
Home >Web Front-end >JS Tutorial >Analyze the principles and syntax of JS regex
Analyze the principles and syntax of JS regex
- php中世界最好的语言Original
- 2018-03-29 16:17:431725browse
This time I will bring you the principles and syntax of parsing JS regex. What are the precautions for parsing the principles and syntax of JS regex? The following is a practical case, let's take a look.
Zhengze is like a lighthouse. When you are at a loss in the ocean of strings, it can always give you some ideas; Zhengze is like a currency detector. When you don’t know the user When the banknotes you submit are genuine or fake, it can always help you identify them at a glance; regularity is like a flashlight, when you need to find something, it can always help you get what you want... ——Excerpt from Stinson’s Chinese Parallel Sentence Exercise "Regular"After appreciating a literary excerpt, we will formally sort out the regular rules in JS. The primary purpose of this article is to prevent me from forgetting some regular rules. Usage, so I sorted it out and wrote it down to enhance proficiency and use it as a reference. The main purpose is to share with you. If there are any mistakes, please feel free to enlighten me. Thank you for your kindness. Since this article is titled "One-stop", it must be worthy of the "dragon", so it will include regularity principles, syntax overview, regularity in JS (ES5), ES6 expansion of regularity, and ideas for practicing regularity , I try to explain these things as deeply as possible and in a simple way (as if I can really explain them in a simple way). If you just want to know how to apply it, then read the second, third and fifth parts, which will basically meet your needs. If If you want to master the regular rules in JS, then you’d better follow my ideas, hey hey hey!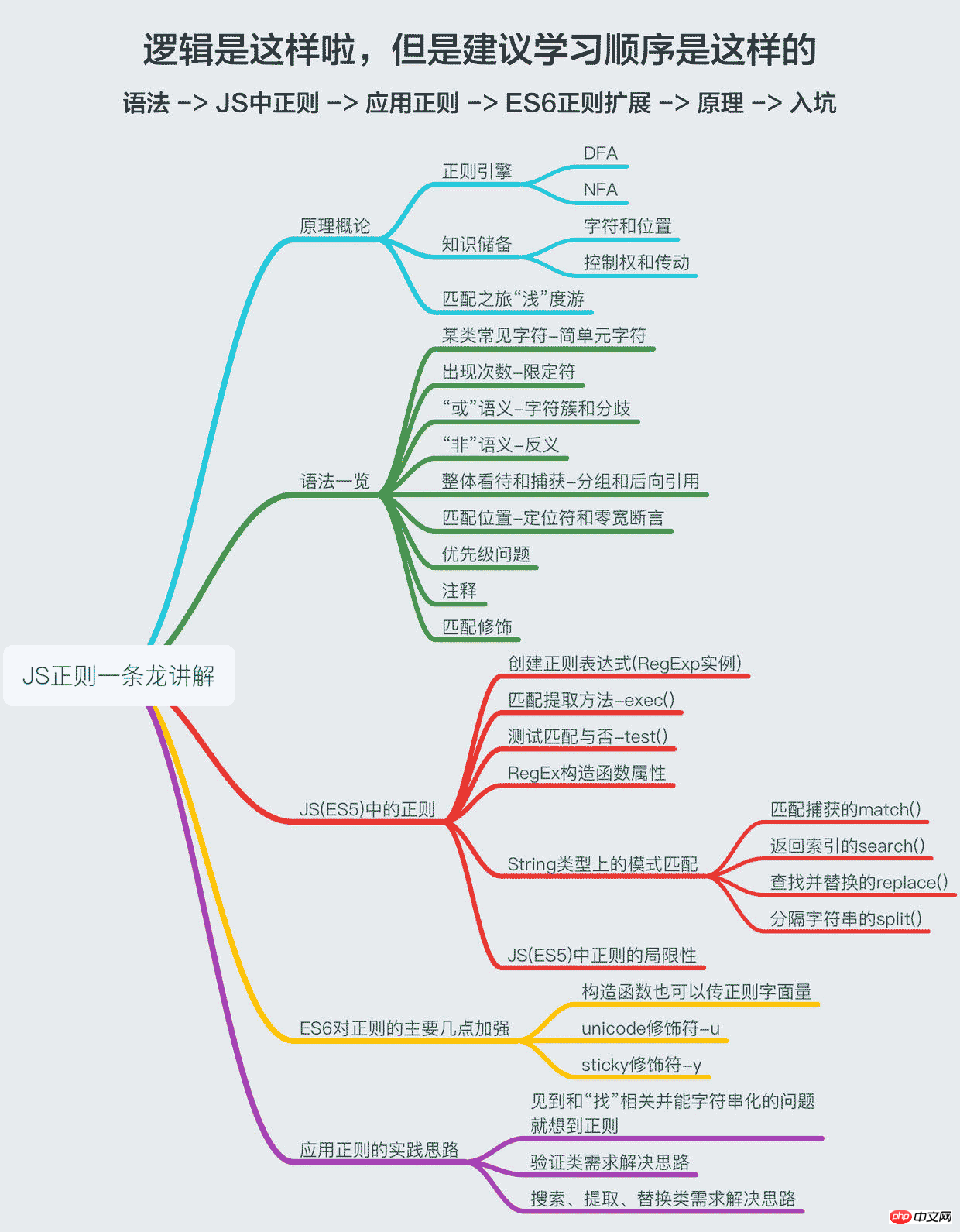
1. Introduction to principles
When I first started using regular expressions, I thought it was amazing how the computer could use a But if you really want to understand regular expressions in principle, then I'm afraid the best way is:1. First, go find a book specifically about regular expressions, O'REILLY's There is one in the "Animal Story" series;
2. Then implement a regular engine yourself.
1. Regularity engineWhy regularity can be effective is because there is an engine. This is the same as why JS can be executed. There is a JS engine. The so-called regularity engine can be understood as
Use an algorithm to simulate a machine based on your regular expression. This machine has many states. By reading the string to be tested, it jumps between these states. If it finally stops in the "terminal state" (Happy Ending), then Say I Do, otherwise Say You Are a Good Man. By converting a regular expression into a machine that can calculate the result in a limited number of steps, an engine is implemented.
