


Summarize the method of browser rendering page

Reprinted from web fundamental
Building the object model
The browser needs to build the DOM and CSSOM trees before rendering the page. Therefore, we need to ensure that both HTML and CSS are served to the browser as quickly as possible.
byte → character → tag → node → object model.
HTML markup is converted into the Document Object Model (DOM); CSS markup is converted into the CSS Object Model (CSSOM). DOM and CSSOM are independent data structures.
Chrome DevTools Timeline can capture and inspect the construction and processing overhead of DOM and CSSOM.
Document Object Model (DOM)
<meta><link><title>Critical Path</title> <p>Hello <span>web performance</span> students!</p><div><img src="/static/imghwm/default1.png" data-src="awesome-photo.jpg" class="lazy" alt="Summarize the method of browser rendering page" ></div>
A normal HTML page containing some text and an image, How does the browser handle this page?
The tree output by the HTML parser is composed of DOM elements and attribute nodes. It is an object description of the HTML document and is also the interface between HTML elements and the outside world (such as Javascript). DOM and tags have an almost one-to-one correspondence.

Conversion: The browser reads the raw bytes of HTML from disk or network and encodes them according to the specified encoding of the file ( such as UTF-8) to convert them into individual characters.
##Tokenizing: The browser converts the string into various tokens specified by the W3C HTML5 standard, for example, "" , "", and other strings within angle brackets. Each token has a special meaning and a set of rules.
Lexical analysis: Emitted tokens are converted into "objects" that define their properties and rules.
DOM Build: Finally, since HTML tags define relationships between different tags (some tags are contained within other tags), create The objects are linked within a tree data structure, which also captures the parent-child relationship defined in the original markup: HTML object is the parent of the body object, body is the parent of the paragraph object, and so on.
The final output of the entire process is the Document Object Model (DOM) of the page, and all further processing of the page by the browser Everybody will use it.
Every time the browser processes an HTML tag, it completes all of the above steps: convert bytes into characters, determine tokens, convert tokens into nodes, and then build the DOM tree. This entire process can take some time to complete, especially if you have a lot of HTML to process.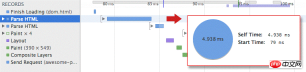
immediately makes a request for the resource and returns the following:
body { font-size: 16px }p { font-weight: bold }span { color: red }p span { display: none }img { float: right }
We could have declared the styles directly within the HTML markup (inline), but having CSS independent of HTML allows us to treat content and design as independent concerns: designers handle CSS, developers focus on HTML, etc.
Just like when dealing with HTML, we need to convert the received CSS rules into something that the browser can understand and process. Therefore, we will repeat the HTML process, but for CSS instead of HTML:

CSS bytes are converted into characters, then into tokens and nodes, and finally linked to a name The tree structure of the CSS Object Model (CSSOM):

Why does CSSOM have a tree structure? When calculating the final set of styles for any node object on the page, the browser starts with the most common rule that applies to the node (for example, if the node is a child of the body element, apply all body styles) and then passes Apply more specific rules to recursively optimize the style of calculations.
Take the above CSSOM tree as an example for a more specific explanation. Any text placed within a span tag within the body element will have a 16 pixel font size and be colored red . The font-size directive cascades down from body to span. However, if a span tag is a child of a paragraph (p) tag, its content will not be displayed.
Also, note that the above tree is not the complete CSSOM tree and only shows the styles we decided to override in our stylesheet. Every browser provides a set of default styles (also called "User Agent styles" "), that is, our styles just override these default styles.
To see how long CSS processing takes, log the timeline in DevTools and look for the "Recalculate Style" event: Unlike DOM parsing, the timeline doesn't show a separate "Parse CSS" entry, and instead captures parsing and CSSOM tree construction, plus the recursive calculation of computed styles under this one event. 8 elements - not much, but still incurs overhead. But where do these 8 elements come from? What ties the DOM and CSSOM together is the render tree.
Rendering tree construction, layout and drawing
completely independent objects
that capture different aspects of the document: one describes the content, and the other describes the style rules that need to be applied to the document. How do we merge the two and let the browser render pixels on the screen?The DOM tree and CSSOM tree are merged to form a rendering tree, which contains only the nodes required to render the web page. Traverse the node nodes in each DOM tree, find the style of the current node in the CSSOM rule tree, and generate a rendering tree.
- Layout calculates the exact position and size of each object.
- The last step is drawing, using the final render tree to render the pixels to the screen.
- The first step is to let the browser merge the DOM and CSSOM into a "rendering tree", covering all
## DOM 
, and all CSSOM style information for each node. In order to build the rendering tree, the browser generally completes the following work:
 Traverse each node starting from the root node of the DOM tree. visible nodes.
Traverse each node starting from the root node of the DOM tree. visible nodes.
- Some nodes that are not visible (such as script tags, meta tags, etc.) are ignored because they are not reflected in the rendered output.
- Some nodes are hidden via CSS and therefore also ignored in the render tree. For example, the "display: none" attribute is set on the span node, so it will not appear in the rendering tree.
遍历每个可见节点,为其找到适配的 CSSOM 规则并应用它们。从选择器的右边往左边开始匹配,也就是从CSSOM树的子节点开始往父节点匹配。
Emit visible nodes with content and their computed styles.
注: visibility: hidden 与 display: none 是不一样的。前者隐藏元素,但元素仍占据着布局空间(即将其渲染成一个空框),而后者 (display: none) 将元素从渲染树中完全移除,元素既不可见,也不是布局的组成部分。
最终输出的渲染同时包含了屏幕上的所有可见内容及其样式信息。有了渲染树,我们就可以进入“布局”阶段。
到目前为止,我们计算了哪些节点应该是可见的以及它们的计算样式,但我们尚未计算它们在设备视口内的确切位置和大小---这就是“布局”阶段,也称为“reflow”。
为弄清每个对象在网页上的确切大小和位置,浏览器从渲染树的根节点开始进行遍历。让我们考虑一个简单的实例:
<meta><title>Critial Path: Hello world!</title> <div> <div>Hello world!</div> </div>
The body of the above web page contains two nested divs: the first (parent) div sets the display size of the node to 50% of the viewport width, and the second div contained in the parent div has a width of 50% of its parent. %, which is 25% of the viewport width.

