
Home >Web Front-end >JS Tutorial >Node.js, jade generates static html file examples
Node.js, jade generates static html file examples

- 小云云Original
- 2018-05-19 14:52:523823browse
This article mainly brings you an example of Node.js+jade grabbing all blog articles to generate static html files. The editor thinks it is quite good, so I will share it with you now and give it as a reference for everyone. Let’s follow the editor to take a look, I hope it can help everyone.
Project structure:
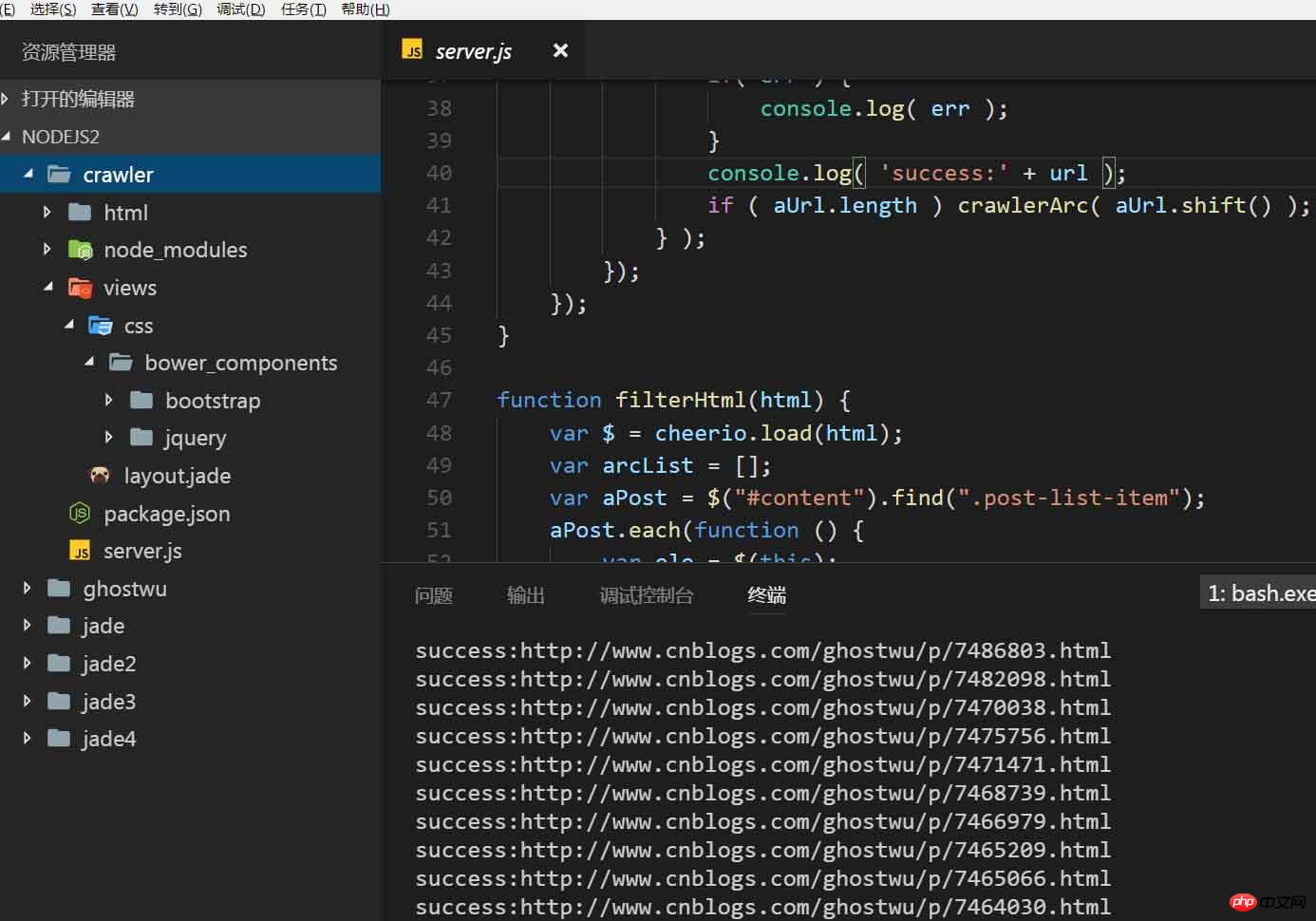
1. How to capture articles?
Very simple, similar to the implementation of grabbing the article list abovefunction crawlerArc( url ){
var html = '';
var str = '';
var arcDetail = {};
http.get(url, function (res) {
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function () {
arcDetail = filterArticle( html );
str = jade.renderFile('./views/layout.jade', arcDetail );
fs.writeFile( './html/' + arcDetail['id'] + '.html', str, function( err ){
if( err ) {
console.log( err );
}
console.log( 'success:' + url );
if ( aUrl.length ) crawlerArc( aUrl.shift() );
} );
});
});
}The parameter url is the address of the article. After crawling the content of the article, call filterArticle (html) Filter out the required article information (id, title, hyperlink, content), and then use jade's renderFile API to replace the template content. After the template content is replaced, it must be generated html file, so use writeFile to write the file. When writing the file, use the id as the html file name. This is the implementation of generating a static html file.
