
Home >Web Front-end >JS Tutorial >Case analysis of node implementation of crawler function
Case analysis of node implementation of crawler function
- php中世界最好的语言Original
- 2018-05-12 15:32:501383browse
This time I will bring you a case analysis of node implementing the crawler function. What are the precautions for node to implement the crawler function. The following is a practical case, let’s take a look.
Node is a server-side language, so you can crawl the website like Python. Let’s use node to crawl the blog park and get all the chapter information.
Step one: Create the crawl file and then npm init.
Second step: Create the crawl.js file. A simple code to crawl the entire page is as follows:
var http = require("http");
var url = "http://www.cnblogs.com";
http.get(url, function (res) {
var html = "";
res.on("data", function (data) {
html += data;
});
res.on("end", function () {
console.log(html);
});
}).on("error", function () {
console.log("获取课程结果错误!");
});
Introduce the http module, and then use http The get request of the object, that is, once it is run, it is equivalent to the node server sending a get request to request this page, and then returning it through res, where the on binding data event is used to continuously receive data, and at the end we print it out in the background .
This is just a part of the entire page. We can inspect the elements on this page and find that they are indeed the same.
We only need to crawl the chapter title and the information of each section. .
The third step: Introduce the cheerio module, as follows: (Just install it in gitbash, cmd always has problems)
cnpm install cheerio --save-dev
The introduction of this module is for It is convenient for us to operate dom, just like jQuery.
Step 4: Operate dom and obtain useful information.
var http = require("http");
var cheerio = require("cheerio");
var url = "http://www.cnblogs.com";
function filterData(html) {
var $ = cheerio.load(html);
var items = $(".post_item");
var result = [];
items.each(function (item) {
var tit = $(this).find(".titlelnk").text();
var aut = $(this).find(".lightblue").text();
var one = {
title: tit,
author: aut
};
result.push(one);
});
return result;
}
function printInfos(allInfos) {
allInfos.forEach(function (item) {
console.log("文章题目 " + item["title"] + '\n' + "文章作者 " + item["author"] + '\n'+ '\n');
});
}
http.get(url, function (res) {
var html = "";
res.on("data", function (data) {
html += data;
});
res.on("end", function (data) {
var allInfos = filterData(html);
printInfos(allInfos);
});
}).on("error", function () {
console.log("爬取博客园首页失败")
});
That is, the above process is crawling the title and author of the blog.
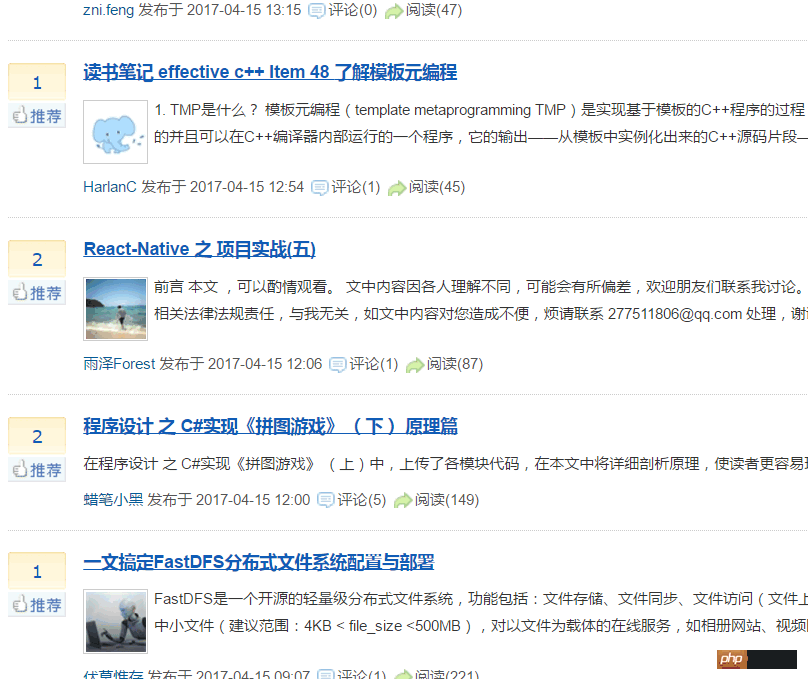
The final background output is as follows:

This is consistent with the content of the blog homepage:
I believe you have mastered the method after reading the case in this article. For more exciting information, please pay attention to other related articles on the php Chinese website!
Recommended reading:
Detailed explanation of Vue.js calculation and use of listener properties
js three calling methods are optimal Summary of shortcomings
The above is the detailed content of Case analysis of node implementation of crawler function. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- An in-depth analysis of the Bootstrap list group component
- Detailed explanation of JavaScript function currying
- Complete example of JS password generation and strength detection (with demo source code download)
- Angularjs integrates WeChat UI (weui)
- How to quickly switch between Traditional Chinese and Simplified Chinese with JavaScript and the trick for websites to support switching between Simplified and Traditional Chinese_javascript skills