Regular engines can be roughly divided into two categories: DFA and NFA 1. DFA (Deterministic finite automaton) deterministic finite automaton
2. NFA (Non -deterministic finite automaton) Non-deterministic finite automaton, most of which are NFA
2. Knowledge reserve
This section is very useful for you to understand regular expressions, especially what a character is and what a position is. 2.1 String in the eyes of regular expression - n characters, n+1 positions
In the above "laughter" string, there are 8 characters in total, which are what you can see, and there are 9 positions, which can only be seen by smart people. Arrived. Why do we need characters and positions? Because the location can be matched.
Then let’s go further to understand “occupied characters” and “zero width”:
If a subregular expression matches characters, not positions, and will be saved in the final result. The subexpression occupies characters. For example, /ha/ (matches ha) occupies characters;
If a subregular match is a position, not a character, or the matched content is not saved in the result (in fact, it can also be regarded as a position), then this subexpression is zero-width, such as /read(?=ing)/ (matches reading, But only put read into the result. The syntax will be described in detail below. This is just an example.), among which (?=ing) is zero-width, and it essentially represents a position.
Occupying characters are mutually exclusive, zero width is non-mutually exclusive. That is to say, one character can only be matched by one subexpression at the same time, but one position can be matched by multiple zero-width subexpressions at the same time. For example, /aa/ cannot match a. The a in this string can only be matched by the first a character of the regular expression, and cannot be matched by the second a at the same time (nonsense); but the position can be multiple For example, /\b\ba/ can match a. Although there are two \b metacharacters indicating the beginning of the word in the regular expression, these two \b can match position 0 at the same time (in this example middle.
Note: We talk about characters and positions for strings, while talking about occupied characters and zero width are for regular expressions.
2.2 Control and transmission
These two words may be encountered when searching for some blog posts or information. Here is an explanation:
Control right refers to which regular subexpression (which may be composed of an ordinary character, metacharacter or metacharacter sequence) matching the string, then where the control right lies.
Transmission refers to a mechanism of the regular engine. The transmission device will locate where in the string the regular match starts.
When a regular expression starts to match, a subexpression usually takes control and tries to match from a certain position in the string. The position where a subexpression starts to try to match is the previous one. A subexpression starts at the end position of a successful match.
