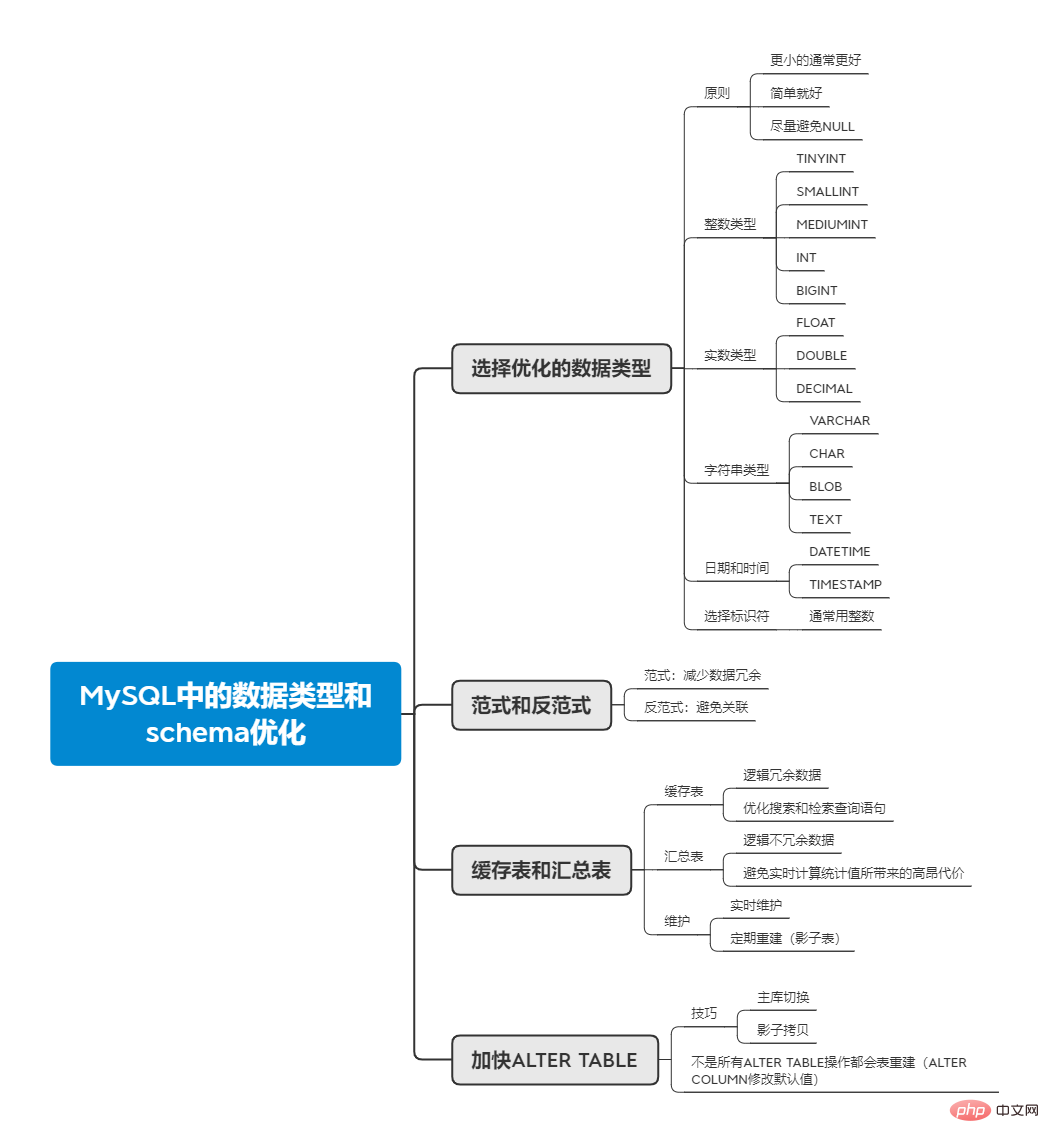
最近在学习MySQL优化方面的知识。Mysql教程栏目就数据类型和schema方面的优化进行介绍。

1. 选择优化的数据类型
MySQL支持的数据类型有很多,而如何选择出正确的数据类型,对于性能是至关重要的。以下几个原则能够帮助确定数据类型:
-
更小的通常更好
应尽可能使用可以正确存储数据的最小数据类型,够用就好。这样将占用更少的磁盘、内存和缓存,而在处理时也会耗时更少。
-
简单就好
当两种数据类型都能胜任一个字段的存储工作时,选择简单的那一方,往往是最好的选择。例如整型和字符串,由于整型的操作代价要小于字符,所以当在两者之间选择时,选择整型通常能够获得更好的性能。
-
尽量避免NULL
当列可为NULL时,对于MySQL来说,在索引和值比较等方面需要做更多的工作,虽然对性能的影响不是很大,但也应尽量避免设计为可为NULL。
除了以上原则,在选择数据类型时,需遵循的步骤:首先确定合适的大类型,例如数据、字符串、时间等;然后再选择具体的类型。下面将讨论大类型下的一些具体类型,首先是数字,有两种类型:整数和实数。
1.1 整数类型
整数类型和所占用的空间如下:
| 整数类型 |
空间大小(bit) |
| TINYINT |
8 |
| SMALLINT |
16 |
| MEDIUMINT |
24 |
| INT |
32 |
| BIGINT |
64 |
The range that the integer type can store is related to the space size: -2^(N-1) to 2^(N-1)-1, where N is the number of digits in the space size.
