
 Web Front-endJS TutorialDetailed explanation of how to use Node.js to segment text content and extract keywords
Web Front-endJS TutorialDetailed explanation of how to use Node.js to segment text content and extract keywordsDetailed explanation of how to use Node.js to segment text content and extract keywords

This article mainly introduces the use of Node.js to segment text content and extract keywords. Friends who need it can refer to
before discussing technology. Let’s be cute first, you don’t understand the world of foodies~~
Zhongcheng translated articles have tags, users can quickly filter articles of interest based on tags, and the articles are also Relevant recommendations can be made based on tag associations. But now Zhongcheng Translation’s tags are set when recommending articles, and they are all in English, and manual settings are inevitably not standardized and complete. Although articles can be manually edited after publishing, we cannot expect users or administrators to edit appropriate tags all the time, so we need to use tools to automatically generate tags.
Among the current open source word segmentation tools, jieba is a word segmentation component with powerful functions and excellent performance. Fortunately, it has a node version.
nodejieba's installation and use are very simple:
npm install nodejieba
var nodejieba = require("nodejieba");
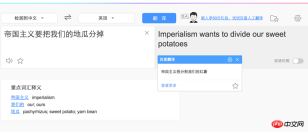
var result = nodejieba.cut("帝国主义要把我们的地瓜分掉");
console.log(result);
//[ '帝国主义', '要', '把', '我们', '的', '地', '瓜分', '掉' ]
result = nodejieba.cut('土地,俺老孙的金箍棒在哪里?');
console.log(result);
//[ '土地', ',', '俺', '老', '孙', '的', '金箍棒', '在', '哪里', '?' ]
result = nodejieba.cut('大圣,您的金箍棒就棒在特别配您的头型!');
console.log(result);
//[ '大圣',',','您','的','金箍棒','就','棒','在','特别','配','您','的','头型','!' ]We can load our own dictionary and set the weight and part of speech for each word in the dictionary:
Edit user.uft8
Sweet Potato 9999 n
Golden Hoop 9999 n
stick is great in 9999
Then load the dictionary through nodejieba.load.
var nodejieba = require("nodejieba");
nodejieba.load({
userDict: './user.utf8',
});
var result = nodejieba.cut("帝国主义要把我们的地瓜分掉");
console.log(result);
//[ '帝国主义', '要', '把', '我们', '的', '地瓜', '分', '掉' ]
result = nodejieba.cut('土地,俺老孙的金箍棒在哪里?');
console.log(result);
//[ '土地', ',', '俺', '老', '孙', '的', '金箍棒', '在', '哪里', '?' ]
result = nodejieba.cut('大圣,您的金箍棒就棒在特别配您的头型!');
console.log(result);
//[ '大圣', ',', '您', '的', '金箍', '棒就棒在', '特别', '配', '您', '的', '头型', '!' ]In addition to word segmentation, we can use nodejieba to extract keywords:
const content = `
HTTP, HTTP/2 and Performance optimization
The purpose of this article is Through comparison, I will tell you why you should migrate from HTTP to HTTPS and why support for HTTP/2 should be added. Before comparing HTTP and HTTP/2, let’s first look at what HTTP is.
What is HTTP
HTTP is a set of rules for communication on the World Wide Web. HTTP is an application layer protocol and runs on top of the TCP/IP layer. When a user requests a web page through a browser, HTTP is responsible for processing the request and establishing a connection between the web server and the client.
With HTTP/2, performance can be improved without using sprite images, compression, or splicing. However, this does not mean that these techniques should not be used. But this has clearly demonstrated the necessity for us to move from HTTP/1.1 to HTTP/2.
`;
const nodejieba = require("nodejieba");
const result = nodejieba.extract(content, 20);
console.log(result);The output result is similar to the following:
[ { word: 'HTTP', weight: 140.8704516850025 },
{ word: '请求', weight: 14.23018001394 },
{ word: '应该', weight: 14.052171126120001 },
