



This article brings you some problems you may encounter about indexes in MySQL. The index can be said to be a big heart in the database. If a database lacks an index, then the meaning of the existence of the database itself is It's not big, I hope it helps everyone.

The index can be said to be a big heart in the database. If a database lacks an index, then the existence of the database itself will be of little significance, unlike ordinary files. No different. Therefore, a good index is particularly important for the database system. Today, let’s talk about MySQL index. From the perspective of details and actual business, we will look at the benefits of B-tree index in MySQL, as well as the knowledge points we need to pay attention to when using indexes.
Reasonable use of indexes
At work, the most direct way for us to judge whether a field in the data table needs to be indexed is: will this field often appear in our whereIn the condition. From a macro perspective, there is no problem with thinking like this, but from a long-term perspective, sometimes more detailed thinking may be needed. For example, do we not only need to create an index on this field? Is a joint index on multiple fields better? Taking a user table as an example, the fields in the user table may include user’s name, user’s ID number, user’s home address, etc. .
「1. Disadvantages of ordinary index」
Now there is a need to find the user’s name based on the user’s ID number , at this time, the first way to think of is to create an index on id_card. Strictly speaking, it is a unique index, because the ID number must be unique, then when we execute the following query:
SELECT name FROM user WHERE id_card=xxx
The process should be like this:
- First search on the id_card index tree and find the primary key id corresponding to id_card
- Go to the primary key index through the id Search and find the corresponding name
From the effect point of view, the result is no problem, but from the efficiency point of view, it seems that this query is a bit expensive, because it retrieves two B-trees, assuming one The height of the tree is 3, then the height of the two trees is 6. Because the root node is in the memory (two root nodes here), the final number of IOs to be performed on the disk is 4 times, based on one disk random IO If the average time consumption is 10ms, then it will ultimately take 40ms. This number is average, not fast.
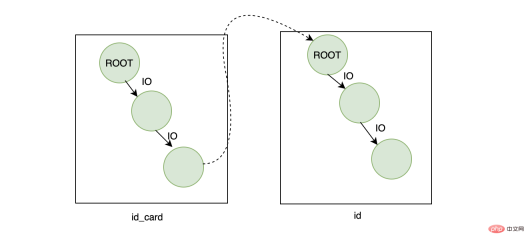
「2. Traps of primary key index」
Since the problem is table return, it results in retrieval in both trees , then the core question is to see if it can be retrieved on only one tree. From a business perspective, you may have found an entry point here. ID card number is unique, so can our primary key not use the default auto-increment id? We set the primary key to our ID card number, so that the entire table only needs one index, and all the required data, including our name, can be found through the ID number. It seems reasonable to think about it simply. As long as every time you insert data, specify that the ID is the ID number. , but if I think about it carefully, there seems to be a problem.
Let’s talk about the characteristics of the B-tree here. The data of the B-tree is stored on the leaf nodes, and the data is managed in pages. One page is 16K. What does this mean? Even if we have one row of data now, it will occupy a 16K data page. Only when our data page is full will it be written to a new data page. The new data page and the old data page are physically separated is not necessarily continuous , and one thing is very important. Although the data page is physically discontinuous, the data is logically continuous .
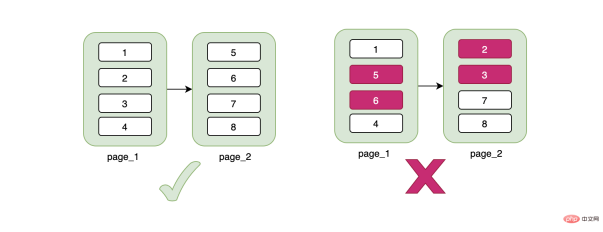
Maybe you are curious, what does this have to do with our ID number being the primary key ID? At this time, you should pay attention to the keyword Continuous. The ID number is not consecutive. What does this mean? When we insert a piece of discontinuous data, in order to maintain continuity, the data needs to be moved. For example, the original data on a page is 1->5, and now a 3 is inserted, then 5 needs to be moved after 3. , maybe you will say that this does not cost much, but if the new data 3 causes the page A to be full, then it depends on whether the page B behind it has space. If there is space, the starting data of page B should be This is the one that overflows from page A, and the corresponding data also needs to be moved. If page B does not have enough space at this time, then it is necessary to apply for a new page C, and then move part of the data to this new page C, and will cut off the relationship between page A and page B, and insert it between the two. A page C, from a code level, is a pointer that switches the linked list.
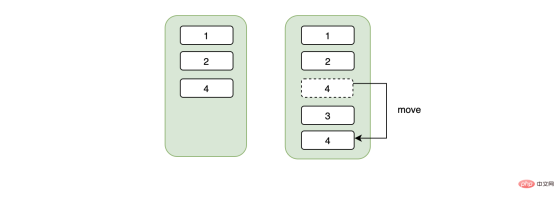
总结来说,不连续的身份证号当主键可能会造成页数据的移动、随机IO、频繁申请新页相关的开销。如果我们用的是自增的主键,那么对于id来说一定是顺序的,不会因为随机IO造成数据移动的问题,在插入方面开销一定是相对较小的。
其实不推荐用身份证号当主键的还有另外一个原因:身份证号作为数字来说太大了,得用bigint来存,正常来说一个学校的学生用int已经足够了,我们知道一页可以存放16K,当一个索引本身占用的空间越大时,会导致一页能存放的数据越少,所以在一定数据量的情况下,使用bigint要比int需要更多的页也就是更多的存储空间。
「3.联合索引的矛与盾」
由上面两条结论可以得出:
- 尽量不要去回表
- 身份证号不适合当主键索引
所以自然而然地想到了联合索引,创建一个【身份证号+姓名】的联合索引,注意联合索引的顺序,要符合最左原则。这样当我们同样执行以下sql时:
select name from user where id_card=xxx
不需要回表就可以得到我们需要的name字段,然而还是没有解决身份证号本身占用空间过大的问题,这是业务数据本身的问题,如果你要解决它的话,我们可以通过一些转换算法将原本大的数据转换成小的数据,比如crc32:
crc32.ChecksumIEEE([]byte("341124199408203232"))
可以将原本需要8个字节存储空间的身份证号用4个字节的crc码替代,因此我们的数据库需要再加个字段crc_id_card,联合索引也从【身份证号+姓名】变成了【crc32(身份证号)+姓名】,联合索引占的空间变小了。但是这种转换也是有代价的:
每次额外的crc,导致需要更多cpu资源
额外的字段,虽然让索引的空间变小了,但是本身也要占用空间
crc会存在冲突的概率,这需要我们查询出来数据后,再根据id_card过滤一下,过滤的成本根据重复数据的数量而定,重复越多,过滤越慢。
关于联合索引存储优化,这里有个小细节,假设现在有两个字段A和B,分别占用8个字节和20个字节,我们在联合索引已经是[A,B]的情况下,还要支持B的单独查询,因此自然而然我们在B上也建立个索引,那么两个索引占用的空间为 8+20+20=48,现在无论我们通过A还是通过B查询都可以用到索引,如果在业务允许的条件下,我们是否可以建立[B,A]和A索引,这样的话,不仅满足单独通过A或者B查询数据用到索引,还可以占用更小的空间:20+8+8=36。
「4.前缀索引的短小精悍」
有时候我们需要索引的字段是字符串类型的,并且这个字符串很长,我们希望这个字段加上索引,但是我们又不希望这个索引占用太多的空间,这时可以考虑建立个前缀索引,以这个字段的前一部分字符建立个索引,这样既可以享受索引,又可以节省空间,这里需要注意的是在前缀重复度较高的情况下,前缀索引和普通索引的速度应该是有差距的。
alter table xx add index(name(7));#name前7个字符建立索引 select xx from xx where name="JamesBond"
「5.唯一索引的快与慢」
在说唯一索引之前,我们先了解下普通索引的特点,我们知道对于B+树而言,叶子节点的数据是有序的。