The integer type has the optional attribute UNSIGNED. When declared, it means that negative numbers are not allowed, and the storage range becomes: 0 to 2^(N)-1, which is doubled.
In MySQL, you can also specify the width for the integer type, such as INT(1), but this is of little significance and does not limit the legal range of values. It can still store -2^31 to 2 The value of ^31-1 affects the number of characters displayed by the interactive tool with MySQL.
1.2 Real number type
The comparison of real number types is as follows:
| Real number type |
Space size (Byte) |
Value range |
Calculation accuracy |
| FLOAT |
4 |
Negative numbers: -3.4E 38~-1.17E-38; non-negative numbers: 0, 1.17E-38~3.4E 38 |
Approximate calculation |
| DOUBLE |
8 |
Negative numbers: -1.79E 308~-2.22E-308; Non-negative numbers: 0, 2.22E-308~1.79E 308 |
Approximate calculation |
| DECIMAL |
Related to accuracy |
Same as DOUBLE |
Accurate calculation |
As can be seen from the above , FLOAT and DOUBLE both have fixed space sizes, but at the same time because they use standard floating point operations, they can only be calculated approximately. DECIMAL can achieve accurate calculations, but at the same time it takes up more space and consumes more computational overhead.
The space occupied by DECIMAL is related to the specified precision. For example, DECIMAL(M,D):
- M is the maximum length of the entire number, and the value range is [1, 65 ], the default value is 10;
- D is the length after the decimal point, the value range is [0, 30], and D
When MySQL stores the DECIMAL type, it will be stored as a binary string. Every 4 bytes store 9 numbers. When there are less than 9 digits, the space occupied by the number is as follows:
| Number of digits |
Space occupied (Byte) |
| 1, 2 |
1 |
##3, 4 | 2 |
5, 6 | 3 |
7, 8 | 4 |
The decimal point will be stored separately, and the decimal point will also occupy 1 byte. Here are two calculation examples:
DECIMAL(18, 9): The length of the integer part is 9 and occupies 4 bytes. The length of the decimal part is 9 and takes up 4 bytes. At the same time, adding 1 byte for the decimal point, a total of 9 bytes are occupied. - DECIMAL(20, 9): The length of the integer part is 14, occupying 7 (4 3) bytes. The length of the decimal part is 9 and takes up 4 bytes. At the same time, adding 1 byte for the decimal point, a total of 12 bytes are occupied.
-
It can be seen that DECIMAL still takes up a lot of space, so DECIMAL is only needed when precise calculations of decimals are required. In addition, we can also use BIGINT instead of DECIMAL. For example, if we need to ensure the calculation of 5 digits after the decimal point, we can multiply the value by 10 to the fifth power and store it as BIGINT. This can avoid inaccurate floating point storage calculations and DECIMAL at the same time. Exactly computationally expensive problems.
1.3 String type
The most commonly used string types are VARCHAR and CHAR.
VARCHARAs a variable-length string, 1 or 2 extra bytes will be used to record the length of the string. When the maximum length does not exceed 255, only 1 byte will be recorded. Length, if it exceeds 255, 2 bytes are required. Applicable scenarios for VARCHAR:
The maximum length is much larger than the average length;- Columns are updated less often to avoid fragmentation;
- Complex use Character sets, such as UTF-8, each character can be stored using different bytes.
-
CHAR is a fixed-length string. Sufficient space is allocated according to the defined string length. Applicable scenarios:
is short in length; - is similar in length, such as MD5;
- is updated frequently.
-
In addition to VARCHAR and CHAR, for storing large strings, you can use the BLOB and TEXT types. The difference between BLOB and TEXT is that
BLOB is stored in binary format, while TEXT is stored in character format. This also leads to the fact that BLOB type data does not have the concept of a character set and cannot be sorted by characters, while the TEXT type has the concept of a character set and can be sorted by characters. The usage scenarios of both are also determined by the storage format. When storing binary data, such as pictures, BLOB should be used, and when storing text, such as articles, the TEXT type should be used.
1.4 Date and time types
The minimum time granularity that can be stored in MySQL is seconds. Commonly used date types include DATETIME and TIMESTAMP.
Type | Storage content | Space size (Byte) | Time zone concept |
DATETIME | An integer in the format YYYYMMDDHHMMSS | 8 | None |
TIMESTAMP | The number of seconds since midnight on January 1, 1970 | 4 | 有 |
The value displayed by TIMESTAMP will depend on the time zone, which means that the values queried in different time zones will be different. In addition to the differences listed above, TIMESTAMP also has a special attribute. During insertion and update, if the value of the first TIMESTAMP column is not specified, the value of this column will be set to the current time.
