16 | represents The relative position of the next record |
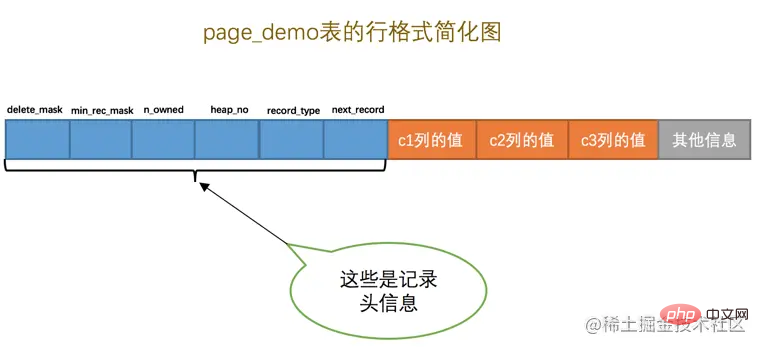
由于我们现在主要在唠叨记录头信息的作用,所以为了大家理解上的方便,我们只在page_demo表的行格式演示图中画出有关的头信息属性以及c1、c2、c3列的信息(其他信息没画不代表它们不存在啊,只是为了理解上的方便在图中省略了~),简化后的行格式示意图就是这样:

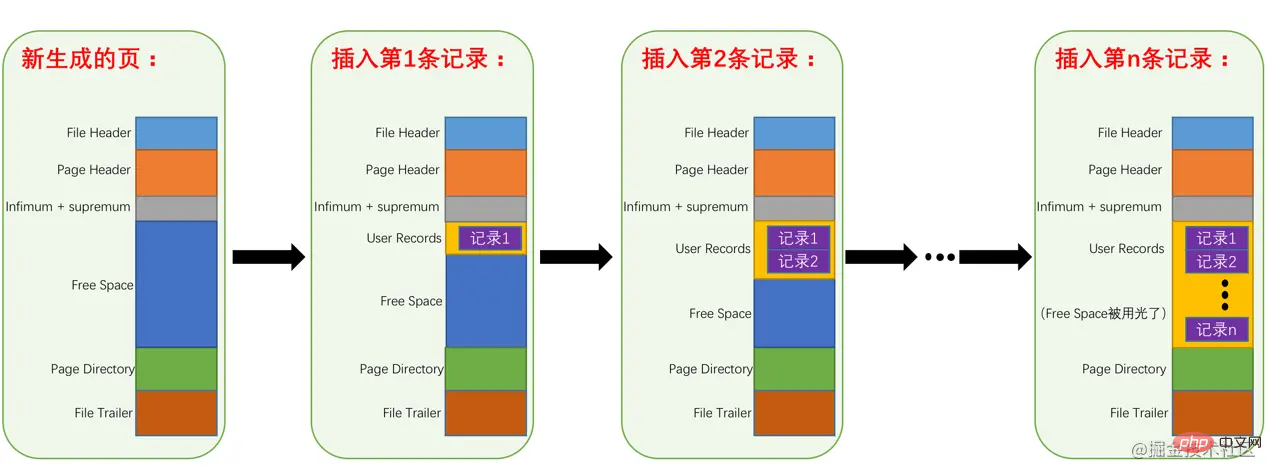
下边我们试着向page_demo表中插入几条记录:
mysql> INSERT INTO page_demo VALUES(1, 100, 'aaaa'), (2, 200, 'bbbb'), (3, 300, 'cccc'), (4, 400, 'dddd');
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
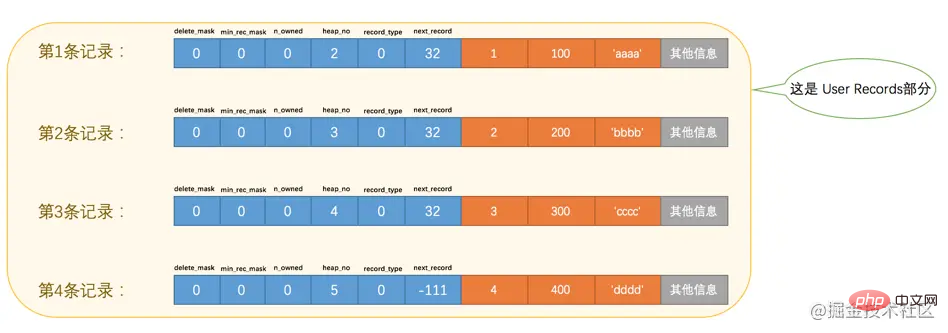
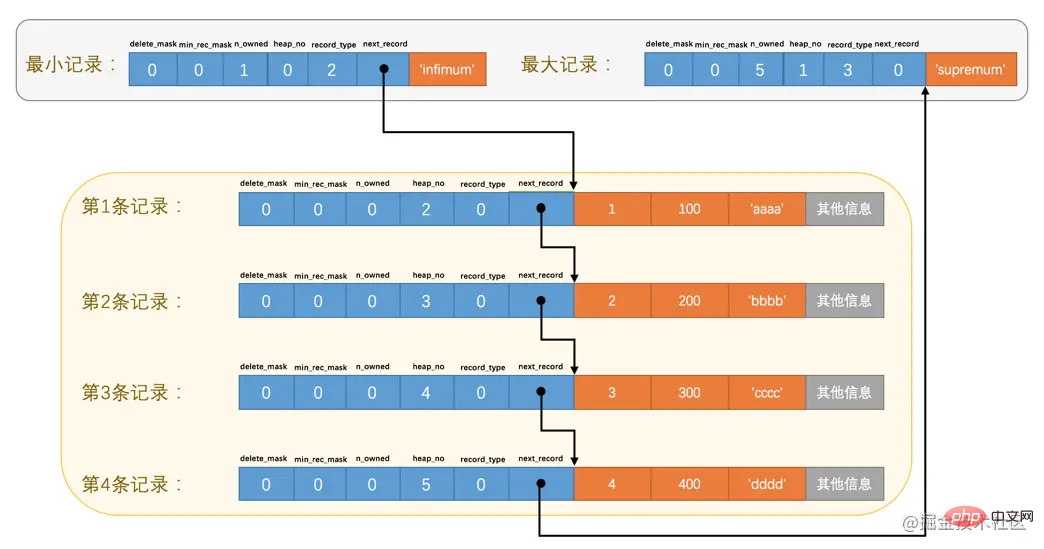
为了方便大家分析这些记录在页的User Records部分中是怎么表示的,我把记录中头信息和实际的列数据都用十进制表示出来了(其实是一堆二进制位),所以这些记录的示意图就是:
看这个图的时候需要注意一下,各条记录在User Records中存储的时候并没有空隙,这里只是为了大家观看方便才把每条记录单独画在一行中。我们对照着这个图来看看记录头信息中的各个属性是啥意思:
-
delete_mask
这个属性标记着当前记录是否被删除,占用1个二进制位,值为0的时候代表记录并没有被删除,为1的时候代表记录被删除掉了。
啥?被删除的记录还在页中么?是的,摆在台面上的和背地里做的可能大相径庭,你以为它删除了,可它还在真实的磁盘上[摊手](忽然想起冠希~)。这些被删除的记录之所以不立即从磁盘上移除,是因为移除它们之后把其他的记录在磁盘上重新排列需要性能消耗,所以只是打一个删除标记而已,所有被删除掉的记录都会组成一个所谓的垃圾链表,在这个链表中的记录占用的空间称之为所谓的可重用空间,之后如果有新记录插入到表中的话,可能把这些被删除的记录占用的存储空间覆盖掉。
-
min_rec_mask
B+树的每层非叶子节点中的最小记录都会添加该标记,什么是个B+树?什么是个非叶子节点?好吧,等会再聊这个问题。反正我们自己插入的四条记录的min_rec_mask值都是0,意味着它们都不是B+树的非叶子节点中的最小记录。
-
n_owned
这个暂时保密,稍后它是主角~
-
heap_no
这个属性表示当前记录在本页中的位置,从图中可以看出来,我们插入的4条记录在本页中的位置分别是:2、3、4、5。是不是少了点啥?是的,怎么不见heap_no值为0和1的记录呢?
这其实是设计InnoDB的大叔们玩的一个小把戏,他们自动给每个页里边儿加了两个记录,由于这两个记录并不是我们自己插入的,所以有时候也称为伪记录或者虚拟记录。这两个伪记录一个代表最小记录,一个代表最大记录,等一下哈~,记录可以比大小么?
是的,记录也可以比大小,对于一条完整的记录来说,比较记录的大小就是比较主键的大小。比方说我们插入的4行记录的主键值分别是:1、2、3、4,这也就意味着这4条记录的大小从小到大依次递增。
