
Home >Backend Development >Python Tutorial >Python: How Pandas operates efficiently
Python: How Pandas operates efficiently
- 巴扎黑Original
- 2017-07-19 13:38:561385browse
This article conducts a comparative test on the operating efficiency of Pandas to explore which methods can make the operating efficiency better.
The test environment is as follows:
windows 7, 64-bit
python 3.5
-
pandas 0.19.2
numpy 1.11.3
- ##jupyter notebook
- Python’s for loop
- Pandas’ Series
- Numpy's ndarray
import pandas as pdimport numpy as np# 100分别用 10,100,...,10,000,000来替换运行list_a = list(range(100))# 200分别用 20,200,...,20,000,000来替换运行list_b = list(range(100,200))
print(len(list_a))
print(len(list_b))
df = pd.DataFrame({'a':list_a, 'b':list_b})
print('数据维度为:{}'.format(df.shape))
print(len(df))
print(df.head())
100 100 数据维度为:(100, 2) 100 a b 0 0 100 1 1 101 2 2 102 3 3 103 4 4 104
- Perform the operation, a*a + b*b
Method 1: for loop
%%timeit# 当DataFrame的行数大于等于1000000时,请用 %%time 命令for i in range(len(df)): df['a'][i]*df['a'][i]+df['b'][i]*df['b'][i]
100 loops, best of 3: 12.8 ms per loop
Method 2: Series
type(df['a'])
pandas.core.series.Series
%%timeit df['a']*df['a']+df['b']*df['b']
The slowest run took 5.41 times longer than the fastest. This could mean that an intermediate result is being cached. 1000 loops, best of 3: 669 µs per loop
Method 3: ndarray
type(df['a'].values)
numpy.ndarray
%%timeit df['a'].values*df['a'].values+df['b'].values*df['b'].values
10000 loops, best of 3: 34.2 µs per loop2 Test resultsThe running results are as follows:
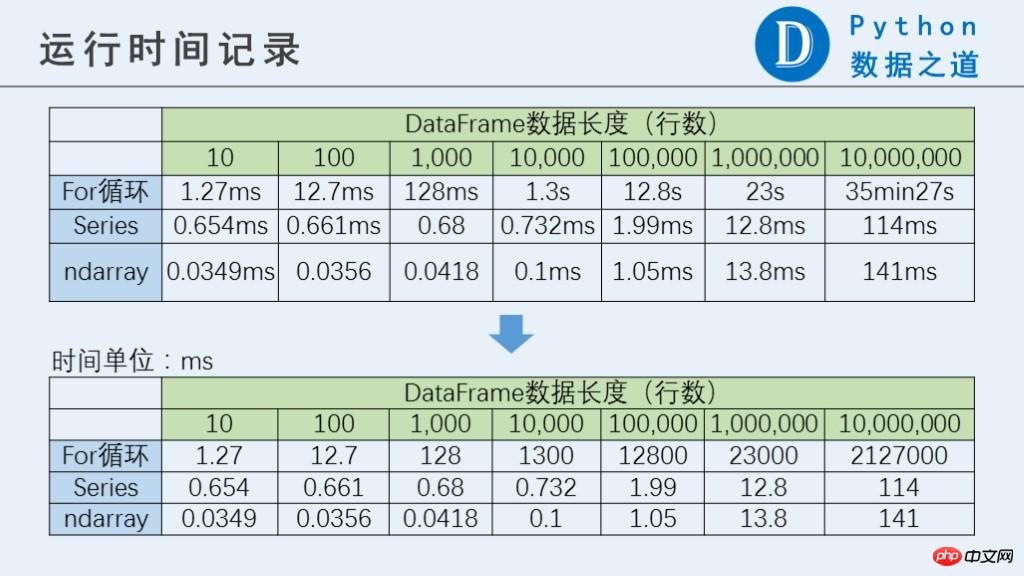
When the amount of data reaches 10 million rows, the performance of the for loop is more than 10,000 times worse. The difference between Series and ndarray is not that big.
PS: When there are 10 million rows, the for loop takes a very long time to run. If you want to test it, you need to pay attention. Please use the%%time command (only test once).
The following chart compares the performance between Series and ndarray.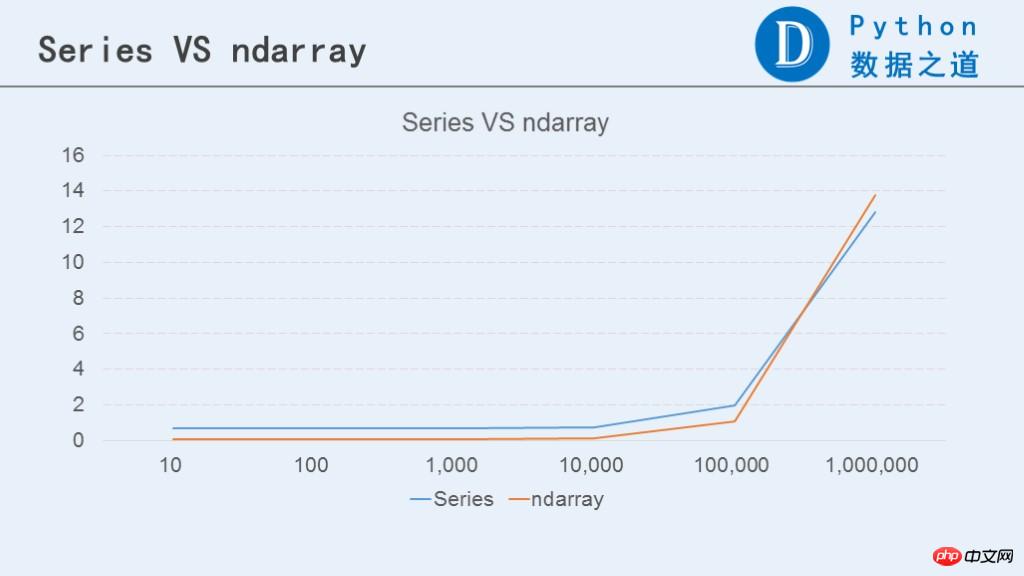
for loops be used if possible. When the number is not particularly large, it is recommended to use ndarray (i.e. df['col'].values) To perform calculations, the operating efficiency is relatively better.
The above is the detailed content of Python: How Pandas operates efficiently. For more information, please follow other related articles on the PHP Chinese website!