
Home >Database >Mysql Tutorial >In-depth analysis of indexes in mysql (detailed explanation of principles)
In-depth analysis of indexes in mysql (detailed explanation of principles)

- 青灯夜游forward
- 2022-07-01 10:07:232957browse
This article will give you an in-depth analysis of the index in mysql and help you understand the principle of mysql index. I hope it will be helpful to you!

1. What is an index
The index is a sorted data structure that helps MySQL obtain data efficiently
Prerequisite knowledge: The lower the height of the tree, the higher the query efficiency.
2. Index data structure
Data structure simulation website: https://www.cs.usfca.edu/~galles/visualization/Algorithms. html
(1) Binary tree
Problem: It cannot be self-balancing, and skew occurs in extreme cases. The query efficiency is similar to that of a linked list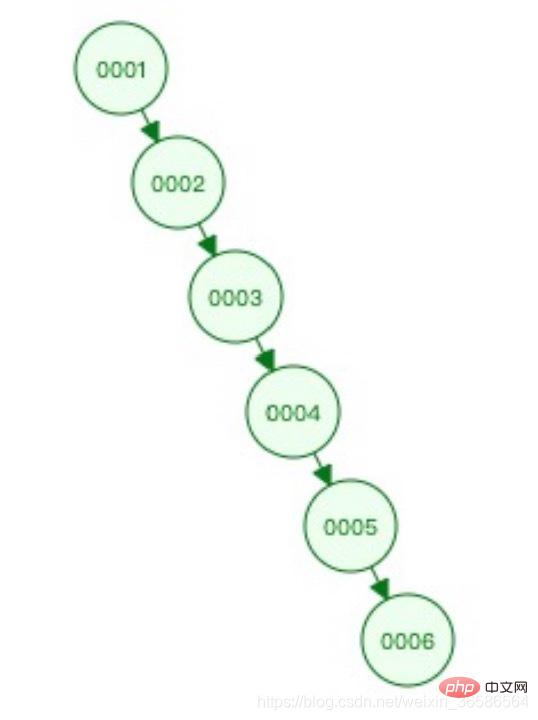
(2) Red-black tree
Red and black The tree balances the data and solves the problem of unilateral growth;
Problem: It is not suitable for large amounts of data. When the amount of data is large, the height of the tree is uncontrollable. From the root node to the leaf node, multiple traversals are required. , the efficiency is low. 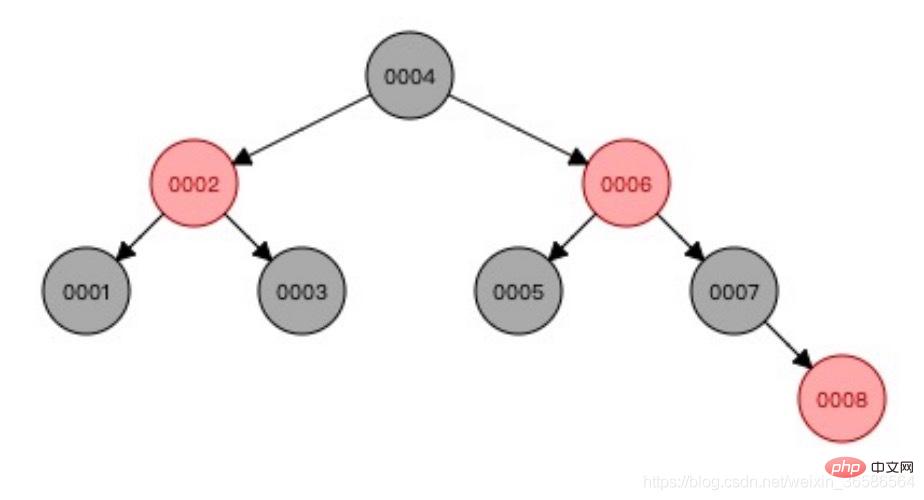
(3) Hash