To give an example, read(?=ing)ing\sbook matches reading book. We regard this regular expression as five sub-expressions read, (?=ing), ing, \s, book. Of course you You can also think of read as a subexpression of four separate characters, but we treat it this way for convenience here. read starts from position 0 and matches position 4. The following (?=ing) continues to match from position 4. It is found that position 4 is indeed followed by ing, so it is asserted that the match is successful, that is, the entire (?=ing) matches the position. 4 is just a position (you can better understand what zero width is here), and then the following ing starts from position 4 to position 7, then \s matches from position 7 to position 8, and the final book starts from position 8 Matching to position 12, the entire match is completed.
3. A "shallow" tour of the matching journey (can be skipped)
Having said so much, we regard ourselves as a regular engine, step by step in the smallest unit - - "Character" and "position" - Let's take a look at the process of regular matching and give a few examples.
3.1 Basic matching
Regular expression: easy
Source string: So easy
Matching process: First, the regular expression character e takes control, starting from position 0 of the string Matching, when the string character 'S' is encountered, the match fails, and then the regular engine drives forward, starting from position 1. When the string character 'o' is encountered, the match fails, and the transmission continues. The following spaces naturally also fail, so Try to match starting from position 3, successfully match the string character 'e', control is given to the regular expression subexpression (here is also a character) a, try to match from the end position 4 of the last successful match, successfully match the character The string character 'a' is matched until 'y', and then the matching is completed, and the matching result is easy.
3.2 Zero-width matching
正则:^(?=[aeiou])[a-z]+$ 源字符串:apple
First of all, this regular expression: matches such a complete string from beginning to end. This entire string consists only of lowercase letters, and starts with a, e, It starts with any of the five letters i, o, u.
