
Home >Web Front-end >JS Tutorial >Automatic acquisition and expiration of cookies through web crawlers (detailed tutorial)
Automatic acquisition and expiration of cookies through web crawlers (detailed tutorial)
- 亚连Original
- 2018-06-01 10:02:097905browse
This article mainly introduces the implementation method of automatic acquisition of cookies and automatic update of expired cookies by web crawlers. Friends in need can refer to the following
This article implements automatic acquisition of cookies and automatic update of cookies when expired.
A lot of information on social networking sites requires logging in to get it. Take Weibo as an example. Without logging in, you can only see the top ten Weibo posts of big Vs. To stay logged in, cookies are required. Take logging in to www.weibo.cn as an example:
Enter in chrome: http://login.weibo.cn/login/
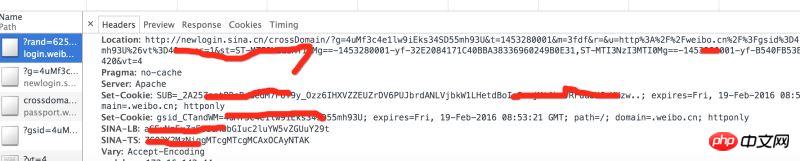
Analysis Control When the header request from the station is returned, you will see several sets of cookies returned by weibo.cn.
Implementation steps:
1, use selenium to automatically log in to obtain cookies, save them to a file;
2, read cookie, compare the validity period of the cookie, and if it expires, perform step 1 again;
3, when requesting other web pages, fill in the cookie to maintain the login status.
1, Get cookies online
Use selenium PhantomJS to simulate browser login and obtain cookies;
There are usually multiple cookies, and the cookies are stored one by one with the .weibo suffix. document.
def get_cookie_from_network():
from selenium import webdriver
url_login = 'http://login.weibo.cn/login/'
driver = webdriver.PhantomJS()
driver.get(url_login)
driver.find_element_by_xpath('//input[@type="text"]').send_keys('your_weibo_accout') # 改成你的微博账号
driver.find_element_by_xpath('//input[@type="password"]').send_keys('your_weibo_password') # 改成你的微博密码
driver.find_element_by_xpath('//input[@type="submit"]').click() # 点击登录
# 获得 cookie信息
cookie_list = driver.get_cookies()
print cookie_list
cookie_dict = {}
for cookie in cookie_list:
#写入文件
f = open(cookie['name']+'.weibo','w')
pickle.dump(cookie, f)
f.close()
if cookie.has_key('name') and cookie.has_key('value'):
cookie_dict[cookie['name']] = cookie['value']
return cookie_dict2, get cookies from files
Traverse files ending with .weibo, that is, cookie files, from the current directory. Use pickle to unpack it into a dict, compare the expiry value with the current time, and return empty if it expires;
def get_cookie_from_cache():
cookie_dict = {}
for parent, dirnames, filenames in os.walk('./'):
for filename in filenames:
if filename.endswith('.weibo'):
print filename
with open(self.dir_temp + filename, 'r') as f:
d = pickle.load(f)
if d.has_key('name') and d.has_key('value') and d.has_key('expiry'):
expiry_date = int(d['expiry'])
if expiry_date > (int)(time.time()):
cookie_dict[d['name']] = d['value']
else:
return {}
return cookie_dict3, if the cached cookie expires, obtain the cookie from the network again
def get_cookie(): cookie_dict = get_cookie_from_cache() if not cookie_dict: cookie_dict = get_cookie_from_network() return cookie_dict
4, Use cookies to request other Weibo homepages
def get_weibo_list(self, user_id):
import requests
from bs4 import BeautifulSoup as bs
cookdic = get_cookie()
url = 'http://weibo.cn/stocknews88'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.57 Safari/537.36'}
timeout = 5
r = requests.get(url, headers=headers, cookies=cookdic,timeout=timeout)
soup = bs(r.text, 'lxml')
...
# 用BeautifulSoup 解析网页
...The above is what I compiled for everyone. I hope it will be helpful to everyone in the future.
Related articles:
How to use v-for in vue to traverse a two-dimensional array
Data of v-for in Vue Grouping instance
vue2.0 computed instance of calculating the accumulated value after list loop
The above is the detailed content of Automatic acquisition and expiration of cookies through web crawlers (detailed tutorial). For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- An in-depth analysis of the Bootstrap list group component
- Detailed explanation of JavaScript function currying
- Complete example of JS password generation and strength detection (with demo source code download)
- Angularjs integrates WeChat UI (weui)
- How to quickly switch between Traditional Chinese and Simplified Chinese with JavaScript and the trick for websites to support switching between Simplified and Traditional Chinese_javascript skills