1. Perform a hash calculation on the index key to locate the location of the data storage
2. In many cases, Hash index is better than B tree The index is more efficient
3. It can only satisfy "=" and "IN" and does not support range query
4. Hash conflict problem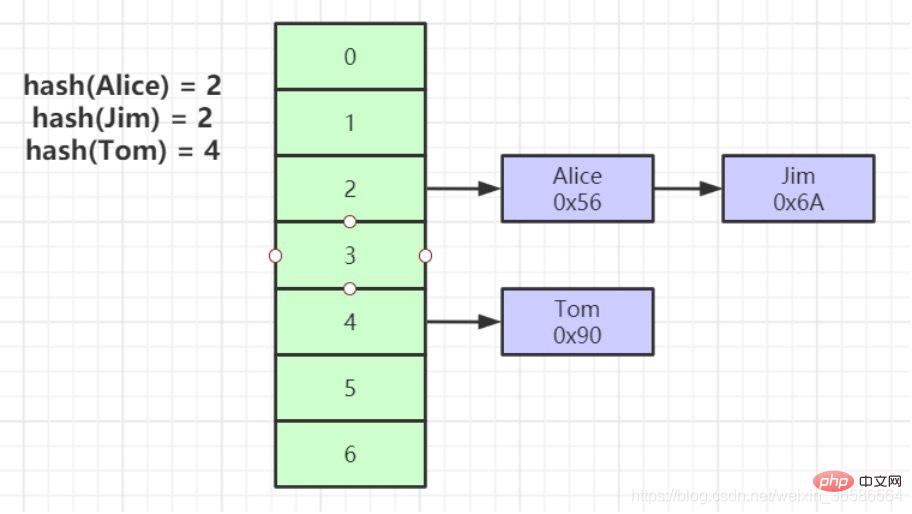
(4) B-Tree
1. Leaf nodes have the same depth, and the pointers of leaf nodes are empty;
2. All index elements are not repeated;
3. The data indexes in the nodes are arranged in ascending order from left to right; 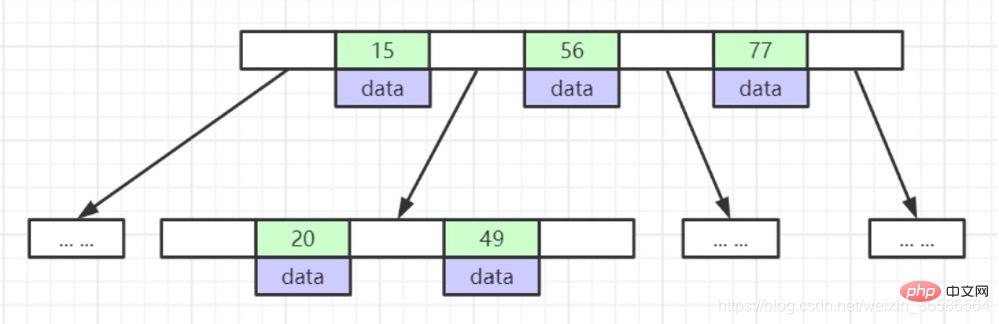
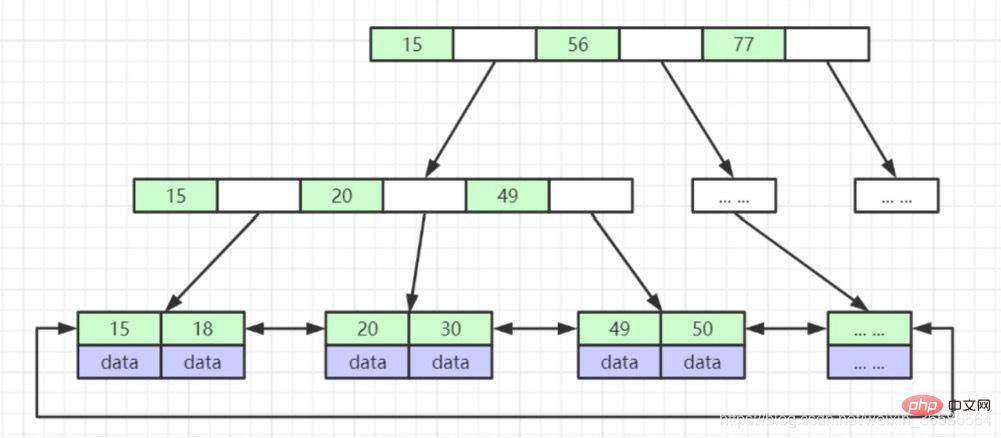
(5) B Tree (B-Tree variant)
1. Non-leaf nodes do not store data, only indexes (redundant), and more indexes can be placed
2. Leaf nodes contain all index fields
3. Leaf nodes are connected with pointers to improve the performance of interval access
3. How many rows of data can a B-tree in InnoDB store?
The simple answer to this question is: about 20 million
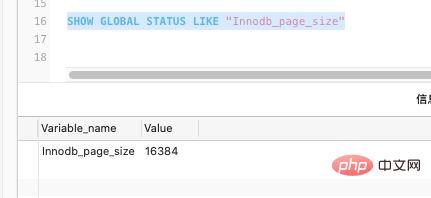
The default size of our InnoDB page in MySQL is 16k, of course it can also be set through parameters:
SHOW GLOBAL STATUS LIKE "Innodb_page_size"
The data in the data table is stored in pages, so how many rows of data can be stored in one page? Assuming the size of a row of data is 1k, then a page can store 16 rows of such data.
