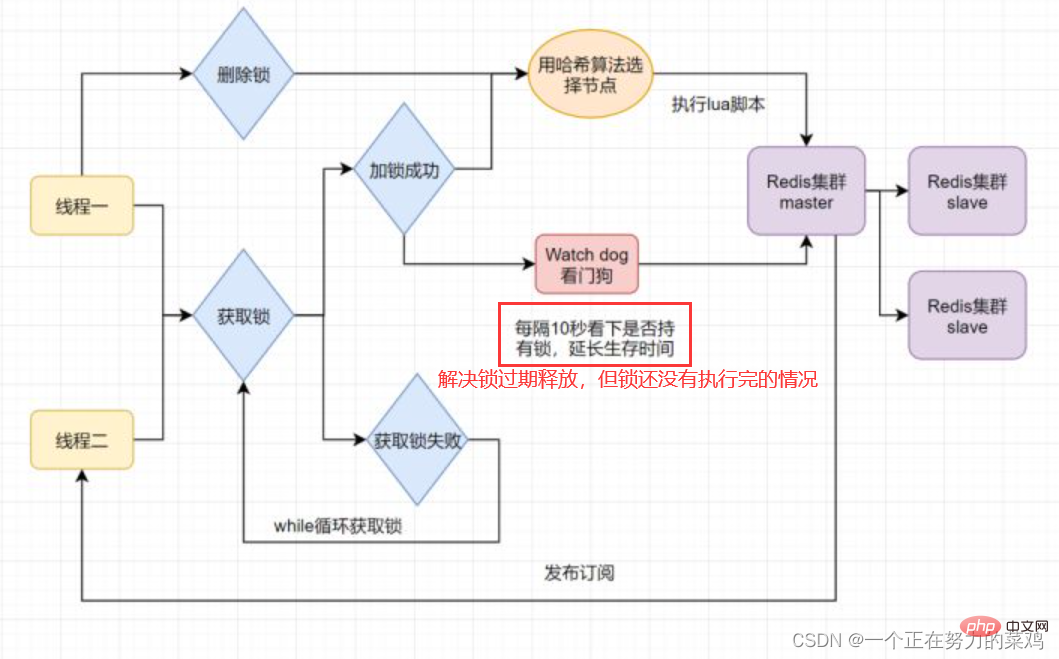
- Distributed locks may have problemsthe lock is released after expiration and the business is not completed
- Can the expiration time of the lock be set longer to solve this problem? Obviously it is not good. The execution time of the business is uncertain.
- Redisson solves this problem by opening a timed daemon thread for the thread that obtains the lock. It checks whether the lock exists every once in a while and extends the lock if it exists. Expiration time to prevent lock expiration and early release
2.Redlock algorithm
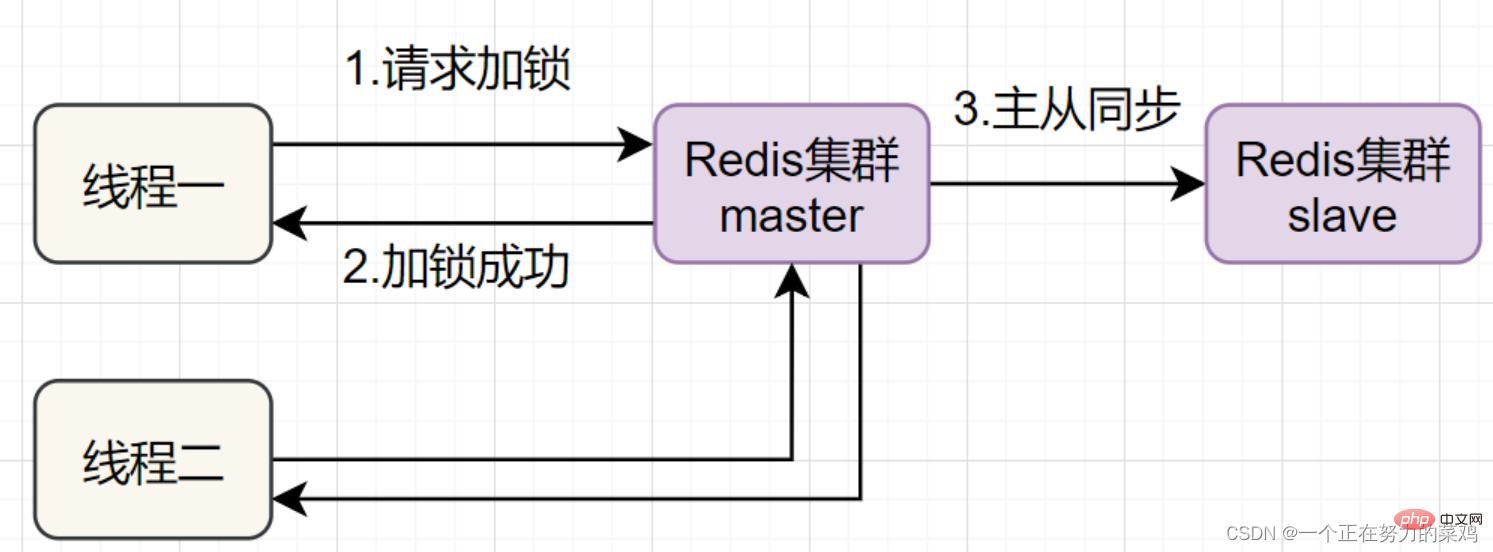
