
Home >Backend Development >Python Tutorial >Analyzing Python garbage collection mechanism
Analyzing Python garbage collection mechanism

- coldplay.xixiforward
- 2020-10-29 17:23:452392browse
Python Tutorial column will analyze the Python garbage collection mechanism today!

The reference counter is the main one, code recycling and mark clearing are the secondary ones
1.1 Big Butler refchainIn the C source code of Python, there is a circular two-way linked list called refchain. This linked list is quite awesome, because once an object is created in the Python program, the object will be added to the refchain linked list. middle. In other words, he saves all objects. 1.2 Reference Counter- There is an ob_refcnt inside all objects in the refchain to save the reference counter of the current object. As the name suggests, it is the number of times it has been referenced.
- When the value is referenced multiple times, the data will not be repeatedly created in the memory, but the reference counter 1. When the object is destroyed, the reference counter will be -1. If the reference counter is 0, the object will be removed from the refchain list and destroyed in the memory (not considering special circumstances such as caching).
age = 18number = age # 对象18的引用计数器 + 1del age # 对象18的引用计数器 - 1def run(arg): print(arg) run(number) # 刚开始执行函数时,对象18引用计数器 + 1,当函数执行完毕之后,对象18引用计数器 - 1 。num_list = [11,22,number] # 对象18的引用计数器 + 1复制代码1.3 Mark clearing & generational recyclingGarbage collection based on reference counters is very convenient and simple, but it still has the problem of circular references, which prevents some data from being recycled normally. , for example:
v1 = [11,22,33] # refchain中创建一个列表对象,由于v1=对象,所以列表引对象用计数器为1.v2 = [44,55,66] # refchain中再创建一个列表对象,因v2=对象,所以列表对象引用计数器为1.v1.append(v2) # 把v2追加到v1中,则v2对应的[44,55,66]对象的引用计数器加1,最终为2.v2.append(v1) # 把v1追加到v1中,则v1对应的[11,22,33]对象的引用计数器加1,最终为2.del v1 # 引用计数器-1del v2 # 引用计数器-1复制代码
- For the above code, you will find that after performing the del operation, no variables will use those two list objects, but due to the problem of circular reference, their reference counters are not 0. So their status: never used, never destroyed. If there are too many such codes in the project, memory will be consumed until the memory is exhausted and the program crashes.
- In order to solve the problem of circular references, mark clearing technology is introduced to perform special processing on objects that may have circular references. The types of possible circular applications include: list, tuple, dictionary, set, self Define classes and other types that enable data nesting.
Mark Clear: Create a special linked list specifically for saving lists, tuples, dictionaries, collections, custom classes and other objects, and then check whether the objects in this linked list are There is a circular reference. If it exists, let the reference counters of both parties be -1.
Generational Recycling: Optimize the linked list in mark clearing and split those objects that may have circular references into three linked lists. The linked list is called: 0/1/2 three generations , each generation can store objects and thresholds. When the threshold is reached, each object in the corresponding linked list will be scanned, except for circular references, each will be decremented by 1 and objects with a reference counter of 0 will be destroyed.
// 分代的C源码#define NUM_GENERATIONS 3struct gc_generation generations[NUM_GENERATIONS] = { /* PyGC_Head, threshold, count */
{{(uintptr_t)_GEN_HEAD(0), (uintptr_t)_GEN_HEAD(0)}, 700, 0}, // 0代
{{(uintptr_t)_GEN_HEAD(1), (uintptr_t)_GEN_HEAD(1)}, 10, 0}, // 1代
{{(uintptr_t)_GEN_HEAD(2), (uintptr_t)_GEN_HEAD(2)}, 10, 0}, // 2代};复制代码Special note: The threshold and count of generation 0 and generation 1 and 2 have different meanings. 0 generation, count represents the number of objects in the generation 0 linked list, threshold represents the threshold of the number of objects in the generation 0 linked list, if it exceeds, a generation 0 scan check will be performed.
Generation 1, count represents the number of generation 0 linked list scans, and threshold represents the threshold of the number of generation 0 linked list scans. If it exceeds the threshold, a generation 1 scan check will be performed.
Generation 2, count represents the number of scans of the 1st generation linked list, and threshold represents the threshold of the number of scans of the 1st generation linked list. If it exceeds the threshold, a 2nd generation scan check will be performed. 1.4 Scenario SimulationThe detailed process of memory management and garbage collection will be explained based on the bottom layer of C language and combined with the diagram. Step one: When creating an object age=19, the object will be added to the refchain list.