-
但是不管我们向页中插入了多少自己的记录,设计InnoDB的大叔们都规定他们定义的两条伪记录分别为最小记录与最大记录。这两条记录的构造十分简单,都是由5字节大小的记录头信息和8字节大小的一个固定的部分组成的,如图所示
由于这两条记录不是我们自己定义的记录,所以它们并不存放在页的User Records部分,他们被单独放在一个称为Infimum + Supremum的部分,如图所示:
从图中我们可以看出来,最小记录和最大记录的heap_no值分别是0和1,也就是说它们的位置最靠前。
-
record_type
这个属性表示当前记录的类型,一共有4种类型的记录,0表示普通记录,1表示B+树非叶节点记录,2表示最小记录,3表示最大记录。从图中我们也可以看出来,我们自己插入的记录就是普通记录,它们的record_type值都是0,而最小记录和最大记录的record_type值分别为2和3。
至于record_type为1的情况,我们之后在说索引的时候会重点强调的。
-
next_record
这玩意儿非常重要,它表示从当前记录的真实数据到下一条记录的真实数据的地址偏移量。比方说第一条记录的next_record值为32,意味着从第一条记录的真实数据的地址处向后找32个字节便是下一条记录的真实数据。如果你熟悉数据结构的话,就立即明白了,这其实是个链表,可以通过一条记录找到它的下一条记录。但是需要注意注意再注意的一点是,下一条记录指得并不是按照我们插入顺序的下一条记录,而是按照主键值由小到大的顺序的下一条记录。而且规定 Infimum记录(也就是最小记录) 的下一条记录就是本页中主键值最小的用户记录,而本页中主键值最大的用户记录的下一条记录就是 Supremum记录(也就是最大记录) ,为了更形象的表示一下这个next_record起到的作用,我们用箭头来替代一下next_record中的地址偏移量:
从图中可以看出来,我们的记录按照主键从小到大的顺序形成了一个单链表。最大记录的next_record的值为0,这也就是说最大记录是没有下一条记录了,它是这个单链表中的最后一个节点。如果从中删除掉一条记录,这个链表也是会跟着变化的,比如我们把第2条记录删掉:
mysql> DELETE FROM page_demo WHERE c1 = 2;
Query OK, 1 row affected (0.02 sec)
删掉第2条记录后的示意图就是:
从图中可以看出来,删除第2条记录前后主要发生了这些变化:
- 第2条记录并没有从存储空间中移除,而是把该条记录的
delete_mask值设置为1。
- 第2条记录的
next_record值变为了0,意味着该记录没有下一条记录了。
- 第1条记录的
next_record指向了第3条记录。
- 还有一点你可能忽略了,就是
最大记录的n_owned值从5变成了4,关于这一点的变化我们稍后会详细说明的。
所以,不论我们怎么对页中的记录做增删改操作,InnoDB始终会维护一条记录的单链表,链表中的各个节点是按照主键值由小到大的顺序连接起来的。
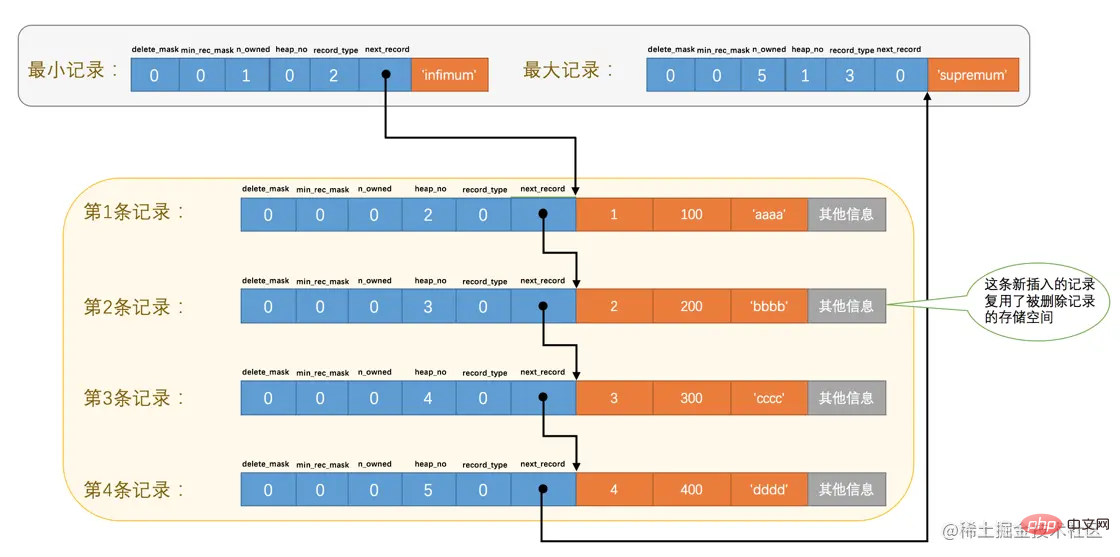
再来看一个有意思的事情,因为主键值为2的记录被我们删掉了,但是存储空间却没有回收,如果我们再次把这条记录插入到表中,会发生什么事呢?
mysql> INSERT INTO page_demo VALUES(2, 200, 'bbbb');