- Thread 1 got the lock on the Redis master node, but the locked key has not yet been synchronized to the slave node. At this time, the master node fails, and a slave node will be upgraded to the master node. Thread two can obtain the lock of the same key, but thread one has also obtained the lock, and the security of the lock is gone.
-
RedlockTo solve this problem, deploy multiple Redis masters to ensure that they will not go down at the same time, and these master nodes are completely independent of each other, There is no data synchronization between each other. The implementation steps are as follows
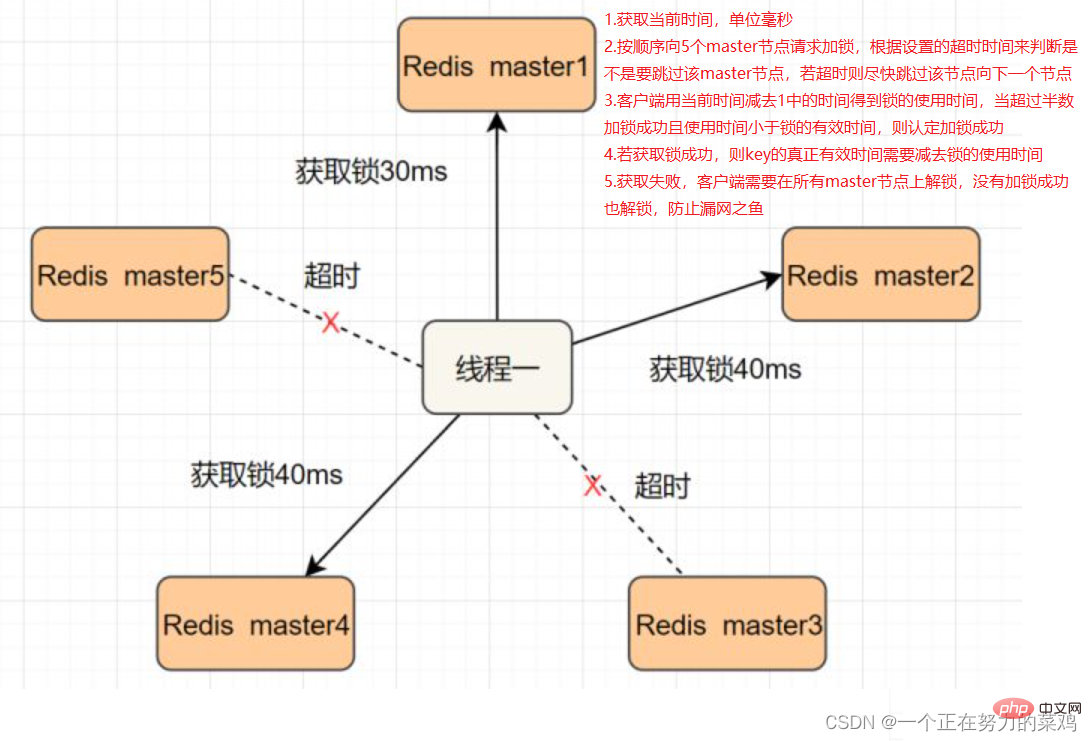
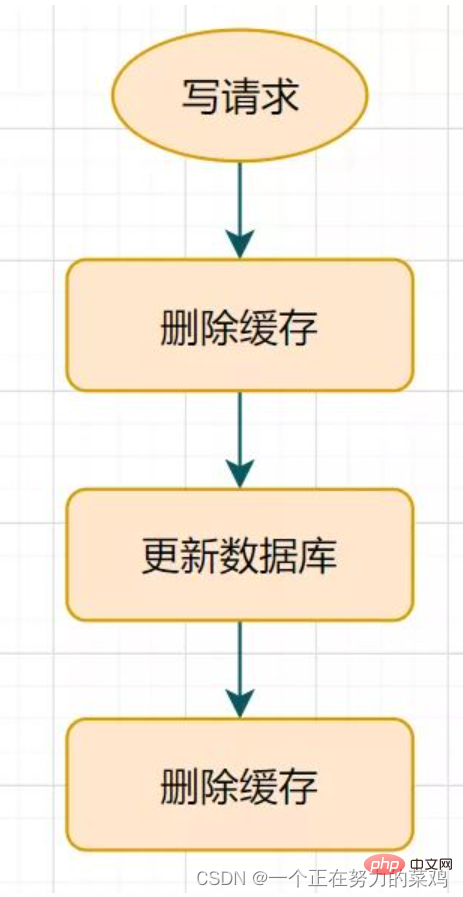
- After updating the database, delay sleeping for a while and then delete the cache