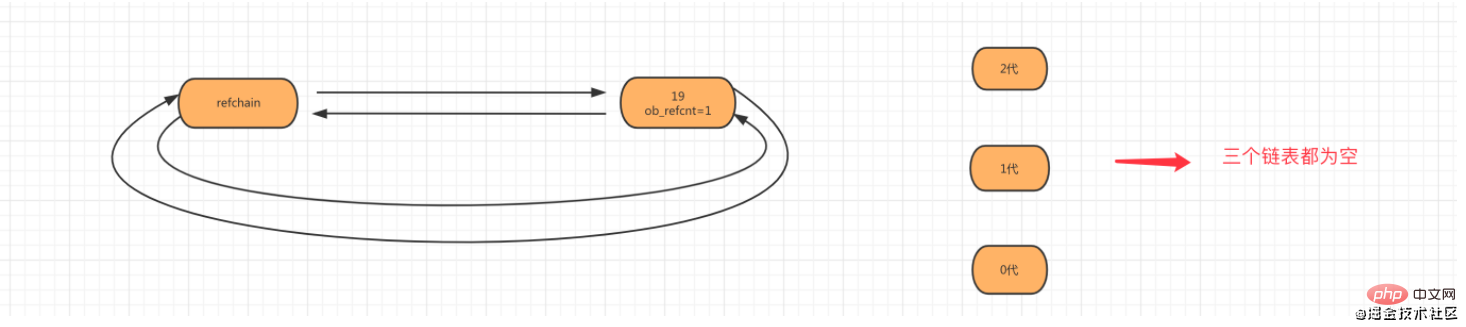
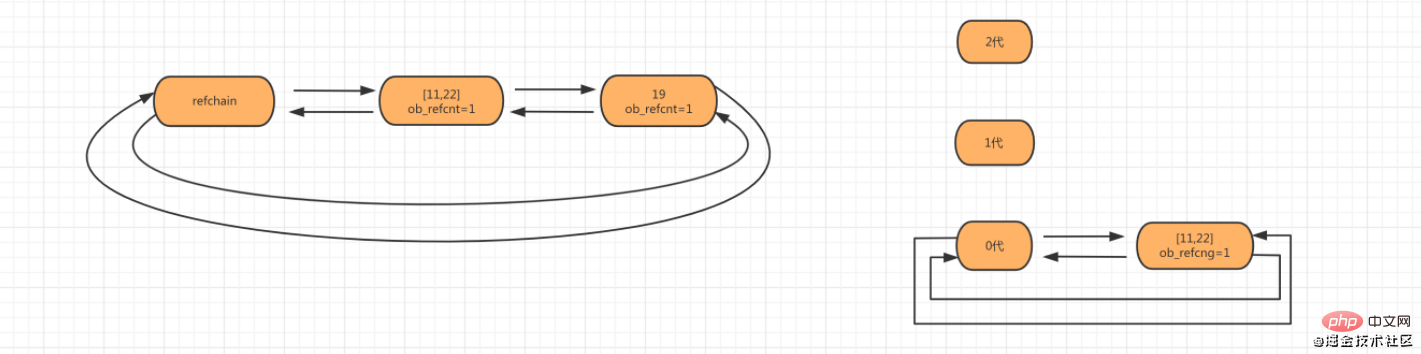
- If generations 2 and 1 do not reach the threshold, scan generation 0 and let count 1 of generation 1.
- If the 2nd generation has reached the threshold, the three linked lists of 2, 1, and 0 are spliced together for a full scan, and the count of the 2nd, 1st, and 0th generations is reset to 0.
- If generation 1 has reached the threshold, the two linked lists of 1 and 0 are spliced together for scanning, and the counts of all generations 1 and 0 are reset to 0.