{ word: '万维网', weight: 12.2912397395 },
{ word: 'TCP', weight: 11.739204307083542 },
{ word: '1.1', weight: 11.739204307083542 },
{ word: 'Web', weight: 11.739204307083542 },
{ word: '雪碧图', weight: 11.739204307083542 },
{ word: 'HTTPS', weight: 11.739204307083542 },
{ word: 'IP', weight: 11.739204307083542 },
{ word: '应用层', weight: 11.2616203224 },
{ word: '客户端', weight: 11.1926274509 },
{ word: '浏览器', weight: 10.8561552143 },
{ word: '拼接', weight: 9.85762638414 },
{ word: '比较', weight: 9.5435285574 },
{ word: '网页', weight: 9.53122979951 },
{ word: '服务器', weight: 9.41204128224 },
{ word: '使用', weight: 9.03259988558 },
{ word: '必要性', weight: 8.81927328699 },
{ word: '添加', weight: 8.0484751722 } ]We add some new keywords to the dictionary:
Performance
HTTP/2
The output results are as follows:
[ { word: 'HTTP', weight: 105.65283876375187 },
{ word: 'HTTP/2', weight: 58.69602153541771 },
{ word: '请求', weight: 14.23018001394 },
{ word: '应该', weight: 14.052171126120001 },
{ word: '性能', weight: 12.61259281884 },
{ word: '万维网', weight: 12.2912397395 },
{ word: 'IP', weight: 11.739204307083542 },
{ word: 'HTTPS', weight: 11.739204307083542 },
{ word: '1.1', weight: 11.739204307083542 },
{ word: 'TCP', weight: 11.739204307083542 },
{ word: 'Web', weight: 11.739204307083542 },
{ word: '雪碧图', weight: 11.739204307083542 },
{ word: '应用层', weight: 11.2616203224 },
{ word: '客户端', weight: 11.1926274509 },
{ word: '浏览器', weight: 10.8561552143 },
{ word: '拼接', weight: 9.85762638414 },
{ word: '比较', weight: 9.5435285574 },
{ word: '网页', weight: 9.53122979951 },
{ word: '服务器', weight: 9.41204128224 },
{ word: '使用', weight: 9.03259988558 } ]On this basis, we use the whitelist method to filter out some words that can be used as tags:
const content = `
HTTP, HTTP/2 and performance optimization
The purpose of this article is to tell you through comparison why you should migrate from HTTP to HTTPS, and why support for HTTP/2 should be added. Before comparing HTTP and HTTP/2, let’s first look at what HTTP is.
What is HTTP
HTTP is a set of rules for communication on the World Wide Web. HTTP is an application layer protocol that runs on top of the TCP/IP layer. When a user requests a web page through a browser, HTTP is responsible for processing the request and establishing a connection between the web server and the client.
With HTTP/2, performance can be improved without using sprite images, compression, or splicing. However, this does not mean that these techniques should not be used. But this has clearly demonstrated the necessity for us to move from HTTP/1.1 to HTTP/2.
`;
const nodejieba = require("nodejieba");
nodejieba.load({
userDict: './user.utf8',
});
const result = nodejieba.extract(content, 20);
const tagList = ['HTTPS', 'HTTP', 'HTTP/2', 'Web', '浏览器', '性能'];
console.log(result.filter(item => tagList.indexOf(item.word) >= 0));Finally we get:
[ { word: 'HTTP', weight: 105.65283876375187 },
{ word: 'HTTP/2', weight: 58.69602153541771 },
{ word: '性能', weight: 12.61259281884 },
{ word: 'HTTPS', weight: 11.739204307083542 },
{ word: 'Web', weight: 11.739204307083542 },
{ word: '浏览器', weight: 10.8561552143 } ]This is the result we want.
The above is the basic method of using the word segmentation library nodejieba. In the future, we can use it to automatically analyze and add corresponding tags to the translations published by Zhongcheng Translation, so as to provide translators and readers with a better user experience.
The above is the detailed content of Detailed explanation of how to use Node.js to segment text content and extract keywords. For more information, please follow other related articles on the PHP Chinese website!