Query OK, 1 row affected (0.00 sec)
我们看一下记录的存储情况:
从图中可以看到,InnoDB并没有因为新记录的插入而为它申请新的存储空间,而是直接复用了原来被删除记录的存储空间。
Page Directory(页目录)
现在我们了解了记录在页中按照主键值由小到大顺序串联成一个单链表,那如果我们想根据主键值查找页中的某条记录该咋办呢?比如说这样的查询语句:
SELECT * FROM page_demo WHERE c1 = 3;
最笨的办法:从Infimum记录(最小记录)开始,沿着链表一直往后找,总有一天会找到(或者找不到[摊手]),在找的时候还能投机取巧,因为链表中各个记录的值是按照从小到大顺序排列的,所以当链表的某个节点代表的记录的主键值大于你想要查找的主键值时,你就可以停止查找了,因为该节点后边的节点的主键值依次递增。
This method is no problem when the number of records stored in the page is relatively small. For example, our table now only has 4 records that we have inserted, so we can only find at most. All records can be traversed 4 times, but if a page stores a lot of records, such a search will still have a loss in performance, so we say that this kind of traversal search is a Stupid way. But who are the uncles who designed InnoDB? Can they use such a stupid method? Of course, they have to design a better search method. They found inspiration from the table of contents of the book.
When we usually want to find something in a book, we usually look at the table of contents first, find the page number of the book corresponding to the content we want to find, and then go to the corresponding page number to view the content. The uncles who designed InnoDB also made a similar directory for our records. Their production process is as follows:
Convert all normal records (including The largest and smallest records (excluding records marked as deleted) are divided into several groups.