If the database is only stored in this way, then how to find the data becomes a problem
Because we don’t know which page the data we want to find exists, and it is impossible to traverse all the pages. too slow.
So people thought of a way to organize this data in the form of B-tree. As shown in the figure: 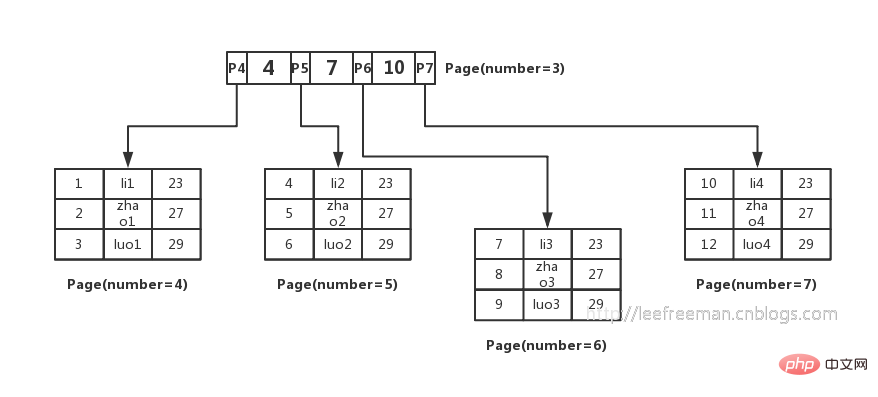
How the primary key index B-tree in InnoDB organizes data and queries data, let’s summarize:
1. The smallest storage unit of the InnoDB storage engine is the page , pages can be used to store data or key-value pointers. In the B-tree, leaf nodes store data, and non-leaf nodes store key-value pointers.
2. The index-organized table determines which page the data is in through the binary search method of non-leaf nodes and pointers, and then finds the required data in the data page;
Then back to us The starting question is, how many rows of data can a B-tree usually store?
Here we first assume that the height of the B-tree is 2, that is, there is a root node and several leaf nodes. Then the total number of records stored in this B-tree is: the number of root node pointers * the number of record rows of a single leaf node .
We have explained above that the number of records in a single leaf node (page) = 16K/1K=16. (Here it is assumed that the data size of one row of records is 1K. In fact, the record size of many Internet business data is usually about 1K).
So now we need to calculate how many pointers can be stored in non-leaf nodes?
In fact, this is easy to calculate. We assume that the primary key ID is of bigint type and the length is 8 bytes, and the pointer size is set to 6 bytes in the InnoDB source code, so a total of 14 bytes
How many such units we can store in a page actually represents how many pointers there are, that is, 16384/14=1170.
Then it can be calculated that a B-tree with a height of 2 can store 1170*16=18720 such data records.
Based on the same principle, we can calculate that a B-tree with a height of 3 can store: 1170* 1170 *16=21902400 such records.
So in InnoDB, the B-tree height is generally 1-3 layers, which can satisfy tens of millions of data storage.
When searching for data, one page search represents one IO, so querying through the primary key index usually only requires 1-3 IO operations to find the data.
4. Why does MySQL’s index use B-tree instead of other tree structures? Such as B-tree?
B tree
The leaf nodes have the same depth, and the pointers of the leaf nodes are empty
All index elements are not repeated
The data index in the node is from left to right Incremental arrangement
B tree index
Non-leaf nodes do not store data, only indexes (redundant), more indexes can be placed
Leaf nodes contain all index fields
Leaf nodes are connected with pointers to improve the performance of interval access
Why the data node is moved to the leaf node, one node can store more indexes
16^n=20 million, n It is the height of the tree. It stores the same data. The height of B-tree is much smaller than B-tree
Because B-tree will save data regardless of leaf nodes or non-leaf nodes, which results in fewer pointers that can be saved in non-leaf nodes. (Some information is also called fan-out)
To save a large amount of data when there are few pointers, you can only increase the height of the tree, resulting in more IO operations and lower query performance;
5 , Storage engine index implementation
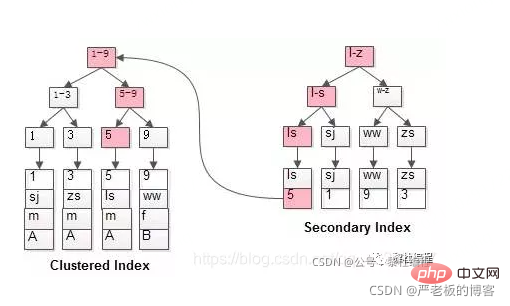
The meaning of clustered index: the leaf nodes store the index and data, also called clustered index.
