
Home >Common Problem >What is the purpose of data normalization?
What is the purpose of data normalization?

- 青灯夜游Original
- 2021-05-07 16:33:1828021browse
The purpose of data normalization is to limit the preprocessed data to a certain range, thereby eliminating the adverse effects caused by singular sample data. After data normalization, the speed of gradient descent to find the optimal solution can be accelerated, and the accuracy may be improved (such as KNN).

The operating environment of this tutorial: Windows 7 system, Dell G3 computer.
#In the field of machine learning, differentEvaluation indicators(That is, different features in the feature vector are the different evaluation indicators) Often have different dimensions and dimensional units. This situation will affect the results of data analysis. In order to eliminate the dimensional influence between indicators, datastandardization is required, to solve the comparability between data indicators. After the original data is processed through data standardization, each indicator is in the same order of magnitude, which is suitable for comprehensive comparative evaluation. Among them, the most typical one is the normalization processing of data. (You can refer to study: Data standardization/normalization)
# #In short, the purpose of normalization is to limit the preprocessed data to a certain range (such as [0,1] or [-1,1]), thereby eliminating Singular sample dataAdverse effects caused by.
##1) In statistics, the specific role of normalization is to summarize a unified sample statistical distribution. Normalization between 0 and 1 is a statistical probability distribution, and normalization between -1 and 1 is a statistical coordinate distribution.
2) Singular sample data refers to a sample vector that is particularly large or small relative to other input samples (i.e. feature vector), for example, the following is sample data x1, x2, x3, x4, x5, x6 with two features (feature vector -> column vector), where the two features of the x6 sample are different from other samples The language difference is relatively large, therefore, x6 is considered to be singular sample data.
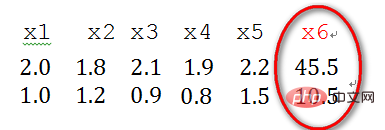
#The existence of singular sample data will cause the training time to increase, and may also lead to failure to converge. Therefore, When there is singular sample data, the preprocessed data needs to be normalized before training; conversely , when there is no singular sample data, normalization does not need to be performed.
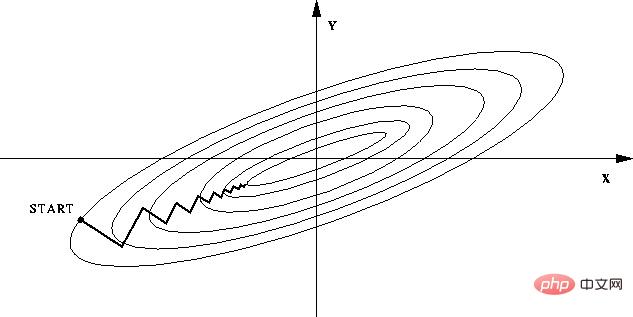
#-- If normalization is not performed, the objective function will become "flat" due to the large difference in the values of different features in the feature vector. In this wayWhen performing gradient descent, the direction of the gradient will deviate from the direction of the minimum value and take many detours, that is, the training time is too long.
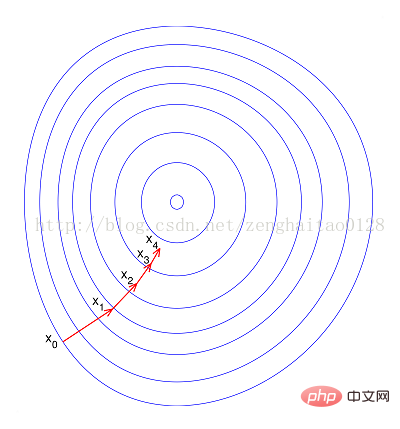
--If normalized, the objective function will appear more "round", which will greatly speed up the training and reduce the number of steps. Many detours.
##To sum up It can be seen that normalization has the following benefits, namely
1)Speed up after normalization The speed of gradient descent to find the optimal solution;
##2)Normalization may improve accuracy (such as KNN)
##Note: There is no data standardization method that can improve the accuracy of the algorithm and accelerate the convergence speed of the algorithm when applied to every problem and every model. For more related knowledge, please visit the FAQ
column!The above is the detailed content of What is the purpose of data normalization?. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- python method to normalize multidimensional array
- In database design, what is the process of converting ER diagram into relational data model?
- What is the difference between database views and tables
- How to get the last value of a column of data in excel
- In the database physical design phase, what is the purpose of creating indexes for data tables?