The n_owned attribute in the header information of the last record of each group (that is, the largest record in the group) indicates how many records the record has. , that is, how many records there are in this group.
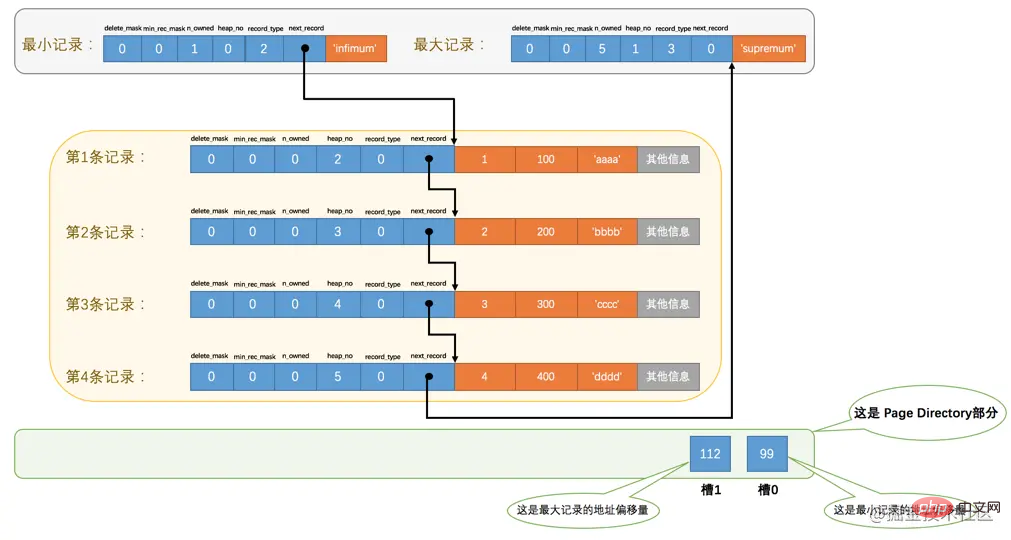
Extract the address offset of the last record of each group separately and store it in order near the end of page . This place is so-called Page Directory, which is Page Directory (At this time, you should go back to the top and look at the pictures of each part of the page). These address offsets in the page directory are called slot (English name: Slot), so this page directory is composed of slot.
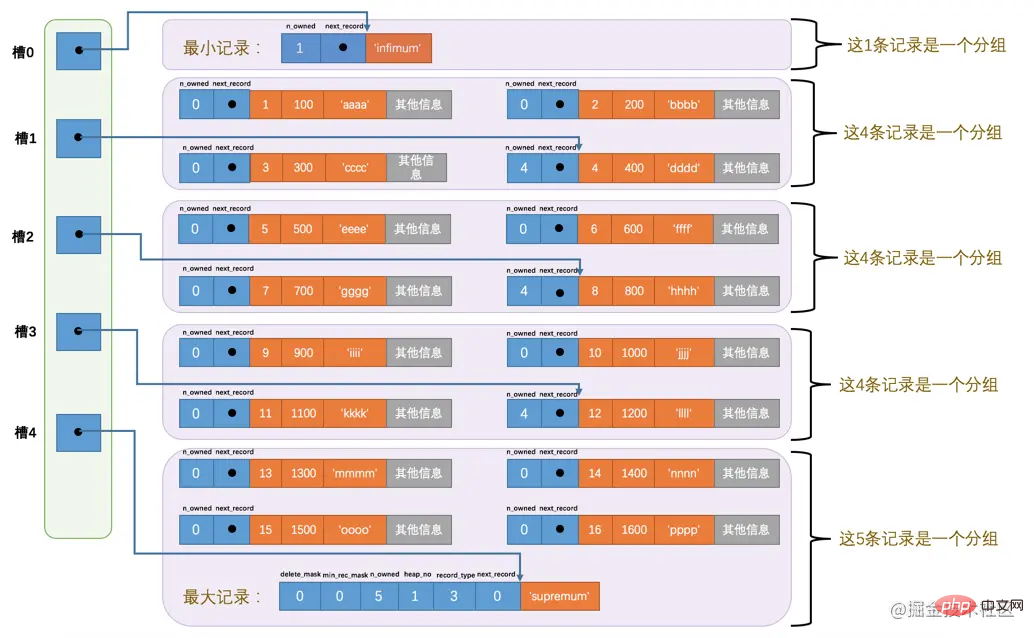
For example, there are currently 6 normal records in the page_demo table. InnoDB will divide them into two groups. In the first group There is only one minimum record, and the second group contains the remaining 5 records. Look at the diagram below:
We need to pay attention to the following points from this picture:
Now there are two slots in the page directory section, which means that our records are divided into two groups, The value in slot 1 It is 112, which represents the address offset of the largest record (that is, counting from byte 0 of the page and counting to 112 bytes); the value in slot 0 is 99, represents the address offset of the smallest record.