Non-clustered index is also called sparse index. The primary key index is a clustered index!
(1) MyISAM index files and data files are separated (non-aggregated)
MyISAM index files and data files are separated (non-aggregated), and the storage engine acts on the table;
The index file stores the index, and the data file stores the data. The index and the data are not stored together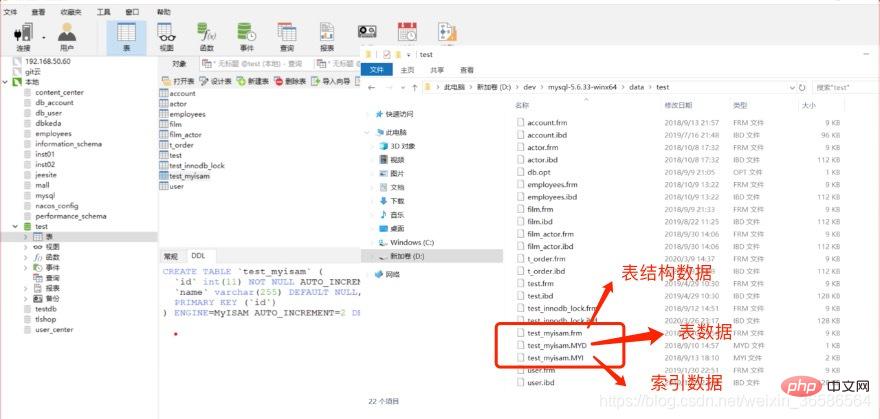
Query: First query the index on the B-tree, and then query the data file using the queried location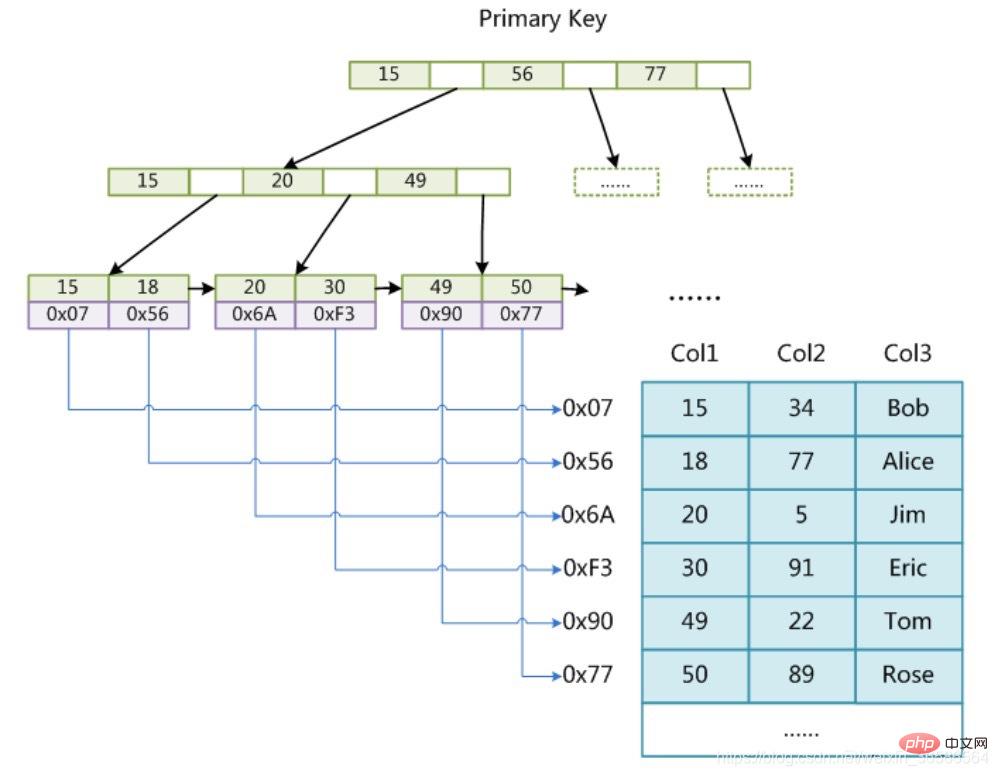
(1) InnoDB index implementation
Table data index data is stored in the .ibd file 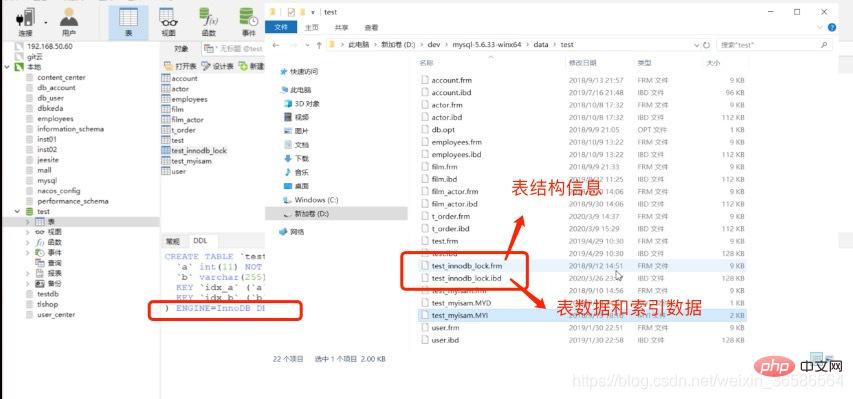