匹配过程:首先正则的^(表示字符串开始的位置)获取控制权,从位置0开始匹配,匹配成功,控制权交给(?=[aeiou]),这个子表达式要求该位置右边必须是元音小写字母中的一个,零宽子表达式相互间不互斥,所以从位置0开始尝试匹配,右侧是字符串的‘a',符合因此匹配成功,所以(?=[aeiou])匹配此处的位置0匹配成功,控制权交给[a-z]+,从位置0开始匹配,字符串‘apple'中的每个字符都匹配成功,匹配到字符串末尾,控制权交回正则的$,尝试匹配字符串结束位置,成功,至此,整个匹配完成。
3.3 贪婪匹配和非贪婪匹配
正则1:{.*}
正则2:{.*?}
源字符串:{233}
这里有两个正则,在限定符(语法会讲什么是限定符)后面加?符号表示忽略优先量词,也就是非贪婪匹配,这个栗子我剥得快一点。
首先开头的{匹配,两个正则都是一样的表现。
正则1的.*为贪婪匹配,所以一直匹配余下字符串'233}',匹配到字符串结束位置,只是每次匹配,都记录一个备选状态,为了以后回溯,每次匹配有两条路,选择了匹配这条路,但记一下这里还可以有不匹配这条路,如果前面死胡同了,可以退回来,此时控制权交还给正则的},去匹配字符串结束位置,失败,于是回溯,意思就是说前面的.*你吃的太多了,吐一个出来,于是控制权回给.*,吐出一个}(其实是用了前面记录的备选状态,尝试不用.*去匹配'}'),控制权再给正则的},这次匹配就成功了。
正则2的.*?为非贪婪匹配,尽可能少地匹配,所以匹配'233}'的每一个字符的时候,都是尝试不匹配,但是一但控制权交还给最后的}就发现出问题了,赶紧回溯乖乖匹配,于是每一个字符都如此,最终匹配成功。
云里雾里?这就对了!可以移步去下面推荐的博客看看:
想详细了解贪婪和非贪婪匹配原理以及获取更多正则相关原理,除了看书之外,推荐去一个CSDN的博客 雁过无痕-博客频道 - CSDN.NET ,讲解得很详细和透彻
二、语法一览
正则的语法相信许多人已经看过deerchao写的30分钟入门教程,我也是从那篇文字中入门的,deerchao从语法逻辑的角度以.NET正则的标准来讲述了正则语法,而我想重新组织一遍,以便于应用的角度、以JS为宿主语言来重新梳理一遍语法,这将便于我们把语言描述翻译成正则表达式。
下面这张一览图(可能需要放大),整理了常用的正则语法,并且将JS不支持的语法特性以红色标注出来了(正文将不会描述这些不支持的特性),语法部分的详细描述也将根据下面的图,从上到下,从左到右的顺序来梳理,尽量不啰嗦。
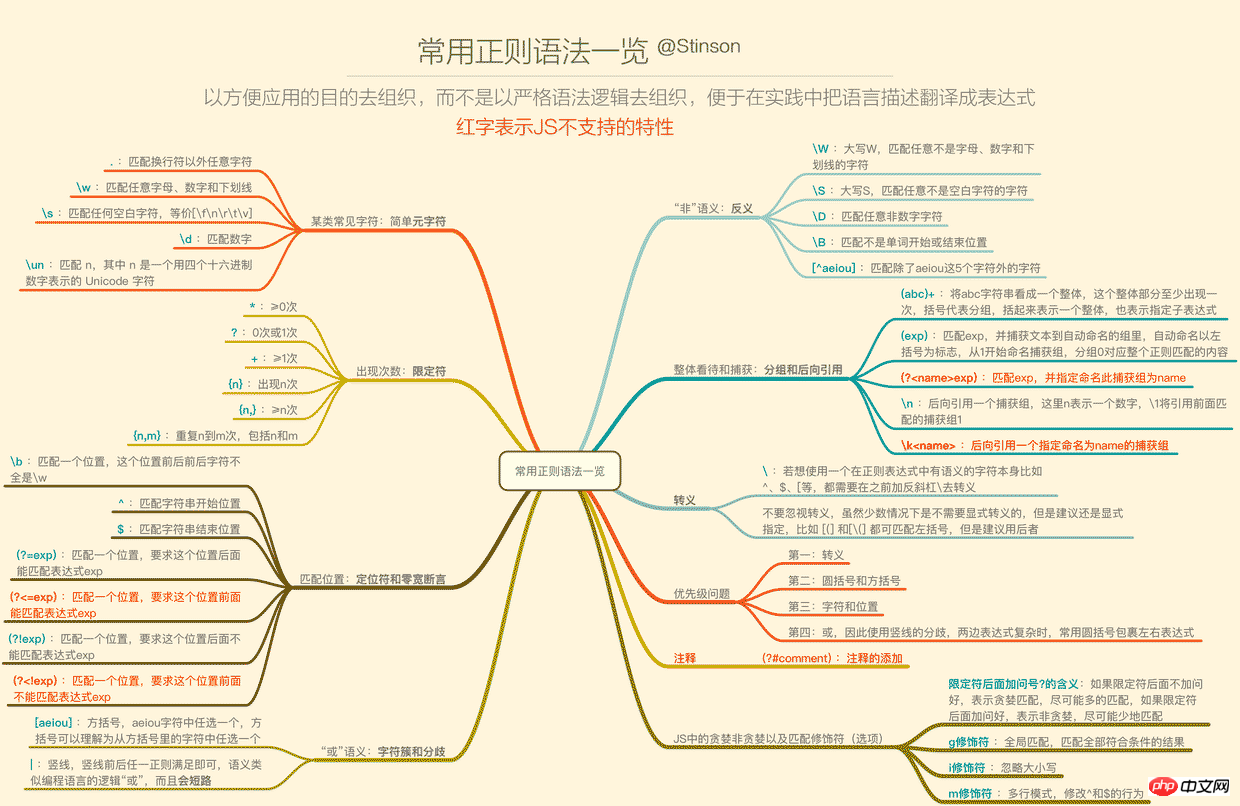
1. 要用某类常见字符——简单元字符
为什么这里要加简单2个字,因为在正则中,\d、\w这样的叫元字符,而{n,m}、(?!exp)这样的也叫元字符,所以元字符是在正则中有特定意义的标识,而这一小节讲的是简单的一些元字符。
.匹配除了换行符以外的任意字符,也即是[^\n],如果要包含任意字符,可使用(.|\n)
\w匹配任意字母、数字或者下划线,等价于[a-zA-Z0-9_],在deerchao的文中还指出可匹配汉字,但是\w在JS中是不能匹配汉字的
\s匹配任意空白符,包含换页符\f、换行符\n、回车符\r、水平制表符\t、垂直制表符\v
\d匹配数字
\un匹配n,这里的n是一个有4个十六进制数字表示的Unicode字符,比如\u597d表示中文字符“好”,那么超过\uffff编号的字符怎么表示呢?ES6的u修饰符会帮你。
2. 要表示出现次数(重复)——限定符
a*表示字符a连续出现次数 >= 0 次
a+表示字符a连续出现次数 >= 1 次
a? means character a appears 0 or 1 times
a{5} means character a appears 5 times in a row
a{5,} means the number of consecutive occurrences of character a >= 5 times
a{5,10} means the number of consecutive occurrences of character a is 5 to 10 Times, including 5 and 10
3. Matching position - locator and zero-width assertion
Expressions matching a certain position are all zero-width, so It mainly contains two parts, one is the locator, which matches a specific position, and the other is the zero-width assertion, which matches a position that must meet a certain requirement.
