
Home >Java >javaTutorial >Detailed explanation of setting Field type instance
Detailed explanation of setting Field type instance

- 零下一度Original
- 2017-06-23 09:37:212549browse
设置Field的类型

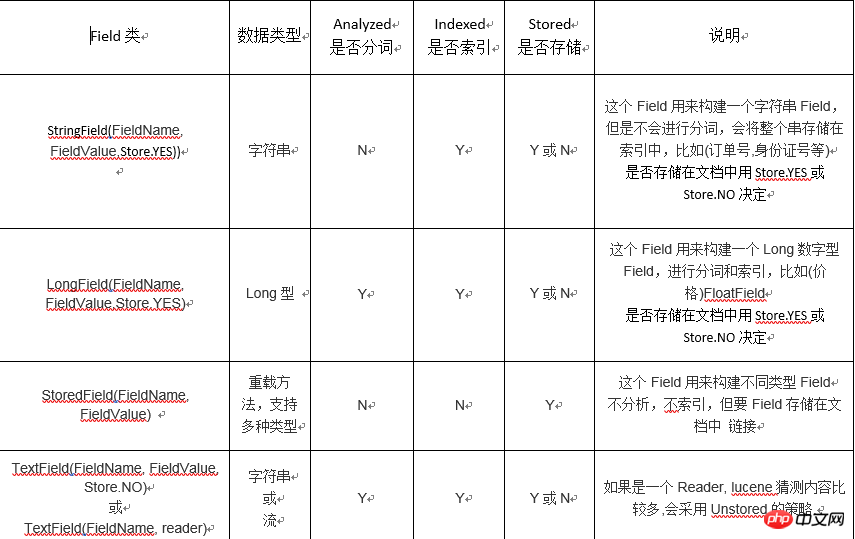
new StringField 不分词(id,身份证号,电话...)
new StoredField 不分词(链接)
new TextField 分词(文本)
new FloadField 不分词(数字,单价)
接着上篇文章 说说Lucene的怎删改查操作
import java.io.File;import java.io.IOException;import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.document.Document;import org.apache.lucene.document.Field.Store;import org.apache.lucene.document.StoredField;import org.apache.lucene.document.StringField;import org.apache.lucene.document.TextField;import org.apache.lucene.index.DirectoryReader;import org.apache.lucene.index.IndexReader;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.index.IndexWriterConfig;import org.apache.lucene.index.IndexableField;import org.apache.lucene.index.Term;import org.apache.lucene.queryparser.classic.MultiFieldQueryParser;import org.apache.lucene.queryparser.classic.QueryParser;import org.apache.lucene.search.BooleanClause.Occur;import org.apache.lucene.search.BooleanQuery;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.NumericRangeQuery;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TermQuery;import org.apache.lucene.search.TopDocs;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.apache.lucene.util.Version;import org.junit.Test;import org.wltea.analyzer.lucene.IKAnalyzer;public class LuceneCRM { /** * 添加
* @throws Exception */@Testpublic void add() throws Exception{//获得文档Document document = new Document();
document.add(new StringField("id", "6", Store.YES));
document.add(new TextField("Name", "柳岩",Store.YES));
document.add(new StoredField("url", "www.baidu.com")); //获得分析器Analyzer analyzer = new IKAnalyzer();// 5. 创建Directory对象,声明索引库存储位置Directory directory = FSDirectory.open(new File("H:\\temp"));// 4. 创建IndexWriterConfig配置信息类IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);// 6. 创建IndexWriter写入对象IndexWriter indexWriter = new IndexWriter(directory, config);
indexWriter.addDocument(document);
indexWriter.close();
} /** * 修改
* 更新索引是先删除再添加,建议对更新需求采用此方法并且要保证对已存在的索引执行更新,
* 可以先查询出来,确定更新记录存在执行更新操作
* 如果更新索引的目标文档对象不存在,则执行添加。
* @throws Exception
*/@Testpublic void update() throws Exception{//获得分析器Analyzer analyzer = new IKAnalyzer();// 创建搜索解析器,第一个参数:默认Field域,第二个参数:分词器QueryParser queryParser = new QueryParser("name",analyzer);// 1. 创建Query搜索对象Query query = queryParser.parse("id:6");
// 5. 创建Directory对象,声明索引库存储位置Directory directory = FSDirectory.open(new File("H:\\temp")); // 3. 创建索引读取对象IndexReaderIndexReader indexReader = DirectoryReader.open(directory); // 4. 创建索引搜索对象IndexSearcherIndexSearcher searcher = new IndexSearcher(indexReader); // 5. 使用索引搜索对象,执行搜索,返回结果集TopDocsTopDocs topDocs = searcher.search(query, 1);
System.out.println("查询到的数据总条数是:" + topDocs.totalHits);
//获得结果集ScoreDoc[] docs = topDocs.scoreDocs;for (ScoreDoc scoreDoc : docs) {//获得文档Document document = searcher.doc(scoreDoc.doc);//如果文档存在就修改if(document!=null){// 4. 创建IndexWriterConfig配置信息类IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);// 6. 创建IndexWriter写入对象IndexWriter indexWriter = new IndexWriter(directory, config);
Document document2 = new Document();//修改document2.add(new TextField("name", "刘亦菲4", Store.YES));
document2.add(new TextField("Name", "柳岩4",Store.YES));/*document2.add(new StringField("id", document.getField("id").stringValue(), Store.YES));
document2.add(new StoredField("url", document.getField("url").stringValue()));*/document2.add(document.getField("id"));
document2.add(document.getField("url"));
indexWriter.updateDocument(new Term("id", "6"), document2);
indexWriter.close();