-
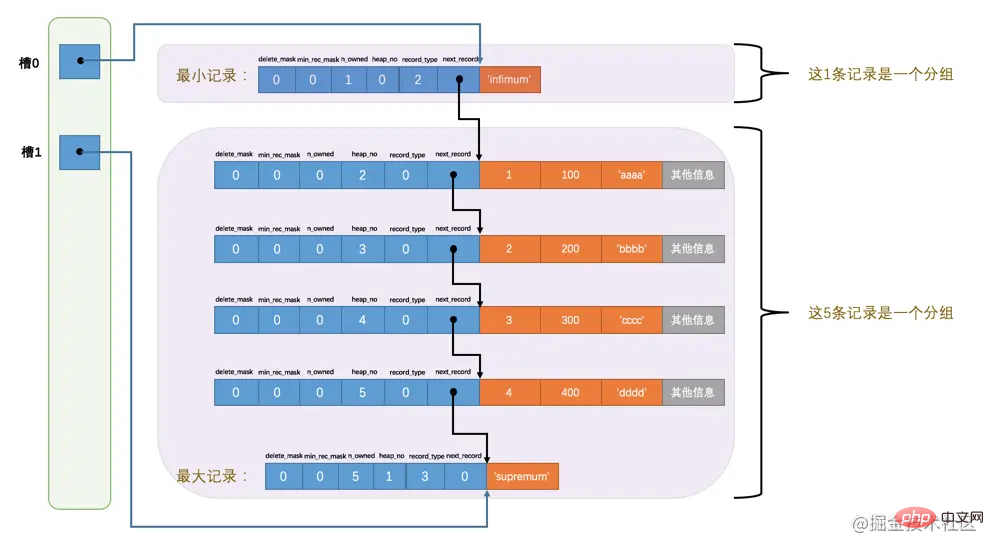
Note the n_owned attribute in the header information of the minimum and maximum records
- The
n_owned value of the minimum record is 1, which means that there are only 1 records in the group ending with the minimum record, which is the minimum record itself.
- The
n_owned value of the largest record is 5, which means that there are only 5 records in the group ending with the largest record, including The maximum record itself also has 4 records inserted by ourselves. Address offsets like
99 and 112 are very unintuitive. We use arrows to point to numbers instead of numbers, like this It’s easier for us to understand, so the modified schematic diagram is like this:
Oh, it looks weird. Such a messy picture is really intolerable for my obsessive-compulsive disorder. Then we will temporarily ignore the arrangement of each record on the storage device, and simply look at the relationship between these records and the page directory from a logical perspective:
It looks pleasing to the eye. There are too many! Why is the n_owned value of the smallest record 1, while the n_owned value of the largest record is 5? Is there anything fishy here?
Yes, the uncles who designed InnoDB have regulations on the number of records in each group: the group with the smallest record can only have 1 records, the number of records owned by the group where the largest record is located can only be between 1~8, and the number of records in the remaining groups The range can only be between 4~8. Therefore, grouping is carried out according to the following steps:
Initially, there are only two records in a data page, the minimum record and the maximum record, and they belong to two groups.
Every time a record is inserted, the slot whose primary key value is greater than the primary key value of this record and has the smallest difference will be found from the page directory, and then the slot will be The n_owned value of the record corresponding to this slot is increased by 1, indicating that another record has been added to this group until the number of records in this group is equal to 8.
在一个组中的记录数等于8个后再插入一条记录时,会将组中的记录拆分成两个组,一个组中4条记录,另一个5条记录。这个过程会在页目录中新增一个槽来记录这个新增分组中最大的那条记录的偏移量。
由于现在page_demo表中的记录太少,无法演示添加了页目录之后加快查找速度的过程,所以再往page_demo表中添加一些记录:
mysql> INSERT INTO page_demo VALUES(5, 500, 'eeee'), (6, 600, 'ffff'), (7, 700, 'gggg'), (8, 800, 'hhhh'), (9, 900, 'iiii'), (10, 1000, 'jjjj'), (11, 1100, 'kkkk'), (12, 1200, 'llll'), (13, 1300, 'mmmm'), (14, 1400, 'nnnn'), (15, 1500, 'oooo'), (16, 1600, 'pppp');
Query OK, 12 rows affected (0.00 sec)
Records: 12 Duplicates: 0 Warnings: 0
哈,我们一口气又往表中添加了12条记录,现在页里边就一共有18条记录了(包括最小和最大记录),这些记录被分成了5个组,如图所示:
因为把16条记录的全部信息都画在一张图里太占地方,让人眼花缭乱的,所以只保留了用户记录头信息中的n_owned和next_record属性,也省略了各个记录之间的箭头,我没画不等于没有啊!现在看怎么从这个页目录中查找记录。因为各个槽代表的记录的主键值都是从小到大排序的,所以我们可以使用所谓的二分法来进行快速查找。5个槽的编号分别是:0、1、2、3、4,所以初始情况下最低的槽就是low=0,最高的槽就是high=4。比方说我们想找主键值为6的记录,过程是这样的:
计算中间槽的位置:(0+4)/2=2,所以查看槽2对应记录的主键值为8,又因为8 > 6,所以设置high=2,low保持不变。
重新计算中间槽的位置:(0+2)/2=1,所以查看槽1对应的主键值为4,又因为4 ,所以设置<code>low=1,high保持不变。
因为high - low的值为1,所以确定主键值为6的记录在槽2对应的组中。此刻我们需要找到槽2中主键值最小的那条记录,然后沿着单向链表遍历槽2中的记录。但是我们前边又说过,每个槽对应的记录都是该组中主键值最大的记录,这里槽2对应的记录是主键值为8的记录,怎么定位一个组中最小的记录呢?别忘了各个槽都是挨着的,我们可以很轻易的拿到槽1对应的记录(主键值为4),该条记录的下一条记录就是槽2中主键值最小的记录,该记录的主键值为5。所以我们可以从这条主键值为5的记录出发,遍历槽2中的各条记录,直到找到主键值为6的那条记录即可。由于一个组中包含的记录条数只能是1~8条,所以遍历一个组中的记录的代价是很小的。
所以在一个数据页中查找指定主键值的记录的过程分为两步:
通过二分法确定该记录所在的槽,并找到该槽所在分组中主键值最小的那条记录。
通过记录的next_record属性遍历该槽所在的组中的各个记录。
Page Header(页面头部)
设计InnoDB的大叔们为了能得到一个数据页中存储的记录的状态信息,比如本页中已经存储了多少条记录,第一条记录的地址是什么,页目录中存储了多少个槽等等,特意在页中定义了一个叫Page Header的部分,它是页结构的第二部分,这个部分占用固定的56个字节,专门存储各种状态信息,具体各个字节都是干嘛的看下表:
| Name |
Space occupied |
Description |
## PAGE_N_DIR_SLOTS | ##2bytes |
|
PAGE_HEAP_TOP | 2Bytes | Free Space |
PAGE_N_HEAP | 2bytes |
|
PAGE_FREE | 2Bytes | next_record, and the records in this singly linked list can be reused) |
PAGE_GARBAGE | 2Bytes |
|
PAGE_LAST_INSERT | 2Bytes |
|
##PAGE_DIRECTION
| BytesRecord the direction of insertion |
| ##PAGE_N_DIRECTION
2Bytes |