The following locators are commonly used:
\b matches the word boundary position. The accurate description is that it matches a position, which is not all preceded or followed by \w Characters that can be described, so something like \u597d\babc can match "good abc".
^matches the starting position of the string, which is position 0. If the Multiline property of the RegExp object is set, ^ also matches the position after '\n' or '\r'
$ Matches the end position of the string. If the Multiline property of the RegExp object is set, $ also matches the position before '\n' or '\r'
Zero-width assertions (supported by JS) have the following two:
(?=exp) matches a position, the right side of this position can match the expression exp, pay attention to this expression The formula only matches a position, but it has requirements for the right side of this position, and the things on the right side will not be put into the result. For example, if you use read(?=ing) to match "reading", the result is "read", and "ing" will not be put into the result
(?!exp) matches a position, and the right side of this position cannot match the expression exp
4. Want to express the meaning of "or" - character clusters and differences
We often express the meaning of "or", for example, any one of these characters will do, and another example is to match 5 Numbers or 5 letters will do, etc. The
character cluster can be used to express character-level "or" semantics, which represents any one of the characters in square brackets:
[abc] represents a, b Any one of the three characters , c, if the letters or numbers are consecutive, then they can be represented by -. [b-f] represents any one of the characters from b to f
[(ab)(cd)] will not be used to match the string "ab" or "cd", but to match any of the six characters a, b, c, d, (,) , that is, if you want to express the requirement of "matching the string ab or cd", you cannot do this. You must write ab|cd like this. But here you need to match the parentheses themselves. Logically speaking, you need to escape them with backslashes. However, in square brackets, the parentheses are treated as ordinary characters. Even so, it is still recommended to explicitly escape
Differentiation is used to express the "or" semantics at the expression level, which means that any expression on the left or right can be matched:
ab|cd will match the string " ab" or "cd"
will be short-circuited. Recall the short-circuit of logical OR in Programming Language, so use (ab|abc) to match the string "abc ", the result will be "ab", because the left side of the vertical bar has been satisfied, so the matching result on the left represents the result of the entire regular expression
5. Want to express the meaning of "not" ——Antonym
Sometimes we want to express the requirement "except for certain characters". At this time, we need to use antonym
\W, \D, \S, \B are represented by the metacharacters of uppercase letters, which are the antonyms of the corresponding matching content of lowercase letters. These metacharacters match "characters except letters, numbers, and underscores" and "non-digit characters" in turn. , "non-whitespace character", "non-word boundary position"
[^aeiou] represents any character except a, e, i, o, u, in square brackets And the ^ appearing at the beginning means exclusion. If ^ does not appear at the beginning in square brackets, then it only represents the ^ character itself
6. Overall view and capture - grouping and Backreference
In fact, you have seen parentheses in some places above. Yes, parentheses are used for grouping. What is enclosed in a pair of parentheses is a group. .