The output of the layout process is a "box model" that accurately captures the exact position and size of each element within the viewport: all Relative measurements are converted to absolute pixels on the screen.
Finally, now that we know which nodes are visible, their computed styles, and geometry information, we can finally pass this information to the final stage: converting each node in the render tree into an actual on-screen pixels. This step is often called "painting" or "rasterizing."
Chrome DevTools can help us gain insight into how long all three stages above take. Let's take a look at the layout phase of the original "hello world" example:

The "Layout" event captures the render tree construction, position, and size calculation in the Timeline.
When layout is complete, the browser issues "Paint Setup" and "Paint" events, which convert the render tree to pixels on the screen.
Required to perform render tree construction, layout and drawing The time will depend on the size of the document, the styles applied, and the device the document is running on: the larger the document, the more work the browser has to do; the more complex the style, the longer it will take to draw (e.g., drawing a single color The overhead is "smaller", while the calculation and rendering overhead of shadows is "much larger").
Here is a brief overview of the steps completed by the browser:
Process the HTML markup and build the DOM tree.
Process CSS markup and build CSSOM tree.
Merge DOM and CSSOM into a rendering tree.
Layout according to the rendering tree to calculate the geometric information of each node.
Draw each node to the screen.
If the DOM or CSSOM is modified, all the above steps need to be performed again to determine which pixels need to be re-rendered on the screen.
Optimizing the critical rendering path is the process of minimizing the total amount of time spent performing steps 1 through 5 in the above sequence. Doing so renders content to the screen as quickly as possible and also reduces the amount of time between screen updates after the initial render; that is, achieve higher refresh rates for interactive content.
Render-blocking CSS
By default, CSS is Considered as a resource that blocks rendering (but does not block the parsing of html), which means that the browser will not render any processed content until the CSSOM is built . Be sure to minify your CSS, serve it as quickly as possible, and leverage media types and queries to unblock rendering to reduce time above the fold.
In rendering tree construction, both DOM and CSSOM are required to build the rendering tree. This can have a severe impact on performance: both HTML and CSS are rendering-blocking resources. HTML is obviously required because without the DOM, there is nothing to render, but the need for CSS may be less obvious. What happens if you try to render a normal web page without CSS rendering blocking?
By default, CSS is considered a render-blocking resource.
We can mark some CSS resources as non-rendering-blocking through media types and media queries.
The browser will download all CSS resources, whether blocking or not.
Web pages without CSS are virtually unusable. So the browser will block rendering until both the DOM and CSSOM are ready.
CSS is a resource that blocks rendering. It needs to be downloaded to the client as early and as quickly as possible to shorten the first render time.
What if there are some CSS styles that are only used under certain conditions, such as when the web page is displayed or projected onto a large monitor? It would be nice if these resources didn't block rendering.
This kind of situation can be solved through CSS "media type" and "media query":
媒体查询由媒体类型以及零个或多个检查特定媒体特征状况的表达式组成。例如,第一个样式表声明未提供任何媒体类型或查询,因此它适用于所有情况。也就是说它始终会阻塞渲染。第二个样式表则不然,它只在打印内容时适用---或许您想重新安排布局、更改字体等等,因此在网页首次加载时,该样式表不需要阻塞渲染。最后一个样式表声明提供了由浏览器执行的“媒体查询”:符合条件时,样式表会生效,浏览器将阻塞渲染,直至样式表下载并处理完毕。
通过使用媒体查询,我们可以根据特定用例(比如显示或打印),也可以根据动态情况(比如屏幕方向变化、尺寸调整事件等)定制外观。声明样式表时,请密切注意媒体类型和查询,因为它们将严重影响关键渲染路径的性能。
让我们考虑下面这些实例:
第一个声明阻塞渲染,适用于所有情况。
第二个声明同样阻塞渲染:“all”是默认类型,和第一个声明实际上是等效的。
第三个声明具有动态媒体查询,将在网页加载时计算。根据网页加载时设备的方向,portrait.css 可能阻塞渲染,也可能不阻塞渲染。
最后一个声明只在打印网页时应用,因此网页在浏览器中加载时,不会阻塞渲染。
最后,“阻塞渲染”仅是指浏览器是否需要暂停网页的首次渲染,直至该资源准备就绪。无论媒寻是否命中,浏览器都会下载上述所有的CSS样式表,只不过不阻塞渲染的资源对当前媒体不生效罢了。
使用 JavaScript 添加交互
JavaScript 允许我们修改网页的方方面面:内容、样式以及它如何响应用户交互。不过,JavaScript 也会阻止 DOM 构建和延缓网页渲染。为了实现最佳性能,可以让 JavaScript 异步执行,并去除关键渲染路径中任何不必要的 JavaScript。
JavaScript 可以查询和修改 DOM 与 CSSOM。