We should try to use TIMESTAMP during the development process, mainly because its space size is only half of DATETIME and its space efficiency is higher.
What if we want to store the date and time accurate to seconds later? Since MySQL does not provide it, we can use BIGINT to store micro-level timestamps, or use DOUBLE to store the decimal part after seconds.
1.5 Choosing Identifiers
Generally speaking, integers are the best choice for identifiers, mainly because they are simple, fast to calculate, and can use AUTO_INCREMENT.
2. Paradigm and anti-paradigm
Simply put, paradigm is the level of a certain design standard that the table structure of a data table conforms to. In the first normal form, attributes are inseparable. The tables built by the current RDBMS system are all in line with the first normal form. The second normal form eliminates the partial dependence of non-primary attributes on codes (which can be understood as primary keys). The third normal form eliminates the transitive dependence of non-primary attributes on codes. For a specific introduction, you can read this answer on Zhihu (https://www.zhihu.com/question/24696366/answer/29189700)
StrictNormalized database , each fact data will appear and only appear once, There will be no data redundancy, this can bring the following benefits:
- Faster update operation;
- Modify less data;
- The table is smaller, fits better in memory, and performs operations faster;
- Less need for DISTINCT or GROUP BY.
But also because the data is scattered in various tables, the tables need to be related when querying. The advantage of anti-paradigm is that does not need to be associated and the data is stored redundantly.
In actual applications, complete normalization or complete de-normalization will not occur. It is often necessary to mix paradigm and de-normalization. It is often best to use a partially normalized schema. s Choice. Regarding database design, I saw this paragraph on the Internet and you can feel it.
Database design should be divided into three realms:
First realm: Just getting started with database design, the importance of paradigm has not yet been deeply understood. The anti-paradigm design that appears at this time will generally cause problems.
The second realm: As you encounter problems and solve them, you gradually understand the real benefits of the paradigm, so that you can quickly design a low-redundancy and high-efficiency database.
The third realm: After N years of training, you will definitely find the limitations of the paradigm. At this time, break the paradigm and design a more reasonable anti-paradigm part.
The paradigm is like the moves in martial arts. Beginners who try not to follow the moves will only die in embarrassment. After all, the tricks are the essence summarized by the masters. As your martial arts improves and you become proficient in the moves, you will inevitably discover the limitations of the moves and either forget them or create your own.
As long as you work hard and endure a few more years, you can always reach the second state, and you will always feel that the paradigm is a classic. At this time, those who can quickly break through the limitations of the paradigm without relying too much on the paradigm are naturally experts.
4. Cache table and summary table
In addition to the anti-paradigm mentioned above and storing redundant data in the table, we can also create a completely independent summary table or Cache the table to meet the needs of retrieval.
Cache table refers to a table that stores data that can be obtained from other tables in the schema, that is, logically redundant data. The Summary table refers to the storage of non-redundant data calculated by aggregating data using GROUP BY and other statements.
Cache tables can be used to optimize search and retrieval query statements. The techniques that can be used here include using different storage engines for cache tables. For example, the main table uses InnoDB, while the cache table can Use MyISAM to get a smaller index footprint. You can even put the cache table into a specialized search system, such as Lucene.
The summary table is to avoid the high cost of calculating statistical values in real time. The cost comes from two aspects. One is that most of the data in the table needs to be scanned, and the other is to create a specific The index will have an impact on the UPDATE operation. For example, to query the number of WeChat Moments in the past 24 hours, you can scan the entire table every hour and write a record to the summary table after statistics. When querying, you only need to query the latest 24 records on the summary table instead of every During each query, the entire table is scanned for statistics.
When using cache tables and summary tables, we must decide whether to maintain data in real time or rebuild periodically, depending on our needs. Compared with real-time maintenance, regular reconstruction can save more resources and cause less table fragmentation. During reconstruction, we still need to ensure that the data is available during operation, which needs to be achieved through "shadow table". Create a shadow table behind the real table. After filling in the data, switch the shadow table and the original table through an atomic rename operation.
5. Speed up the ALTER TABLE operation
When MySQL performs the ALTER TABLE operation, it often creates a new table, then retrieves the data from the old table and inserts it into the new table, and then deletes it. Old tables. If the table is large, this will take a long time and cause MySQL service interruption. In order to avoid service interruption, you can usually use two techniques:
- Perform the ALTER TABLE operation on a machine that does not provide services, and then communicate with the main library that provides services Switch;
- "Shadow copy", create a new table that has nothing to do with the original table, and switch through the rename operation after the data migration is completed.
But not all ALTER TABLE operations will cause table reconstruction. For example, when modifying the default value of a field, using MODIFY COLUMN will cause table reconstruction, while using ALTER COLUMN will No table reconstruction is performed and the operation is very fast. This is because when ALTER COLUMN modifies the default value, it directly modifies the .frm file of the existing table (which stores the default value of the field) without rebuilding the table.
More related free learning recommendations: mysql tutorial(Video)
The above is the detailed content of Data type and schema optimization in MySQL. For more information, please follow other related articles on the PHP Chinese website!