
Home >Backend Development >C#.Net Tutorial >What files are generated after compiling in C language?
What files are generated after compiling in C language?

- 青灯夜游Original
- 2020-10-22 19:15:1321716browse
C language compiles to generate ".OBJ" binary file. After the C language source program is compiled by the C language compiler, a binary file with a suffix of ".OBJ" is generated. Finally, a software called a "linker" combines this ".OBJ" file with various programs provided by the C language. The library functions are connected together to generate a file with the suffix ".EXE".

After the C language source program is compiled by the C language compiler, a binary file (called an object file) with the suffix ".OBJ" is generated, and finally A software called "Link" is used to connect this ".OBJ" file with various library functions provided by the C language to generate an executable file with the suffix ".EXE". Obviously C language cannot be executed immediately.
Tutorial recommendation: "c language tutorial video"
CThe four stages of compilation and execution of language files are described respectively
The compilation and linking process of the C language requires converting a c program (source code) we wrote into A program (executable code) that can run on hardware needs to be compiled and linked. Compilation is the process of translating source code in text form into object files in machine language form. Linking is the process of organizing target files, operating system startup code and used library files to finally generate executable code. The process diagram is as follows:
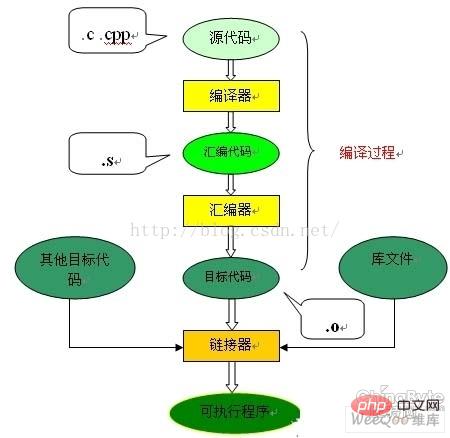
As you can see from the picture, the entire code compilation process is divided into two parts: compilation and linking. Process, compilation corresponds to the part enclosed by curly brackets in the figure, and the rest is the linking process.
Compilation process
The compilation process can be divided into two stages: compilation and assembly.
Compilation
Compilation is to read the source program (character stream), analyze it lexically and syntactically, convert high-level language instructions into functionally equivalent assembly code, and compile the source file The process consists of two main stages:
The first stage is the preprocessing stage, which is performed before the formal compilation stage. The preprocessing phase will modify the content of the source file based on the preprocessing directives that have been placed in the file. For example, the #include directive is a preprocessing directive that adds the contents of the header file to the .cpp file. This method of modifying source files before compilation provides great flexibility to adapt to the constraints of different computer and operating system environments. The code required for one environment may be different from the code required for another environment because the available hardware or operating systems are different. In many cases, you can put code for different environments in the same file and then modify the code during the preprocessing phase to adapt it to the current environment. Mainly deal with the following aspects:
(1) Macro definition instructions, such as #define a b For this kind of directive, what precompilation needs to do is to replace all a in the program with b, but a as a string constant will not be replace. There are also #undef, which will cancel the definition of a certain macro so that future occurrences of the string will no longer be replaced. (2) conditional compilation instructions, such as #ifdef, #ifndef, #else, #elif, #endif, etc. The introduction of these pseudo-instructions allows programmers to decide which codes to process by the compiler by defining different macros. The precompiler will filter out unnecessary code based on relevant files. (3) The header file contains instructions, such as #include 'FileName' or #include wait. In the header file, the pseudo-instruction #define is generally used to define a large number of macros (the most common ones are character constants), and also contains declarations of various external symbols. The main purpose of using header files is to make certain definitions available to multiple different C source programs. Because in the C source program that needs to use these definitions, you only need to add an #include statement, without having to repeat these definitions in this file. The precompiler will add all the definitions in the header file to the output file it generates for processing by the compiler. The header files included in the c source program can be provided by the system. These header files are generally placed in the /usr/include directory. In the program #include they use angle brackets (< >). In addition, developers can also define their own header files. These files are generally placed in the same directory as the c source program. In this case, double quotes (' '). ( ) Special symbols, the precompiler can recognize some special symbols. For example, the mark appearing in the source program will be interpreted as the current line number (decimal number), and FILE will be interpreted as the currently compiled CThe name of the source program. The precompiler will replace occurrences of these strings in the source program with appropriate values. What the precompiler does is basically "replace" the source program. After this substitution, an output file with no macro definitions, no conditional compilation instructions, and no special symbols is generated. The meaning of this file is the same as the unpreprocessed source file, but the content is different. Next, this output file is translated into machine instructions as the output of the compiler. In the second stage of compilation and optimization, the output file obtained after precompilation contains only constants; such as numbers, strings, variable definitions, and C language keywords, such as main,if,else,for,while,{ ,}, ,-,*,\etc. The work of the compiler is to use lexical analysis and syntax analysis to confirm that all instructions comply with the grammatical rules, and then translate them into equivalent intermediate code representation or assembly code. Optimization processing is a relatively difficult technology in the compilation system. The issues it involves are not only related to the compilation technology itself, but also have a lot to do with the hardware environment of the machine. Part of optimization is the optimization of intermediate code. This optimization is independent of the specific computer. Another kind of optimization is mainly aimed at the generation of target code. For the former