The number of records continuously inserted in one direction |
| PAGE_N_RECS
2Bytes |
The number of records in the page (excluding minimum and maximum records and records marked for deletion) |
| PAGE_MAX_TRX_ID
8bytes |
Modify the maximum transaction ID of the current page, this value is only defined in the secondary index |
| PAGE_LEVEL
2bytes |
The level of the current page in the B-tree |
| PAGE_INDEX_ID
8bytes |
Index ID, indicating which index the current page belongs to |
| PAGE_BTR_SEG_LEAF
10bytes |
The header information of the B tree leaf segment is only defined on the Root page of the B tree |
| PAGE_BTR_SEG_TOP
10bytes |
Header information of B-tree non-leaf segments, only in B-tree Root page definition |
If you have read the previous article carefully, you must be clear about the meaning from PAGE_N_DIR_SLOTS to PAGE_LAST_INSERT and PAGE_N_RECS. If you are not clear, I'm sorry. You should go back and read the previous article again. Don’t worry if you don’t understand the rest of the status information. You have to eat one bite at a time and learn things bit by bit (be sure to be calm and don’t be frightened by these nouns). Here we first talk about the meaning of PAGE_DIRECTION and PAGE_N_DIRECTION:
-
##PAGE_DIRECTION If the primary key value of a newly inserted record is greater than the primary key value of the previous record, we say that the insertion direction of this record is to the right, and vice versa. The status used to indicate the insertion direction of the last record is PAGE_DIRECTION.
-
PAGE_N_DIRECTION Assuming that the direction of inserting new records several times in a row is the same, InnoDB will insert new records along the Record the number of records inserted in the same direction. This number is represented by the status PAGE_N_DIRECTION. Of course, if the insertion direction of the last record changes, the value of this status will be cleared and counted again.
As for the attributes we didn’t mention, I didn’t mention them because you don’t need to know them now. Don't worry, when we finish learning the following content, when you look back, everything will be so clear. File HeaderThe Page Header mentioned above is specifically for the various status information recorded on the data page, such as Tell me how many records and slots there are in the page. The File Header we are describing now is common to various types of pages, which means that different types of pages will have File Header as the first component, which describes some specific Some information common to all kinds of pages, such as what is the number of this page, who is the previous page and the next page? This part occupies a fixed number of 38 bytes , is composed of the following contents:
##Name
| Space occupied |
Description |
|
FIL_PAGE_SPACE_OR_CHKSUM | 4bytes |
|
FIL_PAGE_OFFSET | 4bytes |
|
FIL_PAGE_PREV
| bytesPage number of the previous page |
|
FIL_PAGE_NEXT
| bytesPage number of the next page |
|
FIL_PAGE_LSN
| BytesThe corresponding log sequence position when the page was last modified (English name is: Log Sequence Number) |
|
FIL_PAGE_TYPE
| bytesType of the page |
| ##FIL_PAGE_FILE_FLUSH_LSN
8Bytes |
are only defined in one page of the system table space, which means that the file has been refreshed to at least the corresponding LSN value |
| FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID
4bytes |
Which table space does the page belong to |
Contrast this table, let’s look at a few of the more important parts:
-
FIL_PAGE_SPACE_OR_CHKSUM
This represents the verification of the current page and (checksum). What is a checksum? That is, for a very long byte string, we will use some algorithm to calculate a shorter value to represent the long byte string. This relatively short value is called check and. In this way, before comparing two very long byte strings, first compare the checksums of these two long byte strings. If the checksums are different, the two long byte strings must be different, so direct comparison is omitted. The time consumption of two relatively long byte strings.