1. The table data file itself is an index organized by B Tree Structure file
2. Clustered index - leaf nodes contain complete data records
(1) Primary key index: 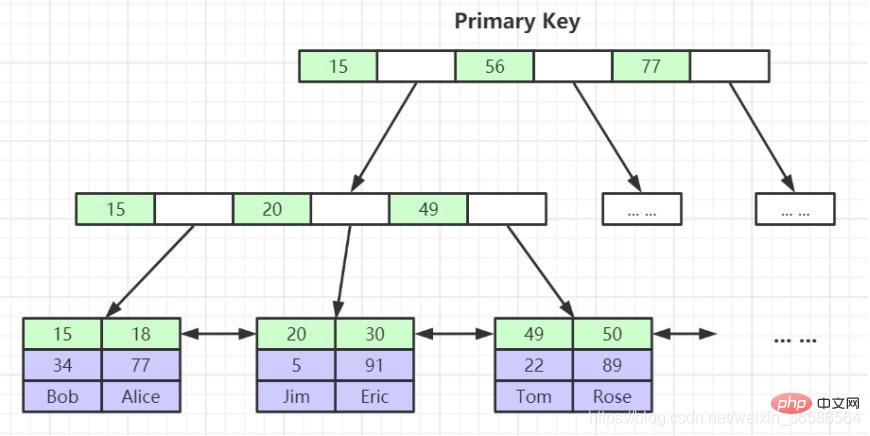
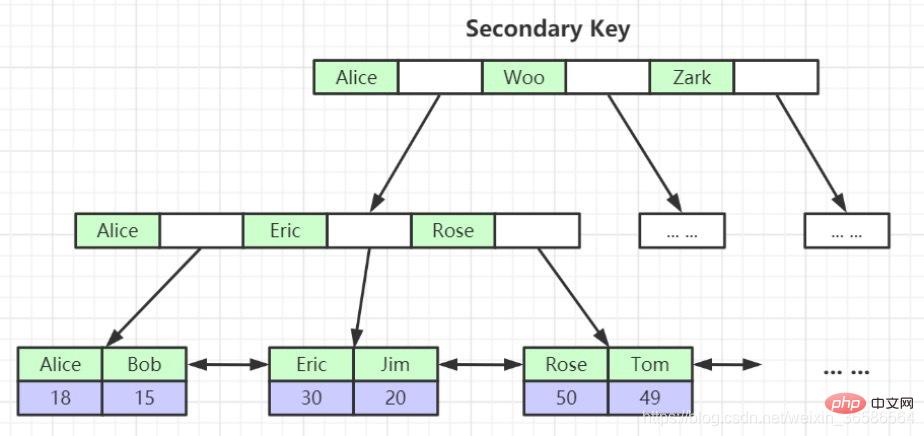
(2) Auxiliary index (secondary index)
The leaf nodes of the primary key index store complete data rows, while the leaf nodes of the non-primary key index store the primary key index value. When querying data through the non-primary key index, the primary key index will be found first, and then the primary key index will be searched. To find the corresponding data, this process is called table return (will be mentioned again below).