- This solution is okay. Only during the sleeping period, there may be dirty data, and it will be accepted by general businesses.
- But what if deleting the cache fails for the second time? The data in the cache and the database may still be inconsistent.
- How about setting a natural expire expiration time for the Key and letting it expire automatically? What should I do if the data accepted by the business within the expiration time is inconsistent? There are still other better solutions
-
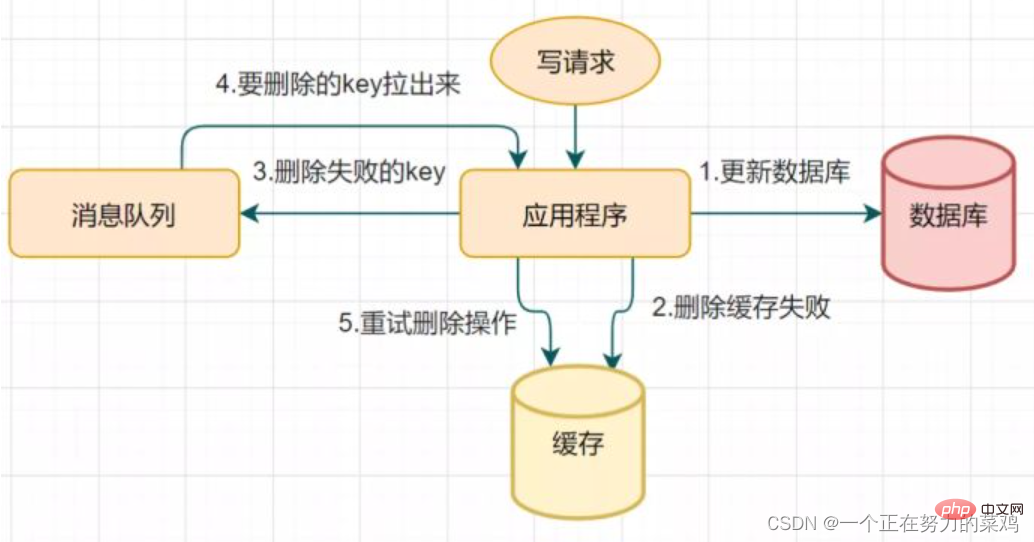
- Delayed double deletion may cause a second step of deleting the cache Failure, resulting in data inconsistency issues