上面讲的大部分是针对字符级别的,比如重复字母 “A” 5次,可以用A{5}来表示,但是如果想要字符串“ABC”重复5次呢?这个时候就需要用到括号。
括号的第一个作用,将括起来的分组当做一个整体看待,所以你可以像对待字符重复一样在一个分组后面加限定符,比如(ABC){5}。
分组匹配到的内容也就是这个分组捕获到的内容,从左往右,以左括号为标志,每个分组会自动拥有一个从1开始的编号,编号0的分组对应整个正则表达式,JS不支持捕获组显示命名。
括号的第二个作用,分组捕获到的内容,可以在之后通过\分组编号的形式进行后向引用。比如(ab|cd)123\1可以匹配“ab123ab”或者“cd123cd”,但是不能匹配“ab123cd”或“cd123ab”,这里有一对括号,也是第一对括号,所以编号为捕获组1,然后在正则中通过\1去引用了捕获组1的捕获的内容,这叫后向引用。
括号的第三个作用,改变优先级,比如abc|de和(abc|d)e表达的完全不是一个意思。
7. 转义
任何在正则表达式中有作用的字符都建议转义,哪怕有些情况下不转义也能正确,比如[]中的圆括号、^符号等。
8. 优先级问题
优先级从高到低是:
转义 \
括号(圆括号和方括号)(), (?:), (?=), []
字符和位置
竖线 |
9. 贪婪和非贪婪
在限定符中,除了{n}确切表示重复几次,其余的都是一个有下限的范围。
在默认的模式(贪婪)下,会尽可能多的匹配内容。比如用ab*去匹配字符串“abbb”,结果是“abbb”。
而通过在限定符后面加问号?可以进行非贪婪匹配,会尽可能少地匹配。用ab*?去匹配“abbb”,结果会是“a”。
不带问号的限定符也称匹配优先量词,带问号的限定符也称忽略匹配优先量词。
10. 修饰符(匹配选项)
其实正则的匹配选项有很多可选,不同的宿主语言环境下可能各有不同,此处就JS的修饰符作一个说明:
加g修饰符:表示全局匹配,模式将被应用到所有字符串,而不是在发现第一个匹配项时停止
加i修饰符:表示不区分大小写
加m修饰符:表示多行模式,会改变^和$的行为,上文已述
三、JS(ES5)中的正则
JS中的正则由引用类型RegExp表示,下面主要就RegExp类型的创建、两个主要方法和构造函数属性来展开,然后会提及String类型上的模式匹配,最后会简单罗列JS中正则的一些局限。
1. 创建正则表达式
一种是用字面量的方式创建,一种是用构造函数创建,我们始终建议用前者。
//创建一个正则表达式
var exp = /pattern/flags;
//比如
var pattern=/\b[aeiou][a-z]+\b/gi;
//等价下面的构造函数创建
var pattern=new RegExp("\\b[aeiou][a-z]+\\b","gi");
其中pattern可以是任意的正则表达式,flags部分是修饰符,在上文中已经阐述过了,有 g、i、m 这3个(ES5中)。
现在说一下为什么不要用构造函数,因为用构造函数创建正则,可能会导致对一些字符的双重转义,在上面的例子中,构造函数中第一个参数必须传入字符串(ES6可以传字面量),所以字符\ 会被转义成\,因此字面量的\b会变成字符串中的\\b,这样很容易出错,贼多的反斜杠。
2. RegExp上用来匹配提取的方法——exec()
var matches=pattern.exec(str); 接受一个参数:源字符串 返回:结果数组,在没有匹配项的情况下返回null
结果数组包含两个额外属性,index表示匹配项在字符串中的位置,input表示源字符串,结果数组matches第一项即matches[0]表示匹配整个正则表达式匹配的字符串,matches[n]表示于模式中第n个捕获组匹配的字符串。
要注意的是,第一,exec()永远只返回一个匹配项(指匹配整个正则的),第二,如果设置了g修饰符,每次调用exec()会在字符串中继续查找新匹配项,不设置g修饰符,对一个字符串每次调用exec()永远只返回第一个匹配项。所以如果要匹配一个字符串中的所有需要匹配的地方,那么可以设置g修饰符,然后通过循环不断调用exec方法。
//匹配所有ing结尾的单词
var str="Reading and Writing";
var pattern=/\b([a-zA-Z]+)ing\b/g;
var matches;
while(matches=pattern.exec(str)){
console.log(matches.index +' '+ matches[0] + ' ' + matches[1]);
}
//循环2次输出
//0 Reading Read
//12 Writing Writ
3. RegExp上用来测试匹配成功与否的方法——test()
var result=pattern.test(str);
接受一个参数:源字符串
返回:找到匹配项,返回true,没找到返回false
4. RegExp构造函数属性
RegExp构造函数包含一些属性,适用于作用域中的所有正则表达式,并且基于所执行的最近一次正则表达式操作而变化。