JavaScript的 执行会阻止 CSSOM的构建,所以和CSSOM的构建是互斥的。
JavaScript blocks DOM construction unless explicitly declared as async.
JavaScript 是一种运行在浏览器中的动态语言,它允许对网页行为的几乎每一个方面进行修改:可以通过在 DOM 树中添加和移除元素来修改内容;可以修改每个元素的 CSSOM 属性;可以处理用户输入等等。为进行说明,让我们用一个简单的内联脚本对之前的“Hello World”示例进行扩展:
<meta><link><title>Critical Path: Script</title><style> body { font-size: 16px };p { font-weight: bold };
span { color: red };p span { display: none };
img { float: right }</style>
<p>Hello <span>web performance</span> students!</p><div><img src="/static/imghwm/default1.png" data-src="awesome-photo.jpg" class="lazy" alt="Summarize the method of browser rendering page" ></div><script> var span = document.getElementsByTagName('span')[0];
span.textContent = 'interactive'; // change DOM text content span.style.display = 'inline'; // change CSSOM property // create a new element, style it, and append it to the DOM var loadTime = document.createElement('div');
loadTime.textContent = 'You loaded this page on: ' + new Date();
loadTime.style.color = 'blue';
document.body.appendChild(loadTime);</script>
JavaScript 允许我们进入 DOM 并获取对隐藏的 span 节点的引用 -- 该节点可能未出现在渲染树中,却仍然存在于 DOM 内。然后,在获得引用后,就可以更改其文本,并将 display 样式属性从“none”替换为“inline”。现在,页面显示“Hello interactive students!”。
JavaScript 还允许我们在 DOM 中创建、样式化、追加和移除新元素。从技术上讲,整个页面可以是一个大的 JavaScript 文件,此文件逐一创建元素并对其进行样式化。但是在实践中,使用 HTML 和 CSS 要简单得多。
尽管 JavaScript 为我们带来了许多功能,不过也在页面渲染方式和时间方面施加了更多限制。
首先,请注意上例中的内联脚本靠近网页底部。为什么呢?如果我们将脚本移至 span元素前面,就会脚本运行失败,并提示在文档中找不到对任何span 元素的引用 -- 即 getElementsByTagName(‘span') 会返回 null。这透露出一个重要事实:脚本在文档的何处插入,就在何处执行。当 HTML 解析器遇到一个 script 标记时,它会暂停构建 DOM,将控制权移交给 JavaScript 引擎;等 JavaScript 引擎运行完毕,浏览器会从中断的地方恢复 DOM 构建。
换言之,我们的脚本块在运行时找不到网页中任何靠后的元素,因为它们尚未被处理!或者说:执行内联脚本会阻止 DOM 构建,也就延缓了首次渲染。
在网页中引入脚本的另一个微妙事实是,它们不仅可以读取和修改 DOM 属性,还可以读取和修改 CSSOM 属性。实际上,示例中就是这么做的:将 span 元素的 display 属性从 none 更改为 inline。最终结果如何?我们现在遇到了race condition(资源竞争)。
如果浏览器尚未完成 CSSOM 的下载和构建,而却想在此时运行脚本,会怎样?答案很简单,对性能不利:浏览器将延迟脚本执行和 DOM 构建,直至其完成 CSSOM 的下载和构建。
简言之,JavaScript 在 DOM、CSSOM 和 JavaScript 执行之间引入了大量新的依赖关系,从而可能导致浏览器在处理以及在屏幕上渲染网页时出现大幅延迟:
脚本在文档中的位置很重要。
当浏览器遇到一个 script 标记时,DOM 构建将暂停,直至脚本完成执行。
JavaScript 可以查询和修改 DOM 与 CSSOM。
JavaScript 执行将暂停,直至 CSSOM 就绪。即CSSDOM构建的优先级更高。
“优化关键渲染路径”在很大程度上是指了解和优化 HTML、CSS 和 JavaScript 之间的依赖关系谱。
解析器阻塞与异步 JavaScript
默认情况下,JavaScript 执行会“阻塞解析器”:当浏览器遇到文档中的脚本时,它必须暂停 DOM 构建,将控制权移交给 JavaScript 运行时,让脚本执行完毕,然后再继续构建 DOM。实际上,内联脚本始终会阻止解析器,除非编写额外代码来推迟它们的执行。
通过 script 标签引入的脚本又怎样:
<meta><link><title>Critical Path: Script External</title> <p>Hello <span>web performance</span> students!</p><div><img src="/static/imghwm/default1.png" data-src="awesome-photo.jpg" class="lazy" alt="Summarize the method of browser rendering page" ></div><script></script>
app.js
var span = document.getElementsByTagName('span')[0];
span.textContent = 'interactive'; // change DOM text contentspan.style.display = 'inline'; // change CSSOM property// create a new element, style it, and append it to the DOMvar loadTime = document.createElement('div');
loadTime.textContent = 'You loaded this page on: ' + new Date();
loadTime.style.color = 'blue';
document.body.appendChild(loadTime);无论我们使用 <script> 标记还是内联 JavaScript 代码段,两者能够以相同方式工作。 <strong>在两种情况下,浏览器都会先暂停并执行脚本,然后才会处理剩余文档。如果是外部<strong> JavaScript <strong>文件,浏览器必须停下来,等待从磁盘、缓存或远程服务器获取脚本,这就可能给关键渲染路径增加更长的延迟。</script>
默认情况下,所有 JavaScript 都会阻止解析器。由于浏览器不了解脚本计划在页面上执行什么操作,它会作最坏的假设并阻止解析器。向浏览器传递脚本不需要在引用位置执行的信号既可以让浏览器继续构建 DOM,也能够让脚本在就绪后执行。为此,我们可以将脚本标记为异步:
<meta> <link> <title>Critical Path: Script Async</title> <p>Hello <span>web performance</span> students!</p> <div><img src="/static/imghwm/default1.png" data-src="awesome-photo.jpg" class="lazy" alt="Summarize the method of browser rendering page" ></div> <script></script>
向 script 标记添加异步关键字可以指示浏览器在等待脚本可用期间(仅指下载期间,因为所有脚本的执行都会阻塞解析器)不阻止 DOM 构建,这样可以显著提升性能。
分析关键渲染路径性能
发现和解决关键渲染路径性能瓶颈需要充分了解常见的陷阱。让我们踏上实践之旅,找出常见的性能模式,从而帮助您优化网页。
优化关键渲染路径能够让浏览器尽可能快地绘制网页:更快的网页渲染速度可以提高吸引力、增加网页浏览量以及提高转化率。为了最大程度减少访客看到空白屏幕的时间,我们需要优化加载的资源及其加载顺序。
为帮助说明这一流程,让我们先从可能的最简单情况入手,逐步构建我们的网页,使其包含更多资源、样式和应用逻辑。在此过程中,我们还会对每一种情况进行优化,以及了解可能出错的环节。
到目前为止,我们只关注了资源(CSS、JS 或 HTML 文件)可供处理后浏览器中会发生的情况,而忽略了从缓存或从网络获取资源所需的时间。我们作以下假设:
到服务器的网络往返(传播延迟时间)需要 100 毫秒。
HTML 文档的服务器响应时间为 100 毫秒,所有其他文件的服务器响应时间均为 10 毫秒。
Hello World 体验
<meta><title>Critical Path: No Style</title> <p>Hello <span>web performance</span> students!</p><div><img src="/static/imghwm/default1.png" data-src="awesome-photo.jpg" class="lazy" alt="Summarize the method of browser rendering page" ></div>
我们将从基本 HTML 标记和单个图像(无 CSS 或 JavaScript)开始。让我们在 Chrome DevTools 中打开 Network 时间线并检查生成的资源瀑布:

正如预期的一样,HTML 文件下载花费了大约 200 毫秒。请注意,蓝线的透明部分表示浏览器在网络上等待(即尚未收到任何响应字节)的时间,而不透明部分表示的是收到第一批响应字节后完成下载的时间。HTML 下载量很小 (
当 HTML 内容可用后,浏览器会解析字节,将它们转换成tokens,然后构建 DOM 树。请注意,为方便起见,DevTools 会在底部记录 DOMContentLoaded 事件的时间(216 毫秒),该时间同样与蓝色垂直线相符。HTML 下载结束与蓝色垂直线 (DOMContentLoaded) 之间的间隔是浏览器构建 DOM 树所花费的时间 — 在本例中仅为几毫秒。
请注意,我们的“趣照”并未阻止 domContentLoaded 事件。这证明,我们构建渲染树甚至绘制网页时无需等待页面上的每个静态资源:并非所有资源都对快速提供首次绘制具有关键作用。事实上,当我们谈论关键渲染路径时,通常谈论的是 HTML 标记、CSS 和 JavaScript。图像不会阻止页面的首次渲染,不过,我们当然也应该尽力确保系统尽快绘制图像!
That said, the load event (also known as onload), is blocked on the image: DevTools reports the onload event at 335ms. Recall that the onload event marks the point at which all resources that the page requires have been downloaded and processed; at this point (the red vertical line in the waterfall), the loading spinner can stop spinning in the browser.
结合使用 JavaScript 和 CSS
“Hello World experience”页面虽然看起来简单,但背后却需要做很多工作。在实践中,我们还需要 HTML 之外的其他资源:我们可能需要 CSS 样式表以及一个或多个用于为网页增加一定交互性的脚本。让我们将两者结合使用,看看效果如何:
<title>Critical Path: Measure Script</title><meta><link> <p>Hello <span>web performance</span> students!</p><div><img src="/static/imghwm/default1.png" data-src="awesome-photo.jpg" class="lazy" alt="Summarize the method of browser rendering page" ></div><script></script>
添加 JavaScript 和 CSS 之前:

添加 JavaScript 和 CSS 之后:

添加外部 CSS 和 JavaScript 文件将额外增加两个瀑布请求,浏览器差不多会同时发出这两个请求。不过,请注意,现在 domContentLoaded 事件与 onload 事件之间的时间差小多了。这是怎么回事?
与纯 HTML 示例不同,我们还需要获取并解析 CSS 文件才能构建 CSSOM,要想构建渲染树,DOM 和 CSSOM 缺一不可。
由于网页上还有一个阻塞解析器的JavaScript 文件,系统会在下载并解析 CSS 文件之前阻止 domContentLoaded事件:因为 JavaScript 可能会查询 CSSOM,必须在下载 CSS 文件之后才能执行 JavaScript。
如果我们用内联脚本替换外部脚本会怎样?即使直接将脚本内联到网页中,浏览器仍然无法在构建 CSSOM 之前执行脚本。简言之,内联 JavaScript 也会阻止解析器。
不过,尽管内联脚本会阻止 CSS,但这样做是否能加快页面渲染速度呢?让我们尝试一下,看看会发生什么。
外部 JavaScript:

内联 JavaScript:

我们减少了一个请求,但 onload 和 domContentLoaded 时间实际上没有变化。为什么呢?怎么说呢,我们知道,这与 JavaScript 是内联的还是外部的并无关系,因为只要浏览器遇到 script 标记,就会进行阻止,并等到之前的css文件的 CSSOM 构建完毕。此外,在我们的第一个示例中,浏览器是并行下载 CSS 和 JavaScript,并且差不多是同时完成。在此实例中,内联 JavaScript 代码并无多大意义。但是,我们可以通过多种策略加快网页的渲染速度。
首先回想一下,所有内联脚本都会阻止解析器,但对于外部脚本,可以添加“async”关键字来解除对解析器的阻止。让我们撤消内联,尝试一下这种方法:
<title>Critical Path: Measure Async</title><meta><link> <p>Hello <span>web performance</span> students!</p><div><img src="/static/imghwm/default1.png" data-src="awesome-photo.jpg" class="lazy" alt="Summarize the method of browser rendering page" ></div><script></script>
阻止解析器的(外部)JavaScript:

异步(外部)JavaScript:

效果好多了!解析 HTML 之后不久即会触发 domContentLoaded 事件;浏览器已得知不要阻止 JavaScript,并且由于没有其他阻止解析器的脚本,CSSOM 构建也可并行进行了。
或者,我们也可以同时内联 CSS 和 JavaScript:
<title>Critical Path: Measure Inlined</title><meta><style> p { font-weight: bold } span { color: red } p span { display: none } img { float: right }</style>
<p>Hello <span>web performance</span> students!</p><div><img src="/static/imghwm/default1.png" data-src="awesome-photo.jpg" class="lazy" alt="Summarize the method of browser rendering page" ></div><script> var span = document.getElementsByTagName('span')[0];
span.textContent = 'interactive'; // change DOM text content span.style.display = 'inline'; // change CSSOM property // create a new element, style it, and append it to the DOM var loadTime = document.createElement('div');
loadTime.textContent = 'You loaded this page on: ' + new Date();
loadTime.style.color = 'blue';
document.body.appendChild(loadTime);</script>

请注意,domContentLoaded 时间与前一示例中的时间实际上相同;只不过没有将 JavaScript 标记为异步,而是同时将 CSS 和 JS 内联到网页本身。这会使 HTML 页面显著增大,但好处是浏览器无需等待获取任何外部资源,网页已经内置了所有资源。
即便是非常简单的网页,优化关键渲染路径也并非轻而易举:需要了解不同资源之间的依赖关系图,需要确定哪些资源是“关键资源”,还必须在不同策略中做出选择,找到在网页上加入这些资源的恰当方式。这一问题不是一个解决方案能够解决的,每个页面都不尽相同。您需要遵循相似的流程,自行找到最佳策略。
不过,我们可以回过头来,看看能否找出某些常规性能模式。
性能模式
最简单的网页只包括 HTML 标记;没有 CSS,没有 JavaScript,也没有其他类型的资源。要渲染此类网页,浏览器需要发起请求,等待 HTML 文档到达,对其进行解析,构建 DOM,最后将其渲染在屏幕上:
<meta><title>Critical Path: No Style</title> <p>Hello <span>web performance</span> students!</p><div><img src="/static/imghwm/default1.png" data-src="awesome-photo.jpg" class="lazy" alt="Summarize the method of browser rendering page" ></div>

T0 与 T1 之间的时间捕获的是网络和服务器处理时间。在最理想的情况下(如果 HTML 文件较小),我们只需一次网络往返便可获取整个文档。由于 TCP 传输协议工作方式的缘故,较大文件可能需要更多次的往返。因此,在最理想的情况下,上述网页具有单次往返(最少)关键渲染路径。
现在,我们还以同一网页为例,但这次使用外部 CSS 文件:
<meta><link> <p>Hello <span>web performance</span> students!</p><div><img src="/static/imghwm/default1.png" data-src="awesome-photo.jpg" class="lazy" alt="Summarize the method of browser rendering page" ></div>

我们同样需要一次网络往返来获取 HTML 文档,然后检索到的标记告诉我们还需要 CSS 文件;这意味着,浏览器需要返回服务器并获取 CSS,然后才能在屏幕上渲染网页。因此,这个页面至少需要两次往返才能显示出来。CSS 文件同样可能需要多次往返,因此重点在于“最少”。
让我们定义一下用来描述关键渲染路径的词汇:
关键资源: 可能阻止网页首次渲染的资源。
关键路径长度: 获取所有关键资源所需的往返次数或总时间。
关键字节: 实现网页首次渲染所需的总字节数,它是所有关键资源传送文件大小的总和。我们包含单个 HTML 页面的第一个示例包含一项关键资源(HTML 文档);关键路径长度也与 1 次网络往返相等(假设文件较小),而总关键字节数正好是 HTML 文档本身的传送大小。
现在,让我们将其与上面 HTML + CSS 示例的关键路径特性对比一下:

2 项关键资源
2 次或更多次往返的最短关键路径长度
9 KB 的关键字节
我们同时需要 HTML 和 CSS 来构建渲染树。所以,HTML 和 CSS 都是关键资源:CSS 仅在浏览器获取 HTML 文档后才会获取,因此关键路径长度至少为两次往返。两项资源相加共计 9KB 的关键字节。
现在,让我们向组合内额外添加一个 JavaScript 文件。
<meta><link> <p>Hello <span>web performance</span> students!</p><div><img src="/static/imghwm/default1.png" data-src="awesome-photo.jpg" class="lazy" alt="Summarize the method of browser rendering page" ></div><script></script>
我们添加了 app.js,它既是网页上的外部 JavaScript 静态资源,又是一种解析器阻止(即关键)资源。更糟糕的是,为了执行 JavaScript 文件,我们还需要进行阻塞并等待 CSSOM;因为JavaScript 可以查询 CSSOM,因此在下载 style.css 并构建 CSSOM 之前,浏览器将会暂停解析。