- If deletion fails, delete it a few times to ensure that the cache deletion is successful, so you can introduce a
- delete cache retry mechanism
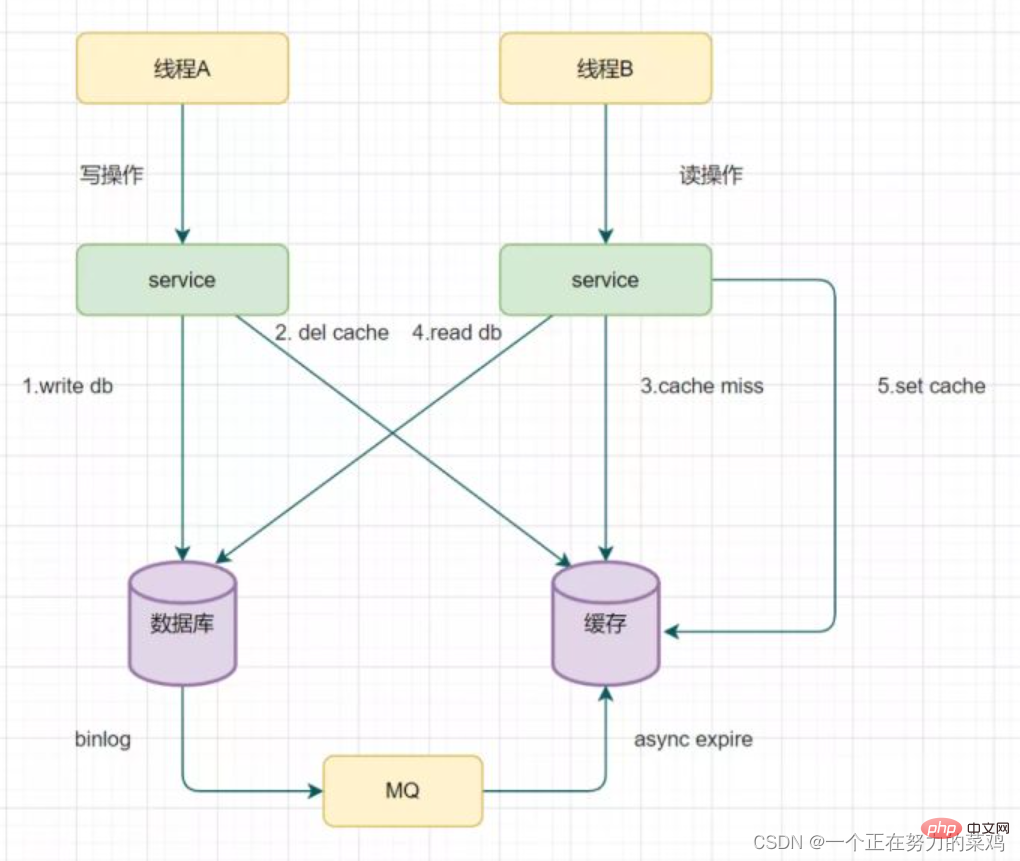
- Retrying to delete the cache mechanism will cause a lot of business code intrusions, so we introduced reading biglog and asynchronously deleting the cache
-
The above is the detailed content of Detailed graphic explanation of Redis cluster and expansion. For more information, please follow other related articles on the PHP Chinese website!
Statement:
This article is reproduced at:csdn.net. If there is any infringement, please contact admin@php.cn delete
Previous article:Redis Learning: Basic Use of JedisNext article:Redis Learning: Basic Use of Jedis