}
}
indexReader.close();
}
/** * 这个没有先做查询直接修改的
* 符合的doc文档>>这样这里加几个Field,修改的就是Field 其他的Field就不存在了
* (比如原来5个Field)
* @throws Exception */@Testpublic void testIndexUpdate() throws Exception {// 创建分词器Analyzer analyzer = new IKAnalyzer();// 创建Directory流对象Directory directory = FSDirectory.open(new File("H:\\temp"));
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);// 创建写入对象IndexWriter indexWriter = new IndexWriter(directory, config);// 创建DocumentDocument document = new Document();
document.add(new TextField("id", "1003", Store.YES));
document.add(new TextField("Name", "lucene测试test 004", Store.YES));/*document.add(new TextField("desc", "啊哈哈哈哈哈哈哈",Store.YES));*/ //这里修改他会把这条数据给删除了// 执行更新,会把所有符合条件的Document删除,再新增。indexWriter.updateDocument(new Term("id", "1002"), document); //找到Field域为Name的中值为柳岩的所有的文档// 释放资源 indexWriter.close();
}
/** * 删除部分
* @throws Exception
*/@Testpublic void delete() throws Exception{//解析器Analyzer analyzer = new IKAnalyzer();//磁盘位置Directory directory = FSDirectory.open(new File("H:\\temp"));// 4. 创建IndexWriterConfig配置信息类IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);//写入对象IndexWriter indexWriter = new IndexWriter(directory,config );
indexWriter.deleteDocuments(new Term("id","6"));
indexWriter.close();
} /** * 查询 第一种方式
* @throws Exception
*/@Testpublic void find01() throws Exception{
Analyzer analyzer = new IKAnalyzer();
QueryParser parser = new QueryParser("name", analyzer);//parser.parse()Query query = parser.parse("Name:柳岩");
Directory directory = FSDirectory.open(new File("H:\\temp"));
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(reader);
TopDocs topDocs = indexSearcher.search(query, 10);
ScoreDoc[] docs = topDocs.scoreDocs;for (ScoreDoc scoreDoc : docs) {
Document document = indexSearcher.doc(scoreDoc.doc);
System.out.println(document.get("Name"));
}
reader.close();
} /** * 查询 第二种方式
* @throws Exception
*/@Testpublic void find02() throws Exception{
Query query = new TermQuery(new Term("Name","柳岩"));
Directory directory = FSDirectory.open(new File("H:\\temp"));
IndexReader indexReader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
TopDocs topDocs = indexSearcher.search(query, 10);
ScoreDoc[] docs = topDocs.scoreDocs;for (ScoreDoc scoreDoc : docs) {
Document document = indexSearcher.doc(scoreDoc.doc);
System.out.println(document.get("Name"));
}
indexReader.close();
} /** * 查询 第三种方式
* NumericRangeQuery,指定数字范围查询 */@Testpublic void find03() throws Exception{
Query query = NumericRangeQuery.newFloatRange("price",50f, 70f, false, true);//(50f,70f]Directory directory = FSDirectory.open(new File("H:\\temp"));
IndexReader indexReader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
TopDocs topDocs = indexSearcher.search(query, 10);
ScoreDoc[] docs = topDocs.scoreDocs;for (ScoreDoc scoreDoc : docs) {
Document document = indexSearcher.doc(scoreDoc.doc);
System.out.println(document.get("name"));
}
indexReader.close();
} /** * 查询 第四种方式
* BooleanQuery,指定数字范围查询 */@Testpublic void find04() throws Exception{
Query query1 = new TermQuery(new Term("desc","java"));
Query query2 = NumericRangeQuery.newFloatRange("price",50f, 70f, false, true);//(50f,70f]
BooleanQuery booleanQuery = new BooleanQuery();/** * 1、MUST和MUST表示“与”的关系,即“交集”。
2、MUST和MUST_NOT前者包含后者不包含。
3、MUST_NOT和MUST_NOT没意义
4、SHOULD与MUST表示MUST,SHOULD失去意义;
5、SHOULD与MUST_NOT相当于MUST与MUST_NOT。
6、SHOULD与SHOULD表示“或”的关系,即“并集”。 */booleanQuery.add(query1, Occur.MUST);
booleanQuery.add(query2, Occur.MUST);
Directory directory = FSDirectory.open(new File("H:\\temp"));
IndexReader indexReader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
TopDocs topDocs = indexSearcher.search(booleanQuery, 10);
ScoreDoc[] docs = topDocs.scoreDocs;for (ScoreDoc scoreDoc : docs) {