optimization, the main work is to delete public expressions, loop optimization (code extraction, strength weakening, changing loop control conditions, merging of known quantities, etc.), copy propagation, and useless assignments deletion, etc. The latter type of optimization is closely related to the hardware structure of the machine. The most important thing to consider is how to make full use of the values of relevant variables stored in each hardware register of the machine to reduce the number of memory accesses. In addition, how to make some adjustments to the instructions according to the characteristics of the machine hardware execution instructions (such as pipeline, RISC, CISC, VLIW, etc.) to make the target code shorter , the execution efficiency is relatively high, and it is also an important research topic. Assembly Assembly actually refers to the process of translating assembly language code into target machine instructions. For each C language source program processed by the translation system, the corresponding target file will eventually be obtained through this processing. What is stored in the target file is the machine language code of the target that is equivalent to the source program. Object files are composed of segments. Usually there are at least two sections in an object file: Code section: This section mainly contains program instructions. This segment is generally readable and executable, but generally not writable. Data segment: mainly stores various global variables or static data used in the program. Generally, data segments are readable, writable, and executable. UNIXThere are three main types of target files in the environment: (1)Relocatable file which contains There is code and data suitable for linking with other object files to create an executable or shared object file. (2)Shared object file This file stores code and data suitable for linking in both contexts. The first is that the linker can process it with other relocatable files and shared object files to create another object file; the second is that the dynamic linker can process it with another executable file and other shared object files. Combined together, they create a process image. (3)Executable file It contains a file that can be executed by a process created by the operating system. What the assembler generates is actually the first type of object file. For the latter two, some other processing is required to obtain them. This is the job of the linker. Linking process The object file generated by the assembler cannot be executed immediately, and there may be many unresolved problems. For example, a function in a source file may refer to a symbol defined in another source file (such as a variable or function call, etc.); a function in a library file may be called in the program ,etc. All these problems need to be solved by the linker. The main job of the linker is to connect related target files to each other, that is, to connect the symbols referenced in one file with the definition of the symbol in another file, so that all these target files become A unified whole that can be loaded and executed by the operating system. Based on the different linking methods of the same library function specified by the developer, the link processing can be divided into two types: (1)Static link In this linking mode, the code of the function will be copied from the static link library where it is located to the final executable program. In this way, these codes will be loaded into the virtual address space of the process when the program is executed. A static link library is actually a collection of object files, each of which contains the code for one or a group of related functions in the library. (2) Dynamic link In this method, the code of the function is placed in what is called a dynamic link library or shared object in a target file. What the linker does at this time is to record the name of the shared object and a small amount of other registration information in the final executable program. When this executable file is executed, the entire contents of the dynamic link library will be mapped into the virtual address space of the corresponding process at runtime. The dynamic linker will find the corresponding function code based on the information recorded in the executable program. For function calls in executable files, dynamic linking or static linking can be used. Using dynamic linking can make the final executable file shorter and save some memory when a shared object is used by multiple processes, because only one copy of the code for this shared object needs to be saved in memory. But it does not necessarily mean that using dynamic links is superior to using static links. In some cases dynamic linking may cause some performance harm. The gcc compiler we use in linux bundles the above processes so that users can complete the compilation work with only one command. This It does facilitate the compilation work, but it is very disadvantageous for beginners to understand the compilation process. The following picture is the compilation process of the gcc agent: As you can see from the picture above: Pre-compile Convert the .c file into a .i file The gcc command used is: gcc –E Corresponding to the preprocessing command cpp Compile Convert the .c/.h file into a .s file The gcc command used is: gcc -S Corresponding to the compilation command cc -S Assembly Convert the .s file into .oFile The gcc command used is: gcc –c The corresponding assembly command is as Link Convert the .o file into an executable program The gcc command used is: gcc Corresponding to the link command is ld To sum up, the compilation process is the above four processes: pre-compilation, compilation, assembly, and linking. LiaUnderstanding the work done in these four processes is helpful for us to understand the working process of header files, libraries, etc., and a clear understanding of the compilation and linking process can also help us locate errors when programming. And trying to mobilize the compiler's error detection when programming will be of great help. 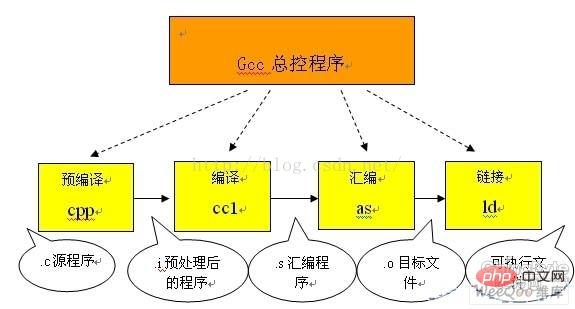
The above is the detailed content of What files are generated after compiling in C language?. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- How to find the maximum value in C language
- When using nested if statements, C language stipulates that else is always what?
- How to convert uppercase and lowercase letters in C language?
- What program should be used to translate a program written in C language so that the computer can recognize it?
- How to express power in C language