假设现在我们要查询2这条数据,那么在通过索引树找到2的时候,存储引擎并没有停止搜索,因为可能存在多个2,这表现为存储引擎会在叶子节点上接着向后查找,在找到第二个2之后,就停止了吗?答案是否,因为存储引擎并不知道后面还有没有更多的2,所以得接着向后查找,直至找到第一个不是2的数据,也就是3,找到3之后,停止检索,这就是普通索引的检索过程。
唯一索引就不一样了,因为唯一性,不可能存在重复的数据,所以在检索到我们的目标数据之后直接返回,不会像普通索引那样还要向后多查找一次,从这个角度来看,唯一索引是要比普通索引快的,但是当普通索引的数据都在一个页内的话,其实也并不会快多少。在数据的插入方面,唯一索引可能就稍逊色,因为唯一性,每次插入的时候,都需要将判断要插入的数据是否已经存在,而普通索引不需要这个逻辑,并且很重要的一点是唯一索引会用不到change buffer(见下文)。
「6.不要盲目加索引」
在工作中,你可能会遇到这样的情况:这个字段我需不需要加索引?。对于这个问题,我们常用的判断手段就是:查询会不会用到这个字段,如果这个字段经常在查询的条件中,我们可能会考虑加个索引。但是如果只根据这个条件判断,你可能会加了一个错误的索引。我们来看个例子:假设有张用户表,大概有100w的数据,用户表中有个性别字段表示男女,男女差不多各占一半,现在我们要统计所有男生的信息,然后我们给性别字段加了索引,并且我们这样写下了sql:
select * from user where sex="男"
如果不出意外的话,InnoDB是不会选择性别这个索引的。如果走性别索引,那么一定是需要回表的,在数据量很大的情况下,回表会造成什么样的后果?我贴一张和上面一样的图想必大家都知道了:

主要就是大量的IO,一条数据需要4次,那么50w的数据呢?结果可想而知。因此针对这种情况,MySQL的优化器大概率走全表扫描,直接扫描主键索引,因为这样性能可能会更高。
「7.索引失效那些事」
某些情况下,因为我们自己使用的不当,导致mysql用不到索引,这一般很容易发生在类型转换方面,也许你会说,mysql不是已经支持隐式转换了吗?比如现在有个整型的user_id索引字段,我们因为查询的时候没注意,写成了:
select xx from user where user_id="1234"
注意这里是字符的1234,当发生这种情况下,MySQL确实足够聪明,会把字符的1234转成数字的1234,然后愉快的使用了user_id索引。 但是如果我们有个字符型的user_id索引字段,还是因为我们查询的时候没注意,写成了:
select xx from user where user_id=1234
这时候就有问题了,会用不到索引,也许你会问,这时MySQL为什么不会转换了,把数字的1234转成字符型的1234不就行了? 这里需要解释下转换的规则了,当出现字符串和数字比较的时候,要记住:MySQL会把字符串转换成数字。也许你又会问:为什么把字符型user_id字段转换成数字就用不到索引了? 这又要说到B+树索引的结构了,我们知道B+树的索引是按照索引的值来分叉和排序的,当我们把索引字段发生类型转换时会发生值的变化,比如原来是A值,如果执行整型转换可能会对应一个B值(int(A)=B),这时这颗索引树就不能用了,因为索引树是按照A来构造的,不是B,所以会用不到索引。
索引优化
「1.change buffer」
我们知道在更新一条数据的时候,要先判断这条数据的页是否在内存里,如果在的话,直接更新对应的内存页,如果不在的话,只能去磁盘把对应的数据页读到内存中来,然后再更新,这会有什么问题呢?
- 去磁盘的读这个动作稍显的有点慢
- 如果同时更新很多数据,那么即有可能发生很多离散的IO
为了解决这种情况下的速度问题,change buffer出现了,首先不要被buffer这个单词误导,change buffer除了会在公共的buffer pool里之外,也是会持久化到磁盘的。当有了change buffer之后,我们更新的过程中,如果发现对应的数据页不在内存里的话,也不去磁盘读取相应的数据页了,而是把要更新的数据放入到change buffer中,那change buffer的数据何时被同步到磁盘上去?如果此时发生读动作怎么办?首先后台有个线程会定期把change buffer的数据同步到磁盘上去的,如果线程还没来得及同步,但是又发生了读操作,那么也会触发把change buffer的数据merge到磁盘的事件。