-
FIL_PAGE_OFFSET
Each page has a separate page number, just like your ID card number , InnoDB can uniquely locate a page through the page number.
-
FIL_PAGE_TYPE
This represents the type of the current page, as we said before, InnoDB Pages are divided into different types for different purposes. What we introduced above are actually data pages that store records. In fact, there are many other types of pages, as detailed in the following table:
| Type Name |
Hex |
Description |
FIL_PAGE_TYPE_ALLOCATED |
0x0000 |
Latest allocation, not used yet |
##FIL_PAGE_UNDO_LOG | 0x0002 | Undo Log Page |
##FIL_PAGE_INODE
|
Segment Information Node |
|
FIL_PAGE_IBUF_FREE_LIST
|
Insert Buffer free list |
|
##FIL_PAGE_IBUF_BITMAP
0x0005 | Insert Buffer Bitmap |
| ##FIL_PAGE_TYPE_SYS
0x0006 |
|
##FIL_PAGE_TYPE_TRX_SYS |
0x0007Transaction System Data |
|
FIL_PAGE_TYPE_FSP_HDR |
0x0008Table space header information |
| ##FIL_PAGE_TYPE_XDES |
0x0009
Extended Description Page |
| FIL_PAGE_TYPE_BLOB |
0x000A
Overflow Page | | FIL_PAGE_INDEX |
0x45BF
Index page, which is what we call data page
|
|
The type of data page where we store records is actually FIL_PAGE_INDEX, which is the so-called index page. As for what an index is, let’s listen to the explanation next time~
-
FIL_PAGE_PREV and FIL_PAGE_NEXT
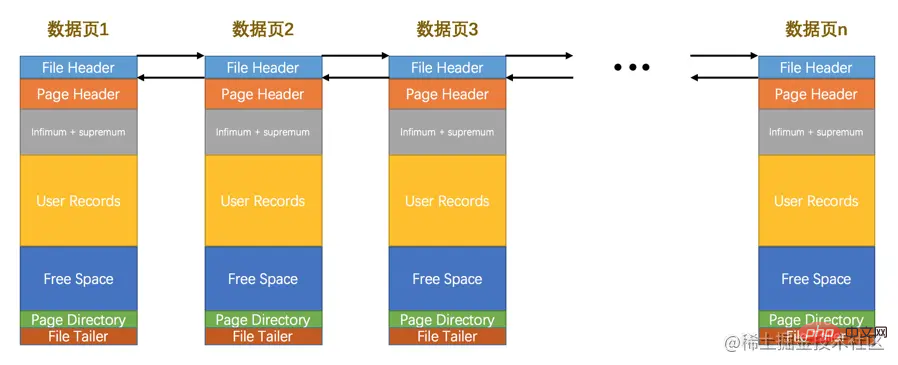
We emphasized before,InnoDB stores data in units of pages. Sometimes when we store certain types of data, it takes up a very large amount of space (for example, there can be thousands of records in a table), InnoDB It may not be possible to allocate a very large storage space for so much data at one time. If it is scattered and stored in multiple discontinuous pages, these pages need to be associated, FIL_PAGE_PREV and FIL_PAGE_NEXT represents the page numbers of the previous and next pages of this page respectively. In this way, many pages are connected in series by establishing a doubly linked list, without the need for these pages to be physically connected. It should be noted that not all types of pages have the properties of the previous and next pages, but the data page we are talking about in this episode (that is, the type is FIL_PAGE_INDEX page) has these two attributes, so all data pages are actually a double linked list, like this:
About We will not use the other attributes of File Header for the time being. We will mention them when we use them~
File Trailer
We know that the InnoDB storage engine will The data is stored on the disk, but the disk speed is too slow. The data needs to be loaded into the memory for processing in units of page. If the data in the page is modified in the memory, then in a certain page after the modification, It takes a while to synchronize the data to disk. But what should I do if the power is cut off halfway through synchronization? Isn’t this awkward? In order to detect whether a page is complete (that is, whether there is an embarrassing situation where only half of the page is synchronized during synchronization), the uncles who designed InnoDB added a File Trailer at the end of each page. part, this part consists of 8 bytes, which can be divided into 2 small parts:
-
The first 4 bytes represent the checksum of the page
This part corresponds to the checksum in File Header. Whenever a page is modified in memory, its checksum must be calculated before synchronization. Because File Header is at the front of the page, the checksum will be synchronized to the disk first. When completely written, the checksum will also be written to the end of the page. If full synchronization is successful, the checksums at the beginning and end of the page should be consistent. If the power is cut off halfway through writing, then the checksum in File Header represents the modified page, and the checksum in File Trailer represents If the original page is different, it means that there was an error during synchronization.