The next step is to generate a static html file in a loop, which is the following line:
if ( aUrl.length ) crawlerArc( aUrl.shift() );
var fs = require( 'fs' );
var http = require( 'http' );
var cheerio = require( 'cheerio' );
var jade = require( 'jade' );
var aList = [];
var aUrl = [];
function filterArticle(html) {
var $ = cheerio.load( html );
var arcDetail = {};
var title = $( "#cb_post_title_url" ).text();
var href = $( "#cb_post_title_url" ).attr( "href" );
var re = /\/(\d+)\.html/;
var id = href.match( re )[1];
var body = $( "#cnblogs_post_body" ).html();
return {
id : id,
title : title,
href : href,
body : body
};
}
function crawlerArc( url ){
var html = '';
var str = '';
var arcDetail = {};
http.get(url, function (res) {
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function () {
arcDetail = filterArticle( html );
str = jade.renderFile('./views/layout.jade', arcDetail );
fs.writeFile( './html/' + arcDetail['id'] + '.html', str, function( err ){
if( err ) {
console.log( err );
}
console.log( 'success:' + url );
if ( aUrl.length ) crawlerArc( aUrl.shift() );
} );
});
});
}
function filterHtml(html) {
var $ = cheerio.load(html);
var arcList = [];
var aPost = $("#content").find(".post-list-item");
aPost.each(function () {
var ele = $(this);
var title = ele.find("h2 a").text();
var url = ele.find("h2 a").attr("href");
ele.find(".c_b_p_desc a").remove();
var entry = ele.find(".c_b_p_desc").text();
ele.find("small a").remove();
var listTime = ele.find("small").text();
var re = /\d{4}-\d{2}-\d{2}\s*\d{2}[:]\d{2}/;
listTime = listTime.match(re)[0];
arcList.push({
title: title,
url: url,
entry: entry,
listTime: listTime
});
});
return arcList;
}
function nextPage( html ){
var $ = cheerio.load(html);
var nextUrl = $("#pager a:last-child").attr('href');
if ( !nextUrl ) return getArcUrl( aList );
var curPage = $("#pager .current").text();
if( !curPage ) curPage = 1;
var nextPage = nextUrl.substring( nextUrl.indexOf( '=' ) + 1 );
if ( curPage < nextPage ) crawler( nextUrl );
}
function crawler(url) {
http.get(url, function (res) {
var html = '';
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function () {
aList.push( filterHtml(html) );
nextPage( html );
});
});
}
function getArcUrl( arcList ){
for( var key in arcList ){
for( var k in arcList[key] ){
aUrl.push( arcList[key][k]['url'] );
}
}
crawlerArc( aUrl.shift() );
}
var url = 'http://www.cnblogs.com/ghostwu/';
crawler( url );layout.jade file:doctype html
html
head
meta(charset='utf-8')
title jade+node.js express
link(rel="stylesheet", href='./css/bower_components/bootstrap/dist/css/bootstrap.min.css')
body
block header
p.container
p.well.well-lg
h3 ghostwu的博客
p js高手之路
block container
p.container
h3
a(href="#{href}" rel="external nofollow" ) !{title}
p !{body}
block footer
p.container
footer 版权所有 - by ghostwu Follow-up plans: 1, use mongodb to store 2, support breakpoint collection 3, collect pictures 4. Collect novels and so on....Related recommendations: About the method of executing php statements on static html files
php Example of the simplest way to generate a static HTML page
Use xmldom to generate a static HTML page on the server side
The above is the detailed content of Node.js, jade generates static html file examples. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- An in-depth analysis of the Bootstrap list group component
- Detailed explanation of JavaScript function currying
- Complete example of JS password generation and strength detection (with demo source code download)
- Angularjs integrates WeChat UI (weui)
- How to quickly switch between Traditional Chinese and Simplified Chinese with JavaScript and the trick for websites to support switching between Simplified and Traditional Chinese_javascript skills