 From Websites to Apps: The Diverse Applications of JavaScriptApr 22, 2025 am 12:02 AM
From Websites to Apps: The Diverse Applications of JavaScriptApr 22, 2025 am 12:02 AMJavaScript is widely used in websites, mobile applications, desktop applications and server-side programming. 1) In website development, JavaScript operates DOM together with HTML and CSS to achieve dynamic effects and supports frameworks such as jQuery and React. 2) Through ReactNative and Ionic, JavaScript is used to develop cross-platform mobile applications. 3) The Electron framework enables JavaScript to build desktop applications. 4) Node.js allows JavaScript to run on the server side and supports high concurrent requests.
 Python vs. JavaScript: Use Cases and Applications ComparedApr 21, 2025 am 12:01 AM
Python vs. JavaScript: Use Cases and Applications ComparedApr 21, 2025 am 12:01 AMPython is more suitable for data science and automation, while JavaScript is more suitable for front-end and full-stack development. 1. Python performs well in data science and machine learning, using libraries such as NumPy and Pandas for data processing and modeling. 2. Python is concise and efficient in automation and scripting. 3. JavaScript is indispensable in front-end development and is used to build dynamic web pages and single-page applications. 4. JavaScript plays a role in back-end development through Node.js and supports full-stack development.
 The Role of C/C in JavaScript Interpreters and CompilersApr 20, 2025 am 12:01 AM
The Role of C/C in JavaScript Interpreters and CompilersApr 20, 2025 am 12:01 AMC and C play a vital role in the JavaScript engine, mainly used to implement interpreters and JIT compilers. 1) C is used to parse JavaScript source code and generate an abstract syntax tree. 2) C is responsible for generating and executing bytecode. 3) C implements the JIT compiler, optimizes and compiles hot-spot code at runtime, and significantly improves the execution efficiency of JavaScript.
 JavaScript in Action: Real-World Examples and ProjectsApr 19, 2025 am 12:13 AM
JavaScript in Action: Real-World Examples and ProjectsApr 19, 2025 am 12:13 AMJavaScript's application in the real world includes front-end and back-end development. 1) Display front-end applications by building a TODO list application, involving DOM operations and event processing. 2) Build RESTfulAPI through Node.js and Express to demonstrate back-end applications.
 JavaScript and the Web: Core Functionality and Use CasesApr 18, 2025 am 12:19 AM
JavaScript and the Web: Core Functionality and Use CasesApr 18, 2025 am 12:19 AMThe main uses of JavaScript in web development include client interaction, form verification and asynchronous communication. 1) Dynamic content update and user interaction through DOM operations; 2) Client verification is carried out before the user submits data to improve the user experience; 3) Refreshless communication with the server is achieved through AJAX technology.
 Understanding the JavaScript Engine: Implementation DetailsApr 17, 2025 am 12:05 AM
Understanding the JavaScript Engine: Implementation DetailsApr 17, 2025 am 12:05 AMUnderstanding how JavaScript engine works internally is important to developers because it helps write more efficient code and understand performance bottlenecks and optimization strategies. 1) The engine's workflow includes three stages: parsing, compiling and execution; 2) During the execution process, the engine will perform dynamic optimization, such as inline cache and hidden classes; 3) Best practices include avoiding global variables, optimizing loops, using const and lets, and avoiding excessive use of closures.
 Python vs. JavaScript: The Learning Curve and Ease of UseApr 16, 2025 am 12:12 AM
Python vs. JavaScript: The Learning Curve and Ease of UseApr 16, 2025 am 12:12 AMPython is more suitable for beginners, with a smooth learning curve and concise syntax; JavaScript is suitable for front-end development, with a steep learning curve and flexible syntax. 1. Python syntax is intuitive and suitable for data science and back-end development. 2. JavaScript is flexible and widely used in front-end and server-side programming.
 Python vs. JavaScript: Community, Libraries, and ResourcesApr 15, 2025 am 12:16 AM
Python vs. JavaScript: Community, Libraries, and ResourcesApr 15, 2025 am 12:16 AMPython and JavaScript have their own advantages and disadvantages in terms of community, libraries and resources. 1) The Python community is friendly and suitable for beginners, but the front-end development resources are not as rich as JavaScript. 2) Python is powerful in data science and machine learning libraries, while JavaScript is better in front-end development libraries and frameworks. 3) Both have rich learning resources, but Python is suitable for starting with official documents, while JavaScript is better with MDNWebDocs. The choice should be based on project needs and personal interests.


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

Dreamweaver Mac version
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

WebStorm Mac version
Useful JavaScript development tools