-
The last 4 bytes represent the corresponding log sequence position (LSN) when the page was last modified
This part is also for verifying the integrity of the page, only However, we haven’t said what LSN means yet, so you can ignore this attribute for now.
This File Trailer is similar to File Header and is common to all types of pages.
Summary
InnoDB has designed different types of pages for different purposes. We call the page used to store records data page. -
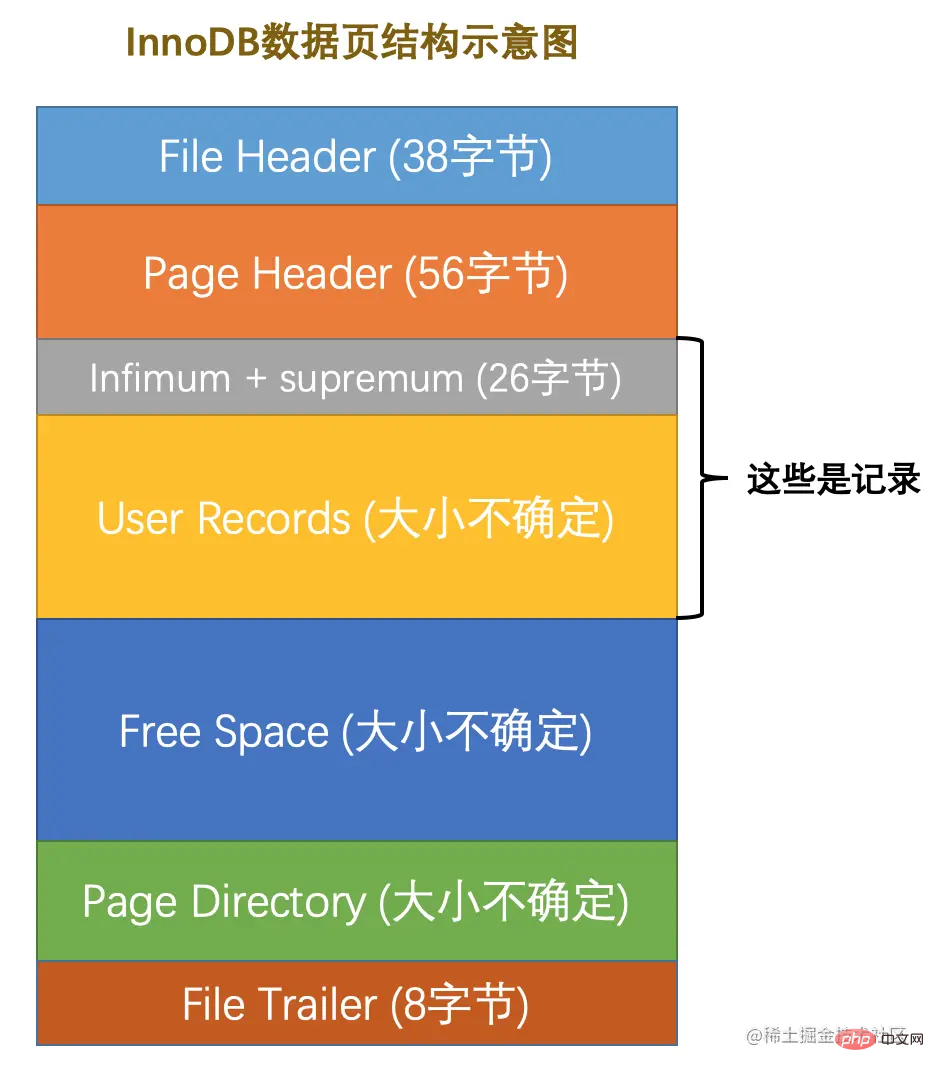
A data page can be roughly divided into 7 parts, which are
-
File Header, which represents some general information of the page , occupying a fixed 38 bytes.
-
Page Header, represents some information exclusive to the data page, occupying a fixed 56 bytes.
-
Infimum Supremum, two virtual pseudo records, representing the minimum and maximum records in the page, occupying a fixed 26 bytes.
-
User Records: The part that actually stores the records we inserted, the size is not fixed.
-
Free Space: The unused part of the page, the size is uncertain.
-
Page Directory: The relative position of some records in the page, that is, the address offset of each slot in the page, is not fixed in size. The more records inserted, the more occupied this part will be. The more space there is.
-
File Trailer: Used to check whether the page is complete, occupying a fixed 8 bytes.
The header information of each record has a next_record attribute, so that all records in the page are concatenated into a singly linked list. -
InnoDB will divide the records in the page into several groups, and the address offset of the last record in each group will be used as a slot, stored in Page Directory, so it is very fast to find records based on the primary key in a page. It is divided into two steps:
The File Header part of each data page has the numbers of the previous and next pages, so all the data pages will form a Double linked list. In order to ensure the integrity of the page synchronized from memory to disk, the checksum of the data in the page and the corresponding ## when the page was last modified are stored at the beginning and end of the page. #LSN value, if the checksum of the header and tail and the LSN value are not verified successfully, it means there is a problem with the synchronization process. Recommended learning: mysql video tutorial
|
|
|