RegExp.input或RegExp["$_"]:最近一次要匹配的字符串
RegExp.lastMatch或RegExp["$&"]:最近一次匹配项
RegExp.lastParen或RegExp["$+"]:最近一次匹配的捕获组
RegExp.leftContext或RegExp["$`"]:input字符串中lastMatch之前的文本
RegExp.rightContext或RegExp["$'"]:input字符串中lastMatch之后的文本
RegExp["$n"]:表示第n个捕获组的内容,n取1-9
5. String类型上的模式匹配方法
上面提到的exec和test都是在RegExp实例上的方法,调用主体是一个正则表达式,而以字符串为主体调用模式匹配也是最为常用的。
5.1 匹配捕获的match方法
在字符串上调用match方法,本质上和在正则上调用exec相同,但是match方法返回的结果数组是没有input和index属性的。
var str="Reading and Writing"; var pattern=/\b([a-zA-Z]+)ing\b/g; //在String上调用match var matches=str.match(pattern); //等价于在RegExp上调用exec var matches=pattern.exec(str);
5.2 返回索引的search方法
接受的参数和match方法相同,要么是一个正则表达式,要么是一个RegExp对象。
//下面两个控制台输出是一样的,都是5 var str="I am reading."; var pattern=/\b([a-zA-Z]+)ing\b/g; var matches=pattern.exec(str); console.log(matches.index); var pos=str.search(pattern); console.log(pos);
5.3 查找并替换的replace方法
var result=str.replace(RegExp or String, String or Function); 第一个参数(查找):RegExp对象或者是一个字符串(这个字符串就被看做一个平凡的字符串) 第二个参数(替换内容):一个字符串或者是一个函数 返回:替换后的结果字符串,不会改变原来的字符串
第一个参数是字符串
只会替换第一个子字符串
第一个参数是正则
指定g修饰符,则会替换所有匹配正则的地方,否则只替换第一处
第二个参数是字符串
可以使用一些特殊的字符序列,将正则表达式操作的值插进入,这是很常用的。
$n:匹配第n个捕获组的内容,n取0-9
$nn:匹配第nn个捕获组内容,nn取01-99
$`:匹配子字符串之后的字符串
$':匹配子字符串之前的字符串
$&:匹配整个模式得字符串
$$:表示$符号本身
第二个参数是一个函数
在只有一个匹配项的情况下,会传递3个参数给这个函数:模式的匹配项、匹配项在字符串中的位置、原始字符串
在有多个捕获组的情况下,传递的参数是模式匹配项、第一个捕获组、第二个、第三个...最后两个参数是模式的匹配项在字符串位置、原始字符串
这个函数要返回一个字符串,表示要替换掉的匹配项
5.4 分隔字符串的split
基于指定的分隔符将一个字符串分割成多个子字符串,将结果放入一个数组,接受的第一个参数可以是RegExp对象或者是一个字符串(不会被转为正则),第二个参数可选指定数组大小,确保数组不会超过既定大小。
6 JS(ES5)中正则的局限
JS(ES5)中不支持以下正则特性(在一览图中也可以看到):
匹配字符串开始和结尾的\A和\Z锚 向后查找(所以不支持零宽度后发断言) 并集和交集类 原子组 Unicode支持(\uFFFF之后的) 命名的捕获组 单行和无间隔模式 条件匹配 注释
四、ES6对正则的主要加强
ES6对正则做了一些加强,这边仅仅简单罗列以下主要的3点,具体可以去看ES6
1. 构造函数可以传正则字面量了
ES5中构造函数是不能接受字面量的正则的,所以会有双重转义,但是ES6是支持的,即便如此,还是建议用字面量创建,简洁高效。
2. u修饰符
加了u修饰符,会正确处理大于\uFFFF的Unicode,意味着4个字节的Unicode字符也可以被支持了。
// \uD83D\uDC2A是一个4字节的UTF-16编码,代表一个字符
/^\uD83D/u.test('\uD83D\uDC2A')
// false,加了u可以正确处理
/^\uD83D/.test('\uD83D\uDC2A')
// true,不加u,当做两个unicode字符处理
加了u修饰符,会改变一些正则的行为:
.原本只能匹配不大于\uFFFF的字符,加了u修饰符可以匹配任何Unicode字符
Unicode字符新表示法\u{码点}必须在加了u修饰符后才是有效的
使用u修饰符后,所有量词都会正确识别码点大于0xFFFF的Unicode字符
使一些反义元字符对于大于\uFFFF的字符也生效
3. y修饰符
y修饰符的作用与g修饰符类似,也是全局匹配,开始从位置0开始,后一次匹配都从上一次匹配成功的下一个位置开始。