需要注意的是并不是所有的索引都能用到changer buffer,像主键索引和唯一索引就用不到,因为唯一性,所以它们在更新的时候要判断数据存不存在,如果数据页不在内存中,就必须去磁盘上把对应的数据页读到内存里,而普通索引就没关系了,不需要校验唯一性。change buffer越大,理论收益就越大,这是因为首先离散的读IO变少了,其次当一个数据页上发生多次变更,只需merge一次到磁盘上。当然并不是所有的场景都适合changer buffer,如果你的业务是更新之后,需要立马去读,changer buffer会适得其反,因为需要不停地触发merge动作,导致随机IO的次数不会变少,反而增加了维护changer buffer的开销。
「2.索引下推」
前面我们说了联合索引,联合索引要满足最左原则,即在联合索引是[A,B]的情况下,我们可以通过以下的sql用到索引:
select * from table where A="xx" select * from table where A="xx" AND B="xx"
其实联合索引也可以使用最左前缀的原则,即:
select * from table where A like "赵%" AND B="上海市"
但是这里需要注意的是,因为使用了A的一部分,在MySQL5.6之前,上面的sql在检索出所有A是“赵”开头的数据之后,就立马回表(使用的select *),然后再对比B是不是“上海市”这个判断,这里是不是有点懵?为什么B这个判断不直接在联合索引上判断,这样的话回表的次数不就少了吗?造成这个问题的原因还是因为使用了最左前缀的问题,导致索引虽然能使用部分A,但是完全用不到B,看起来是有点“傻”,于是在MySQL5.6之后,就出现了索引下推这个优化(Index Condition Pushdown),有了这个功能以后,虽然使用的是最左前缀,但是也可以在联合索引上搜索出符合A%的同时也过滤非B的数据,大大减少了回表的次数。
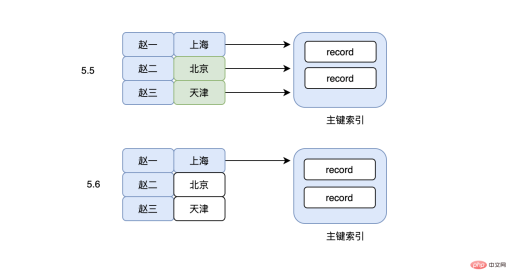
「3.刷新邻接页」
在说刷新邻接页之前,我们先说下脏页,我们知道在更新一条数据的时候,得先判断这条数据所在的页是否在内存中,如果不在的话,需要把这个数据页先读到内存中,然后再更新内存中的数据,这时会发现内存中的页有最新的数据,但是磁盘上的页却依然是老数据,那么此时这条数据所在的内存中的页就是脏页,需要刷到磁盘上来保持一致。所以问题来了,何时刷?每次刷多少脏页才合适?如果每次变更就刷,那么性能会很差,如果很久才刷,脏页就会堆积很多,造成内存池中可用的页变少,进而影响正常的功能。所以刷的速度不能太快但要及时,MySQL有个清理线程会定期执行,保证了不会太快,当脏页太多或者redo log已经快满了,也会立刻触发刷盘,保证了及时。

在脏页刷盘的过程中,InnoDB这里有个优化:如果要刷的脏页的邻居页也脏了,那么就顺带一起刷,这样的好处就是可以减少随机IO,在机械磁盘的情况下,优化应该挺大,但是这里可能会有坑,如果当前脏页的邻居脏页在被一起刷入后,邻居页立马因为数据的变更又变脏了,那此时是不是有种多此一举的感觉,并且反而浪费了时间和开销。更糟糕的是如果邻居页的邻居也是脏页...,那么这个连锁反应可能会出现短暂的性能问题。
「4.MRR」
在实际业务中,我们可能会被告知尽量使用覆盖索引,不要回表,因为回表需要更多IO,耗时更长,但是有时候我们又不得不回表,回表不仅仅会造成过多的IO,更严重的是过多的离散IO。
select * from user where grade between 60 and 70
现在要查询成绩在60-70之间的用户信息,于是我们的sql写成上面的那样,当然我们的grade字段是有索引的,按照常理来说,会先在grade索引上找到grade=60这条数据,然后再根据grade=60这条数据对应的id去主键索引上找,最后再次回到grade索引上,不停的重复同样的动作..., 假设现在grade=60对应的id=1,数据是在page_no_1上,grade=61对应的id=10,数据是在page_no_2上,grade=62对应的id=2,数据是在page_no_1上,所以真实的情况就是先在page_no_1上找数据,然后切到page_no_2,最后又切回page_no_1上,但其实id=1和id=2完全可以合并,读一次page_no_1即可,不仅节省了IO,同时避免了随机IO,这就是MRR。当使用MRR之后,辅助索引不会立即去回表,而是将得到的主键id,放在一个buffer中,然后再对其排序,排序后再去顺序读主键索引,大大减少了离散的IO。
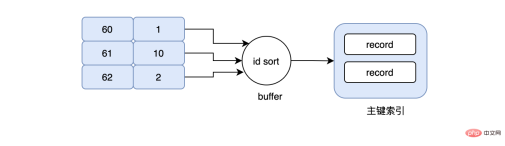
推荐学习:mysql视频教程
The above is the detailed content of You must understand the pitfalls of MySQL indexes. For more information, please follow other related articles on the PHP Chinese website!