- 扫描链表,把每个对象的引用计数器拷贝一份并保存到 gc_refs中,保护原引用计数器。
- 再次扫描链表中的每个对象,并检查是否存在循环引用,如果存在则让各自的gc_refs减 1 。
- 再次扫描链表,将 gc_refs 为 0 的对象移动到unreachable链表中;不为0的对象直接升级到下一代链表中。
- 处理unreachable链表中的对象的 析构函数 和 弱引用,不能被销毁的对象升级到下一代链表,能销毁的保留在此链表。析构函数,指的就是那些定义了__del__方法的对象,需要执行之后再进行销毁处理。
- 最后将 unreachable 中的每个对象销毁并在refchain链表中移除(不考虑缓存机制)。
至此,垃圾回收的过程结束。
1.5 缓存机制
从上文大家可以了解到当对象的引用计数器为0时,就会被销毁并释放内存。而实际上他不是这么的简单粗暴,因为反复的创建和销毁会使程序的执行效率变低。Python中引入了“缓存机制”机制。
例如:引用计数器为0时,不会真正销毁对象,而是将他放到一个名为 free_list 的链表中,之后会再创建对象时不会在重新开辟内存,而是在free_list中将之前的对象来并重置内部的值来使用。
- float类型,维护的free_list链表最多可缓存100个float对象。
v1 = 3.14 # 开辟内存来存储float对象,并将对象添加到refchain链表。 print( id(v1) ) # 内存地址:4436033488 del v1 # 引用计数器-1,如果为0则在rechain链表中移除,不销毁对象,而是将对象添加到float的free_list. v2 = 9.999 # 优先去free_list中获取对象,并重置为9.999,如果free_list为空才重新开辟内存。 print( id(v2) ) # 内存地址:4436033488 # 注意:引用计数器为0时,会先判断free_list中缓存个数是否满了,未满则将对象缓存,已满则直接将对象销毁。复制代码
- int类型,不是基于free_list,而是维护一个small_ints链表保存常见数据(小数据池),小数据池范围:-5 <= value < 257。即:重复使用这个范围的整数时,不会重新开辟内存。
v1 = 38 # 去小数据池small_ints中获取38整数对象,将对象添加到refchain并让引用计数器+1。 print( id(v1)) #内存地址:4514343712 v2 = 38 # 去小数据池small_ints中获取38整数对象,将refchain中的对象的引用计数器+1。 print( id(v2) ) #内存地址:4514343712 # 注意:在解释器启动时候-5~256就已经被加入到small_ints链表中且引用计数器初始化为1, # 代码中使用的值时直接去small_ints中拿来用并将引用计数器+1即可。另外,small_ints中的数据引用计数器永远不会为0 # (初始化时就设置为1了),所以也不会被销毁。复制代码
- str类型,维护unicode_latin1[256]链表,内部将所有的ascii字符缓存起来,以后使用时就不再反复创建。
v1 = "A" print( id(v1) ) # 输出:4517720496 del v1 v2 = "A" print( id(v1) ) # 输出:4517720496 # 除此之外,Python内部还对字符串做了驻留机制,针对只含有字母、数字、下划线的字符串(见源码Objects/codeobject.c),如果 # 内存中已存在则不会重新在创建而是使用原来的地址里(不会像free_list那样一直在内存存活,只有内存中有才能被重复利用)。 v1 = "asdfg" v2 = "asdfg" print(id(v1) == id(v2)) # 输出:True复制代码
list类型,维护的free_list数组最多可缓存80个list对象。
v1 = [11,22,33] print( id(v1) ) # 输出:4517628816del v1 v2 = ["你","好"] print( id(v2) ) # 输出:4517628816复制代码
- tuple类型,维护一个free_list数组且数组容量20,数组中元素可以是链表且每个链表最多可以容纳2000个元组对象。元组的free_list数组在存储数据时,是按照元组可以容纳的个数为索引找到free_list数组中对应的链表,并添加到链表中。
v1 = (1,2)
print( id(v1) )del v1 # 因元组的数量为2,所以会把这个对象缓存到free_list[2]的链表中。v2 = ("哈哈哈","Alex") # 不会重新开辟内存,而是去free_list[2]对应的链表中拿到一个对象来使用。print( id(v2) )复制代码
- dict类型,维护的free_list数组最多可缓存80个dict对象
v1 = {"k1":123}
print( id(v1) ) # 输出:4515998128
del v1
v2 = {"name":"哈哈哈","age":18,"gender":"男"}
print( id(v1) ) # 输出:4515998128复制代码
C语言源码底层分析
相关免费学习推荐:python教程(视频)
The above is the detailed content of Analyzing Python garbage collection mechanism. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Discuss PHP's garbage collection mechanism
- Detailed explanation of Java automatic garbage collection tutorial
- A brief analysis of the heap and garbage collection mechanism
- Detailed explanation of PHP7 garbage collection mechanism (with complete flow chart of GC processing)
- Understand the garbage collection mechanism, memory leaks, and closures of JS series (3) with one piece of paper