不同之处在于,g修饰符只要剩余位置中存在匹配就可,而y修饰符确保匹配必须从剩余的第一个位置开始。
所以/a/y去匹配"ba"会匹配失败,因为y修饰符要求,在剩余位置第一个位置(这里是位置0)开始就要匹配。
ES6对正则的加强,可以看这篇
五、应用正则的实践思路
应用正则,一般是要先想到正则(废话),只要看到和“找”相关的需求并且这个源是可以被字符串化的,就可以想到用正则试试。
一般在应用正则有两类情况,一是验证类问题,另一类是搜索、提取、替换类问题。验证,最常见的如表单验证;搜索,以某些设定的命令加关键词去搜索;提取,从某段文字中提取什么,或者从某个JSON对象中提取什么(因为JSON对象可以字符串化啊);替换,模板引擎中用到。
1. 验证类问题
验证类问题是我们最常遇到的,这个时候其实源字符串长什么样我们是不知道,鬼知道萌萌哒的用户会做出什么邪恶的事情来,推荐的方式是这样的:
首先用白话描述清楚你要怎样的字符串,描述好了之后,就开脑洞地想用户可能输入什么奇怪的东西,就是自己举例,拿一张纸可举一大堆的,有接受的和不接受的(这个是你知道的),这个过程中可能你会去修改之前的描述;
把你的描述拆解开来,翻译成正则表达式;
测试你的正则表达式对你之前举的例子的判断是不是和你预期一致,这里就推荐用在线的JS正则测试去做,不要自己去一遍遍写了。
2. 搜索、提取、替换类问题
这类问题,一般我们是知道源文本的格式或者大致内容的,所以在解决这类问题时一般已经会有一些测试的源数据,我们要从这些源数据中提取出什么、或者替换什么。
找到这些手上的源数据中你需要的部分;
观察这些部分的特征,这些部分本身的特征以及这些部分周围的特征,比如这部分前一个符号一定是一个逗号,后一个符号一定是一个冒号,总之就是找规律;
考察你找的特征,首先能不能确切地标识出你要的部分,不会少也不会多,然后考虑下以后的源数据也是如此么,以后会不会这些特征就没有了;
组织你对要找的这部分的描述,描述清楚经过你考察的特征;
翻译成正则表达式;
测试。
Finally, I have finished writing more than 10,000 words of explanations about JS regularity. After writing it, I found that my proficiency in regularity has taken a step further, so I recommend you to do it frequently, it is very useful, and then Being willing to share is of great benefit to myself and others. Thank you to everyone who can read it.
I believe you have mastered the method after reading the case in this article. For more exciting information, please pay attention to other related articles on the php Chinese website!
Recommended reading:
Detailed explanation of the use of regular non-capturing groups and capturing groups
Matches the bank card number entered by the user Luhn algorithm
The above is the detailed content of Analyze the principles and syntax of JS regex. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- An in-depth analysis of the Bootstrap list group component
- Detailed explanation of JavaScript function currying
- Complete example of JS password generation and strength detection (with demo source code download)
- Angularjs integrates WeChat UI (weui)
- How to quickly switch between Traditional Chinese and Simplified Chinese with JavaScript and the trick for websites to support switching between Simplified and Traditional Chinese_javascript skills