There are several differences between the secondary index and the clustered index:
- Sort by the value of the specified index column
- The leaf node storage is not complete User record, but just index column primary key.
- The directory entry record is not the primary key page number, but becomes the index column page number.
- When searching for data in the secondary index, you need to search for the complete user record in the clustered index based on the primary key value. This process is called Returning to the table
(3) Joint index:
The B-tree established with the size of multiple columns as the sorting rule is called a joint index, which is essentially a secondary index. 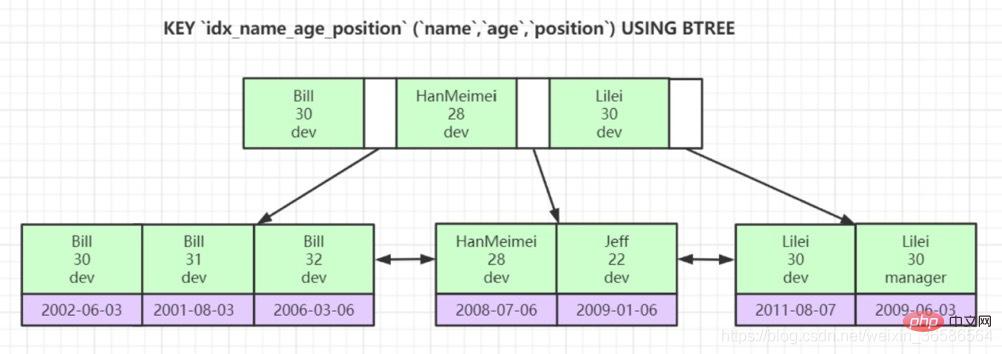
3. Why is it recommended that InnoDB tables must have a primary key, and why is it recommended to use an integer auto-incrementing primary key?
(1) The primary key is used by InnoDB to build the B-tree. If there is no primary key, the unique column will be used as the index. If there is still no primary key, a hidden column will be created as the index column.
(2) What happens if you don’t use an integer auto-incrementing primary key and use UUID as the primary key?
UUID is a string type. Query operations will have comparison operations. Integer comparison operations are faster. Integer primary keys save space than UUIDs. UUIDs are not auto-incrementing.
(3) HASH index: Hash operation is performed on the value. The final value and storage location are mapped one by one
Why not use Hash?
Hash does not support range queries well. The data in a certain column is unordered, and the B-tree can make the data orderly when constructing.
4. Why do leaf nodes of non-primary key index structures store primary key values? (Consistency and saving storage space)
6. B-tree index summary
1. Each index corresponds to a B-tree. User records are stored in leaf nodes of the B-tree, and all directory records are stored in non-leaf nodes.
2. The InnoDB storage engine will automatically create a clustered index for the primary key (if it does not exist, it will automatically add it for us). The leaf nodes of the clustered index contain complete user records.
3. A secondary index can be established for the specified column. The user records contained in the leaf nodes of the secondary index are composed of the primary keys of the index columns. Therefore, if you want to find complete user records through the secondary index, is required Through the table return operation, that is, after finding the primary key value through the secondary index, the complete user record is found in the clustered index.
4. The nodes at each level in the B-tree are sorted according to the index column value from small to large to form a doubly linked list, and the records in each page (whether it is a user record or a directory entry Records) are formed into a singly linked list in ascending order of the index column values. If it is a joint index, the pages and records are first sorted by the column in front of the joint index. If the column values are the same, they are sorted by the column after the joint index.
Searching for records through the index starts from the root node of the B-tree and searches downward layer by layer. Since each page has a page directory based on the value of the index column, searches in these pages are very fast.
7. Summary of several situations in which Mysql index will fail
View blog: Summary of several situations in which Mysql index will fail
https://blog. csdn.net/weixin_36586564/article/details/79641748
[Related recommendations: mysql video tutorial]
The above is the detailed content of In-depth analysis of indexes in mysql (detailed explanation of principles). For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- How to query the character set encoding of a table in mysql
- Learn more about locks in Mysql and talk about usage scenarios!
- Completely master the solution to MySQL master-slave delay
- How is a SQL statement executed in MySQL Learning? Let's talk about the execution process
- Detailed explanation of the basics of MySQL constraints and multi-table queries