
Home >Backend Development >Python Tutorial >Analysis of ideas on how python crawls the permanent links of Sogou WeChat public account articles
Analysis of ideas on how python crawls the permanent links of Sogou WeChat public account articles

- 零到壹度Original
- 2018-04-04 11:51:227942browse
This article mainly introduces the idea analysis of how python crawls the permanent links of Sogou WeChat official account articles. The editor thinks it is quite good. Now I will share it with you and give it to everyone. Let’s all use it as a reference. Let’s follow the editor to have a look.
This article mainly explains the ideas, please solve the code part by yourself
Sogou WeChat search to obtain public accounts and articles
Get the permanent link through the WeChat public platform
python+scrapy framework
mysql database storage + reading public account
Get the information ranking of the day on Sogou WeChat
Specify input Keyword, grab the public account through scrapy
Get the cookie information by logging in to the WeChat public account link
Since the simulated login to the WeChat public platform has not yet been solved, you need to log in manually to obtain the cookie information in real time 

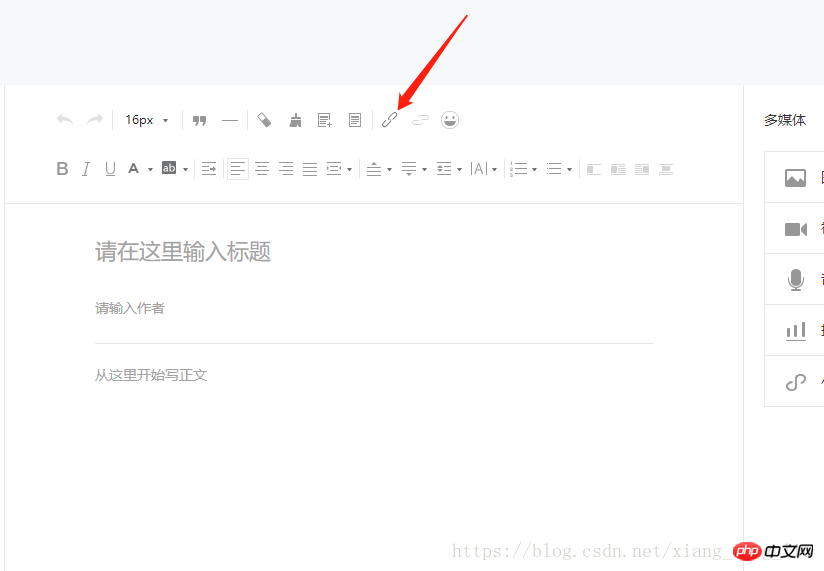
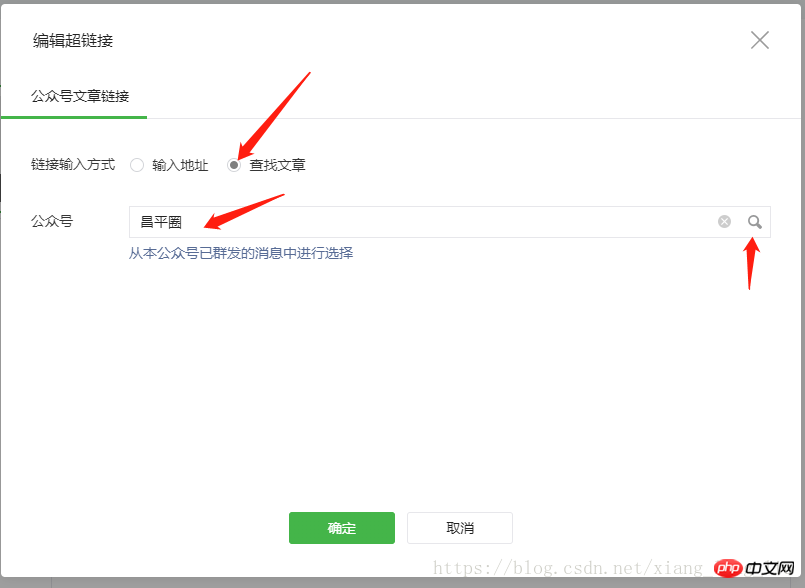
Here you can achieve the transformation permanent link
Code part
def parse(self, response):
item = SougouItem()
item["title"] = response.xpath('//title/text()').extract_first()
print("**"*5, item["title"],"**"*5)
name = input("----------请输入需要搜索的信息:")
print(name)
url = "http://weixin.sogou.com/weixin?query="+name+"&type=2&page=1&ie=utf8"
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name":name})Sogou Access frequency may appear too fast in WeChat, resulting in the need to enter a verification code
def parse_two(self, response):
print(response.url)
name = response.meta["name"]
resp = response.xpath('//ul[@class="news-list"]/li')
s = 1
# 判断url 是否是需要输入验证码
res = re.search("from", response.url) # 需要验证码验证
if res:
print(response.url)
img = response.xpath('//img/@src').extract()
print(img)
url_img = "http://weixin.sogou.com/antispider/"+ img[1]
print(url_img)
url_img = requests.get(url_img).content with open("urli.jpg", "wb") as f:
f.write(url_img) # f.close()
img = input("请输入验证码:")
print(img)
url = response.url
r = re.search(r"from=(.*)",url).group(1)
print(r)
postData = {"c":img,"r":r,"v":"5"}
url = "http://weixin.sogou.com/antispider/thank.php"
yield scrapy.FormRequest(url=url, formdata=postData, callback=self.parse_two,meta={"name":name})
# 不需要验证码验证
else:
for res, i in zip(resp, range(1, 10)):
item = SougouItem()
item["url"] = res.xpath('.//p[1]/a/@href').extract_first()
item["name"] = name
print("第%d条" % i) # 转化永久链接
headers = {"Host": "mp.weixin.qq.com",
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
"Referer": "https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&token=938949250&lang=zh_CN",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": "noticeLoginFlag=1; pgv_pvi=5269297152; pt2gguin=o1349184918; RK=ph4smy/QWu; ptcz=f3eb6ede5db921d0ada7f1713e6d1ca516d200fec57d602e677245490fcb7f1e; pgv_pvid=1033302674; o_cookie=1349184918; pac_uid=1_1349184918; ua_id=4nooSvHNkTOjpIpgAAAAAFX9OSNcLApfsluzwfClLW8=; mm_lang=zh_CN; noticeLoginFlag=1; remember_acct=Liangkai318; rewardsn=; wxtokenkey=777; pgv_si=s1944231936; uuid=700c40c965347f0925a8e8fdcc1e003e; ticket=023fc8861356b01527983c2c4765ef80903bf3d7; ticket_id=gh_6923d82780e4; cert=L_cE4aRdaZeDnzao3xEbMkcP3Kwuejoi; data_bizuin=3075391054; bizuin=3208078327; data_ticket=XrzOnrV9Odc80hJLtk8vFjTLI1vd7kfKJ9u+DzvaeeHxZkMXbv9kcWk/Pmqx/9g7; slave_sid=SWRKNmFyZ1NkM002Rk9NR0RRVGY5VFdMd1lXSkExWGtPcWJaREkzQ1BESEcyQkNLVlQ3YnB4OFNoNmtRZzdFdGpnVGlHak9LMjJ5eXBNVEgxZDlZb1BZMnlfN1hKdnJsV0NKallsQW91Zjk5Y3prVjlQRDNGYUdGUWNFNEd6eTRYT1FSOEQxT0MwR01Ja0Vo; slave_user=gh_6923d82780e4; xid=7b2245140217dbb3c5c0a552d46b9664; openid2ticket_oTr5Ot_B4nrDSj14zUxlXg8yrzws=D/B6//xK73BoO+mKE2EAjdcgIXNPw/b5PEDTDWM6t+4="}