 MySQL's Role: Databases in Web ApplicationsApr 17, 2025 am 12:23 AM
MySQL's Role: Databases in Web ApplicationsApr 17, 2025 am 12:23 AMThe main role of MySQL in web applications is to store and manage data. 1.MySQL efficiently processes user information, product catalogs, transaction records and other data. 2. Through SQL query, developers can extract information from the database to generate dynamic content. 3.MySQL works based on the client-server model to ensure acceptable query speed.
 MySQL: Building Your First DatabaseApr 17, 2025 am 12:22 AM
MySQL: Building Your First DatabaseApr 17, 2025 am 12:22 AMThe steps to build a MySQL database include: 1. Create a database and table, 2. Insert data, and 3. Conduct queries. First, use the CREATEDATABASE and CREATETABLE statements to create the database and table, then use the INSERTINTO statement to insert the data, and finally use the SELECT statement to query the data.
 MySQL: A Beginner-Friendly Approach to Data StorageApr 17, 2025 am 12:21 AM
MySQL: A Beginner-Friendly Approach to Data StorageApr 17, 2025 am 12:21 AMMySQL is suitable for beginners because it is easy to use and powerful. 1.MySQL is a relational database, and uses SQL for CRUD operations. 2. It is simple to install and requires the root user password to be configured. 3. Use INSERT, UPDATE, DELETE, and SELECT to perform data operations. 4. ORDERBY, WHERE and JOIN can be used for complex queries. 5. Debugging requires checking the syntax and use EXPLAIN to analyze the query. 6. Optimization suggestions include using indexes, choosing the right data type and good programming habits.
 Is MySQL Beginner-Friendly? Assessing the Learning CurveApr 17, 2025 am 12:19 AM
Is MySQL Beginner-Friendly? Assessing the Learning CurveApr 17, 2025 am 12:19 AMMySQL is suitable for beginners because: 1) easy to install and configure, 2) rich learning resources, 3) intuitive SQL syntax, 4) powerful tool support. Nevertheless, beginners need to overcome challenges such as database design, query optimization, security management, and data backup.
 Is SQL a Programming Language? Clarifying the TerminologyApr 17, 2025 am 12:17 AM
Is SQL a Programming Language? Clarifying the TerminologyApr 17, 2025 am 12:17 AMYes,SQLisaprogramminglanguagespecializedfordatamanagement.1)It'sdeclarative,focusingonwhattoachieveratherthanhow.2)SQLisessentialforquerying,inserting,updating,anddeletingdatainrelationaldatabases.3)Whileuser-friendly,itrequiresoptimizationtoavoidper
 Explain the ACID properties (Atomicity, Consistency, Isolation, Durability).Apr 16, 2025 am 12:20 AM
Explain the ACID properties (Atomicity, Consistency, Isolation, Durability).Apr 16, 2025 am 12:20 AMACID attributes include atomicity, consistency, isolation and durability, and are the cornerstone of database design. 1. Atomicity ensures that the transaction is either completely successful or completely failed. 2. Consistency ensures that the database remains consistent before and after a transaction. 3. Isolation ensures that transactions do not interfere with each other. 4. Persistence ensures that data is permanently saved after transaction submission.
 MySQL: Database Management System vs. Programming LanguageApr 16, 2025 am 12:19 AM
MySQL: Database Management System vs. Programming LanguageApr 16, 2025 am 12:19 AMMySQL is not only a database management system (DBMS) but also closely related to programming languages. 1) As a DBMS, MySQL is used to store, organize and retrieve data, and optimizing indexes can improve query performance. 2) Combining SQL with programming languages, embedded in Python, using ORM tools such as SQLAlchemy can simplify operations. 3) Performance optimization includes indexing, querying, caching, library and table division and transaction management.
 MySQL: Managing Data with SQL CommandsApr 16, 2025 am 12:19 AM
MySQL: Managing Data with SQL CommandsApr 16, 2025 am 12:19 AMMySQL uses SQL commands to manage data. 1. Basic commands include SELECT, INSERT, UPDATE and DELETE. 2. Advanced usage involves JOIN, subquery and aggregate functions. 3. Common errors include syntax, logic and performance issues. 4. Optimization tips include using indexes, avoiding SELECT* and using LIMIT.


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

Zend Studio 13.0.1
Powerful PHP integrated development environment

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

Dreamweaver CS6
Visual web development tools