Document document = indexSearcher.doc(scoreDoc.doc);
System.out.println(document.get("name"));
}
indexReader.close();
} /** * 组合查询 */@Testpublic void find05() throws Exception{
Analyzer analyzer = new IKAnalyzer();
QueryParser queryParser = new QueryParser("desc", analyzer);//QueryParser提供一个Parse方法,此方法可以直接根据查询语法来查询//它支持字符串范围。数字范围搜索建议使用NumericRangeQueryQuery query = queryParser.parse("desc:java AND lucene");
Directory directory = FSDirectory.open(new File("H:\\temp"));
IndexReader indexReader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
TopDocs topDocs = indexSearcher.search(query, 10);
ScoreDoc[] docs = topDocs.scoreDocs;for (ScoreDoc scoreDoc : docs) {
Document document = indexSearcher.doc(scoreDoc.doc);
System.out.println(document.get("name"));
}
indexReader.close();
} /** * 通过MultiFieldQueryParse对多个域查询。 */@Testpublic void find06() throws Exception{
Analyzer analyzer = new IKAnalyzer();
MultiFieldQueryParser multiFieldQueryParser = new MultiFieldQueryParser(new String[]{"name","desc"}, analyzer);//通过MultiFieldQueryParse对多个域查询//搜索这两个域中包含lucene域Query query = multiFieldQueryParser.parse("lucene"); //name:lucene desc:luceneDirectory directory = FSDirectory.open(new File("H:\\temp"));
IndexReader indexReader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
TopDocs topDocs = indexSearcher.search(query, 10);
ScoreDoc[] docs = topDocs.scoreDocs;for (ScoreDoc scoreDoc : docs) {
Document document = indexSearcher.doc(scoreDoc.doc);
System.out.println(document.get("name"));
}
indexReader.close();
} /** * 相关度排序(boost是一个加权值(默认加权值为1.0f))
* Lucene对查询关键字和索引文档的相关度进行打分,得分高的就排在前边
* 1)计算出词(Term)的权重
2)根据词的权重值,计算文档相关度得分。
Term Frequency (tf):
指此Term在此文档中出现了多少次。tf 越大说明越重要。
词(Term)在文档中出现的次数越多,说明此词(Term)对该文档越重要,如“Lucene”这个词,
在文档中出现的次数很多,说明该文档主要就是讲Lucene技术的。
Document Frequency (df):
指有多少文档包含此Term。df 越大说明越不重要。
比如,在一篇英语文档中,this出现的次数更多,就说明越重要吗?
不是的,有越多的文档包含此词(Term), 说明此词(Term)太普通,不足以区分这些文档,因而重要性越低。
* @throws Exception
*/@Testpublic void addS() throws Exception{
Analyzer analyzer = new IKAnalyzer();
Directory directory = FSDirectory.open(new File("H:\\temp"));
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);
IndexWriter indexWriter = new IndexWriter(directory, config);
Document document = new Document();
document.add(new StringField("id", "7", Store.YES));
document.add(new TextField("desc", "哈哈哈哈哈哈", Store.YES));
document.add(new TextField("name", "柳岩", Store.YES));//添加权重 TextField field = new TextField("Name", "柳岩", Store.YES); //在做查询柳岩是 这个就排在第一个了 无敌了field.setBoost(100f); //设置权重 document.add(field);
indexWriter.addDocument(document);
indexWriter.close();
}
}说说我对权重的解释,这个经常baidu的人很有感触,一些广告总是出现在最前面,个人觉得就是(你懂得,调整了权重...哈哈)
The above is the detailed content of Detailed explanation of setting Field type instance. For more information, please follow other related articles on the PHP Chinese website!
Statement:
The content of this article is voluntarily contributed by netizens, and the copyright belongs to the original author. This site does not assume corresponding legal responsibility. If you find any content suspected of plagiarism or infringement, please contact admin@php.cn
Previous article:How to start active MQ serviceNext article:How to start active MQ service
Related articles
See more- What impact does concurrent execution of Java functions have on performance? How to manage?
- How is the ecosystem and community support for Java functions? Technology stack considerations
- How to integrate artificial intelligence into mobile and embedded devices using Java functions?
- The role of Java closures in functional and reactive programming
- What are the commonly used exception handling tools in Java function libraries?