respon = requests.get(url=item["url"]).content
gongzhongh = etree.HTML(respon).xpath('//a[@id="post-user"]/text()')[0]
# times = etree.HTML(respon).xpath('//*[@id="post-date"]/text()')[0]
title_one = etree.HTML(respon).xpath('//*[@id="activity-name"]/text()')[0].split()[0]
print(gongzhongh, title_one)
item["tit"] = title_one
item["gongzhongh"] = gongzhongh
# item["times"] = times
url = "https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&token=938949250&lang=zh_CN&f=json&ajax=1&query=" + gongzhongh + "&begin=0&count=5"
# wenzhang_url = "https://mp.weixin.qq.com/cgi-bin/appmsg?token=610084158&lang=zh_CN&f=json&ajax=1&random=0.7159556076774083&action=list_ex&begin=0&count=5&query=" + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
resp = requests.get(url=url, headers=headers).content
print(resp)
faskeids = json.loads(resp.decode("utf-8"))
try:
list_fask = faskeids["list"] except Exception as f:
print("**********[INFO]:请求失败,登陆失败, 请重新登陆*************")
return
for fask in list_fask:
fakeid = fask["fakeid"]
nickname = fask["nickname"] if nickname == item["gongzhongh"]:
url = "https://mp.weixin.qq.com/cgi-bin/appmsg?token=938949250&f=json&action=list_ex&count=5&query=&fakeid=" + fakeid + "&type=9"
# url = "https://mp.weixin.qq.com/cgi-bin/appmsg?token=1773340085&lang=zh_CN&f=json&ajax=1&action=list_ex&begin=0&count=5&query=" + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
url = "https://mp.weixin.qq.com/cgi-bin/appmsg?token=938949250&f=json&ajax=1&action=list_ex&begin=0&count=5&query=" + item["tit"] +"&fakeid=" + fakeid +"&type=9"
resp = requests.get(url=url, headers=headers).content
app = json.loads(resp.decode("utf-8"))["app_msg_list"]
item["aid"] = app["aid"]
item["appmsgid"] = app["appmsgid"]
item["cover"] = app["cover"]
item["digest"] = app["digest"]
item["url_link"] = app["link"]
item["tit"] = app["title"]
print(item)
time.sleep(10) # time.sleep(5)
# dict_wengzhang = json.loads(resp.decode("utf-8"))
# app_msg_list = dict_wengzhang["app_msg_list"]
# print(len(app_msg_list))
# for app in app_msg_list:
# print(app)
# title = app["title"]
# if title == item["tit"]:
# item["url_link"] = app["link"]
# updata_time = app["update_time"]
# item["times"] = time.strftime("%Y-%m-%d %H:%M:%S", updata_time)
# print("最终链接为:", item["url_link"])
# yield item
# else:
# print(app["title"], item["tit"])
# print("与所选文章不同放弃")
# # item["tit"] = app["title"]
# # item["url_link"] = app["link"]
# # yield item
# else:
# print(nickname, item["gongzhongh"])
# print("与所选公众号不一致放弃")
# time.sleep(100)
# yield item
if response.xpath('//a[@class="np"]'):
s += 1
url = "http://weixin.sogou.com/weixin?query="+name+"&type=2&page="+str(s) # time.sleep(3)
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name": name})The above is the detailed content of Analysis of ideas on how python crawls the permanent links of Sogou WeChat public account articles. For more information, please follow other related articles on the PHP Chinese website!