
Home >Web Front-end >JS Tutorial >Use Python code examples to demonstrate the practical application of kNN algorithm_Basic knowledge
Use Python code examples to demonstrate the practical application of kNN algorithm_Basic knowledge

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2016-05-16 15:34:542744browse
Neighbor algorithm, or K-nearest neighbor (kNN, k-NearestNeighbor) classification algorithm is one of the simplest methods in data mining classification technology. The so-called K nearest neighbor means k nearest neighbors. It means that each sample can be represented by its k nearest neighbors.
The core idea of the kNN algorithm is that if most of the k nearest adjacent samples of a sample in the feature space belong to a certain category, then the sample also belongs to this category and has the characteristics of samples in this category. This method only determines the category of the sample to be classified based on the category of the nearest one or several samples in determining the classification decision. The kNN method is only relevant to a very small number of adjacent samples when making category decisions. Since the kNN method mainly relies on the limited surrounding samples rather than the method of discriminating the class domain to determine the category, the kNN method is more efficient than other methods for the sample set to be divided with a large number of intersections or overlaps in the class domain. for fit.
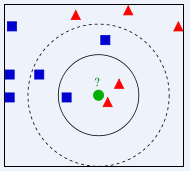
In the picture above, which class should the green circle be assigned to? Is it a red triangle or a blue square? If K=3, since the proportion of the red triangle is 2/3, the green circle will be assigned the class of the red triangle. If K=5, since the proportion of the blue square is 3/5, the green circle will be assigned the class of the blue square. Square type.
The K-Nearest Neighbor (KNN) classification algorithm is a theoretically mature method and one of the simplest machine learning algorithms. The idea of this method is: if a sample belongs to a certain category among the k most similar (that is, the closest in the feature space) samples in the feature space, then the sample also belongs to this category. In the KNN algorithm, the selected neighbors are all correctly classified objects. This method only determines the category of the sample to be classified based on the category of the nearest one or several samples in the classification decision-making. Although the KNN method also relies on the limit theorem in principle, it is only related to a very small number of adjacent samples when making category decisions. Since the KNN method mainly relies on the limited surrounding samples rather than the method of discriminating the class domain to determine the category, the KNN method is more efficient than other methods for the sample set to be divided with a large number of intersections or overlaps in the class domain. for fit.
The KNN algorithm can be used not only for classification, but also for regression. By finding the k nearest neighbors of a sample and assigning the average of the attributes of these neighbors to the sample, the attributes of the sample can be obtained. A more useful method is to give different weights to the influence of neighbors at different distances on the sample. For example, the weight is inversely proportional to the distance.
Use kNN algorithm to predict the gender of Douban movie users
Summary
This article believes that the types of movies preferred by people of different genders will be different, so this experiment was conducted. The 100 movies recently watched by 274 active Douban users were used to make statistics on their types. The obtained 37 movie types were used as attribute features and the user's gender was used as a label to construct a sample set. Use the kNN algorithm to construct a Douban movie user gender classifier, using 90% of the samples as training samples and 10% as test samples, and the accuracy can reach 81.48%.
Experimental data
The data used in this experiment is the movies marked by Douban users, and the 100 movies recently watched by 274 Douban users were selected. Statistics of movie types for each user. There are a total of 37 movie types in the data used in this experiment, so these 37 types are used as attribute features of the user, and the value of each feature is the number of movies of that type among the user's 100 movies. Users are labeled by their gender. Since Douban does not have user gender information, it is all manually labeled.
The data format is as follows:
X1,1,X1,2,X1,3,X1,4……X1,36,X1,37,Y1 X2,1,X2,2,X2,3,X2,4……X2,36,X2,37,Y2 ………… X274,1,X274,2,X274,3,X274,4……X274,36,X274,37,Y274
Example:
0,0,0,3,1,34,5,0,0,0,11,31,0,0,38,40,0,0,15,8,3,9,14,2,3,0,4,1,1,15,0,0,1,13,0,0,1,1 0,1,0,2,2,24,8,0,0,0,10,37,0,0,44,34,0,0,3,0,4,10,15,5,3,0,0,7,2,13,0,0,2,12,0,0,0,0
像这样的数据一共有274行,表示274个样本。每一个的前37个数据是该样本的37个特征值,最后一个数据为标签,即性别:0表示男性,1表示女性。
在此次试验中取样本的前10%作为测试样本,其余作为训练样本。
首先对所有数据归一化。对矩阵中的每一列求取最大值(max_j)、最小值(min_j),对矩阵中的数据X_j,
X_j=(X_j-min_j)/(max_j-min_j) 。
然后对于每一条测试样本,计算其与所有训练样本的欧氏距离。测试样本i与训练样本j之间的距离为:
distance_i_j=sqrt((Xi,1-Xj,1)^2+(Xi,2-Xj,2)^2+……+(Xi,37-Xj,37)^2) ,
对样本i的所有距离从小到大排序,在前k个中选择出现次数最多的标签,即为样本i的预测值。
实验结果
首先选择一个合适的k值。 对于k=1,3,5,7,均使用同一个测试样本和训练样本,测试其正确率,结果如下表所示。
选取不同k值的正确率表
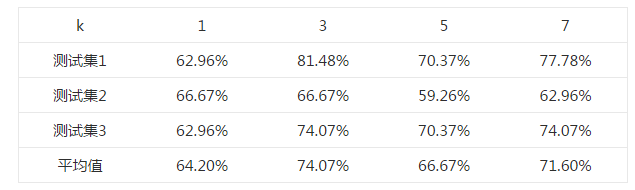
由上述结果可知,在k=3时,测试的平均正确率最高,为74.07%,最高可以达到81.48%。
上述不同的测试集均来自同一样本集中,为随机选取所得。
Python代码
这段代码并非原创,来自《机器学习实战》(Peter Harrington,2013),并有所改动。
#coding:utf-8
from numpy import *
import operator
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = zeros((numberOfLines,37)) #prepare matrix to return
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split(',')
returnMat[index,:] = listFromLine[0:37]
classLabelVector.append(int(listFromLine[-1]))
index += 1
fr.close()
return returnMat,classLabelVector
def genderClassTest():
hoRatio = 0.10 #hold out 10%
datingDataMat,datingLabels = file2matrix('doubanMovieDataSet.txt') #load data setfrom file
normMat,ranges,minVals=autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
testMat=normMat[0:numTestVecs,:]
trainMat=normMat[numTestVecs:m,:]
trainLabels=datingLabels[numTestVecs:m]
k=3
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(testMat[i,:],trainMat,trainLabels,k)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i])
if (classifierResult != datingLabels[i]):
errorCount += 1.0
print "Total errors:%d" %errorCount
print "The total accuracy rate is %f" %(1.0-errorCount/float(numTestVecs))
Related articles
See more- An in-depth analysis of the Bootstrap list group component
- Detailed explanation of JavaScript function currying
- Complete example of JS password generation and strength detection (with demo source code download)
- Angularjs integrates WeChat UI (weui)
- How to quickly switch between Traditional Chinese and Simplified Chinese with JavaScript and the trick for websites to support switching between Simplified and Traditional Chinese_javascript skills