即便如此,如果我们实际查看一下该网页的“网络瀑布”,就会注意到 CSS 和 JavaScript 请求差不多是同时发起的;浏览器获取 HTML,发现两项资源并发起两个请求。因此,上述网页具有以下关键路径特性:
3 项关键资源
2 次或更多次往返的最短关键路径长度
11 KB 的关键字节
现在,我们拥有了三项关键资源,关键字节总计达 11 KB,但我们的关键路径长度仍是两次往返,因为我们可以同时传送 CSS 和 JavaScript。了解关键渲染路径的特性意味着能够确定哪些是关键资源,此外还能了解浏览器如何安排资源的获取时间。让我们继续探讨示例。
在与网站开发者交流后,我们意识到我们在网页上加入的 JavaScript 不必具有阻塞作用:网页中的一些分析代码和其他代码不需要阻止网页的渲染。了解了这一点,我们就可以向 script 标记添加“async”属性来解除对解析器的阻止:
<meta><link> <p>Hello <span>web performance</span> students!</p><div><img src="/static/imghwm/default1.png" data-src="awesome-photo.jpg" class="lazy" alt="Summarize the method of browser rendering page" ></div><script></script>

异步脚本具有以下几个优点:
脚本不再阻止解析器,也不再是关键渲染路径的组成部分。
由于没有其他关键脚本,CSS 也不需要阻止 domContentLoaded 事件。
domContentLoaded 事件触发得越早,其他应用逻辑开始执行的时间就越早。
因此,我们优化过的网页现在恢复到了具有两项关键资源(HTML 和 CSS),最短关键路径长度为两次往返,总关键字节数为 9 KB。
最后,如果 CSS 样式表只需用于打印,那会如何呢?
<meta><link> <p>Hello <span>web performance</span> students!</p><div><img src="/static/imghwm/default1.png" data-src="awesome-photo.jpg" class="lazy" alt="Summarize the method of browser rendering page" ></div><script></script>

Because the style.css resource is only used for printing, the browser does not have to block it to render the web page. So, once the DOM is constructed, the browser has enough information to render the web page. Therefore, the page has only one critical resource (the HTML document), and the shortest critical rendering path length is one round trip.
Summary:
By default, CSS is treated as a render blocking resource, which means that the browser won't render any processed content until the CSSOM is constructed. Both html and css are blocking Rendering resources, so the DOM and CSSDOM must be built as soon as possible to display the first screen as quickly as possible. But CSS parsing and HTML parsing can be done in parallel.
When the HTML parser encounters a script tag, it will pause building the DOM, download the js file (from external/inline/cache), and then transfer control to the JavaScript engine (if at this time If the script references subsequent elements, a reference error will occur); when the JavaScript engine is finished running, the browser will resume DOM construction from where it was interrupted. That is, if the page has a script tag, the DOMContentLoaded event needs to wait for the JS to be executed before being triggered. However, the script can be marked as asynchronous, which will not block the construction of the DOM during the download of the js file.
defer and async both download js files asynchronously, but there are differences:
The defer attribute is only supported by IE. The scripts for this attribute are executed after the page is parsed, and the delayed scripts are not necessarily in order. implement.
The async js will be executed immediately after downloading (so the order in which the scripts are executed is not the order in which the scripts are in the code. It is possible that the scripts that appear later will be loaded first and executed first).
Asynchronous resources do not block the parser, allowing the browser to avoid being blocked in the construction of CSSOM before executing the script. In general, if the script can use the async attribute, meaning it is not required for the first render, consider loading the script asynchronously after the first render.
Race Condition
What if the browser hasn't finished downloading and building the CSSOM when we want to run our script? The answer is simple and not very good for performance: the browser delays script execution and DOM construction until it has finished downloading and constructing the CSSOM. That is, the JS in the script tag needs to wait for the CSS in front of it to be loaded before execution.
How does the HTML parser build the DOM tree? There is a one-to-one correspondence between the DOM tree and the html tag. When parsing the html from top to bottom, the DOM will be constructed while parsing. If an external resource (link or script) is encountered, the external resource will be loaded. When the external resource is js, HTML parsing will be paused and will continue until js is loaded and executed. When the external resource is css, it will not affect html parsing, but will affect first-screen rendering.
domContentLoaded:Triggered when the initial HTML document has been loaded and parsed into a DOM tree. It will not wait for CSS files, images, and iframes to be loaded.
load:When all resources (including images,) that the page requires have been downloaded and processed. Resources obtained dynamically have nothing to do with the load event.
The above is the detailed content of Summarize the method of browser rendering page. For more information, please follow other related articles on the PHP Chinese website!

 From Websites to Apps: The Diverse Applications of JavaScriptApr 22, 2025 am 12:02 AM
From Websites to Apps: The Diverse Applications of JavaScriptApr 22, 2025 am 12:02 AMJavaScript is widely used in websites, mobile applications, desktop applications and server-side programming. 1) In website development, JavaScript operates DOM together with HTML and CSS to achieve dynamic effects and supports frameworks such as jQuery and React. 2) Through ReactNative and Ionic, JavaScript is used to develop cross-platform mobile applications. 3) The Electron framework enables JavaScript to build desktop applications. 4) Node.js allows JavaScript to run on the server side and supports high concurrent requests.
 Python vs. JavaScript: Use Cases and Applications ComparedApr 21, 2025 am 12:01 AM
Python vs. JavaScript: Use Cases and Applications ComparedApr 21, 2025 am 12:01 AMPython is more suitable for data science and automation, while JavaScript is more suitable for front-end and full-stack development. 1. Python performs well in data science and machine learning, using libraries such as NumPy and Pandas for data processing and modeling. 2. Python is concise and efficient in automation and scripting. 3. JavaScript is indispensable in front-end development and is used to build dynamic web pages and single-page applications. 4. JavaScript plays a role in back-end development through Node.js and supports full-stack development.
 The Role of C/C in JavaScript Interpreters and CompilersApr 20, 2025 am 12:01 AM
The Role of C/C in JavaScript Interpreters and CompilersApr 20, 2025 am 12:01 AMC and C play a vital role in the JavaScript engine, mainly used to implement interpreters and JIT compilers. 1) C is used to parse JavaScript source code and generate an abstract syntax tree. 2) C is responsible for generating and executing bytecode. 3) C implements the JIT compiler, optimizes and compiles hot-spot code at runtime, and significantly improves the execution efficiency of JavaScript.
 JavaScript in Action: Real-World Examples and ProjectsApr 19, 2025 am 12:13 AM
JavaScript in Action: Real-World Examples and ProjectsApr 19, 2025 am 12:13 AMJavaScript's application in the real world includes front-end and back-end development. 1) Display front-end applications by building a TODO list application, involving DOM operations and event processing. 2) Build RESTfulAPI through Node.js and Express to demonstrate back-end applications.
 JavaScript and the Web: Core Functionality and Use CasesApr 18, 2025 am 12:19 AM
JavaScript and the Web: Core Functionality and Use CasesApr 18, 2025 am 12:19 AMThe main uses of JavaScript in web development include client interaction, form verification and asynchronous communication. 1) Dynamic content update and user interaction through DOM operations; 2) Client verification is carried out before the user submits data to improve the user experience; 3) Refreshless communication with the server is achieved through AJAX technology.
 Understanding the JavaScript Engine: Implementation DetailsApr 17, 2025 am 12:05 AM
Understanding the JavaScript Engine: Implementation DetailsApr 17, 2025 am 12:05 AMUnderstanding how JavaScript engine works internally is important to developers because it helps write more efficient code and understand performance bottlenecks and optimization strategies. 1) The engine's workflow includes three stages: parsing, compiling and execution; 2) During the execution process, the engine will perform dynamic optimization, such as inline cache and hidden classes; 3) Best practices include avoiding global variables, optimizing loops, using const and lets, and avoiding excessive use of closures.
 Python vs. JavaScript: The Learning Curve and Ease of UseApr 16, 2025 am 12:12 AM
Python vs. JavaScript: The Learning Curve and Ease of UseApr 16, 2025 am 12:12 AMPython is more suitable for beginners, with a smooth learning curve and concise syntax; JavaScript is suitable for front-end development, with a steep learning curve and flexible syntax. 1. Python syntax is intuitive and suitable for data science and back-end development. 2. JavaScript is flexible and widely used in front-end and server-side programming.
 Python vs. JavaScript: Community, Libraries, and ResourcesApr 15, 2025 am 12:16 AM
Python vs. JavaScript: Community, Libraries, and ResourcesApr 15, 2025 am 12:16 AMPython and JavaScript have their own advantages and disadvantages in terms of community, libraries and resources. 1) The Python community is friendly and suitable for beginners, but the front-end development resources are not as rich as JavaScript. 2) Python is powerful in data science and machine learning libraries, while JavaScript is better in front-end development libraries and frameworks. 3) Both have rich learning resources, but Python is suitable for starting with official documents, while JavaScript is better with MDNWebDocs. The choice should be based on project needs and personal interests.


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

Dreamweaver Mac version
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

WebStorm Mac version
Useful JavaScript development tools

