
Home >Backend Development >Python Tutorial >Dynamic diagram explanation of commonly used sorting algorithms
Dynamic diagram explanation of commonly used sorting algorithms

- Y2JOriginal
- 2017-04-25 10:55:524094browse
This article mainly uses several commonly used sorting algorithms that are visually intuitive and has certain reference value. Interested friends can refer to
to intuitively experience several commonly used sorting algorithms. The specific content is as follows
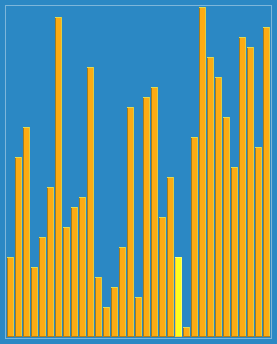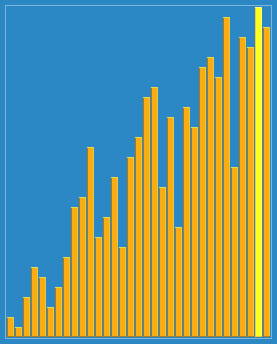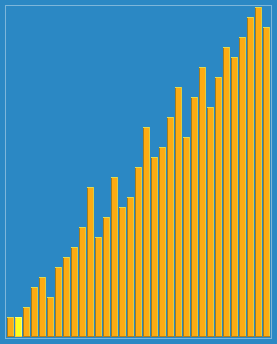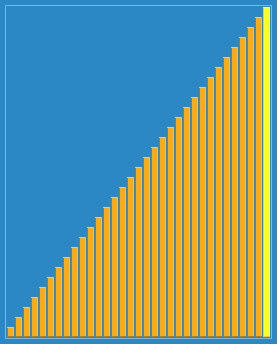
1 Quick sort
Introduction:
Quick sort is a sort developed by Tony Hall algorithm. On average, sorting n items requires O(n log n) comparisons. In the worst case, O(n2) comparisons are required, but this situation is uncommon. In fact, quicksort is often significantly faster than other Ο(n log n) algorithms because its inner loop can be implemented efficiently on most architectures and works well on most real-world applications. Data can determine design choices, reducing the possibility of quadratic terms in time required.
Steps:
Pick out an element from the sequence, called "pivot",
Reorder the sequence, and place all elements smaller than the pivot value in front of the pivot , all elements larger than the base value are placed behind the base (the same number can go to either side). After this partition exits, the base is in the middle of the sequence. This is called a partition operation.
Recursively sort the subarray of elements smaller than the base value and the subarray of elements greater than the base value.
Sort effect:
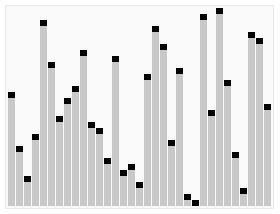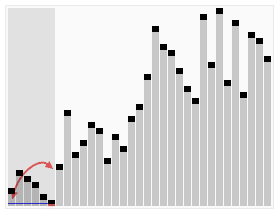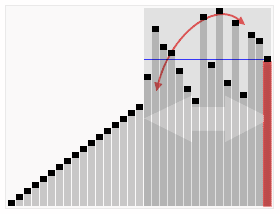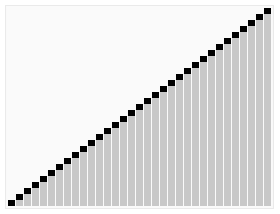
2 Merge sort
Introduction:
Merge sort (Merge sort, Taiwanese translation: merge sort) is an effective sorting algorithm based on merge operations. This algorithm is a very typical application using the divide and conquer method (pide and Conquer).
Steps:
Apply for space so that its size is the sum of two sorted sequences. The space is To store the merged sequence
Set two pointers, the initial positions are the starting positions of the two sorted sequences
Compare the elements pointed to by the two pointers, select relatively small elements and put them into the merge space , and move the pointer to the next position
Repeat step 3 until a certain pointer reaches the end of the sequence
Copy all the remaining elements of the other sequence directly to the end of the merged sequence
Sort effect :

3 Heap sort
Introduction:
Heapsort refers to the use A sorting algorithm designed for the data structure of a heap. A heap is a structure that approximates a complete binary tree and satisfies the heap property: that is, the key value or index of a child node is always smaller (or larger) than its parent node.
Steps:
(It’s more complicated, check it out online)
Sorting effect:
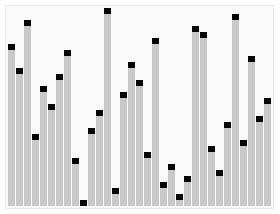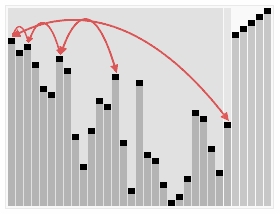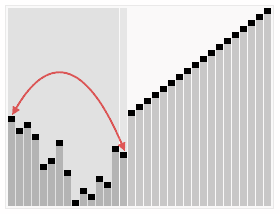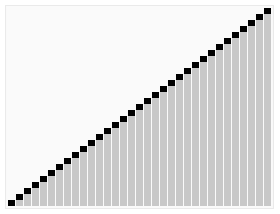
4 Selection sort
Introduction:
Selection sort is a simple and intuitive sorting algorithm. Here's how it works. First, find the smallest element in the unsorted sequence and store it at the beginning of the sorted sequence. Then, continue to find the smallest element from the remaining unsorted elements, and then put it at the end of the sorted sequence. And so on until all elements are sorted.
Sort effect:

5 Bubble sort
Introduction:
Bubble Sort (Bubble Sort, translated from Taiwan as: Bubble Sort or Bubble Sort) is a simple sorting algorithm. It repeatedly walks through the sequence to be sorted, comparing two elements at a time and swapping them if they are in the wrong order. The work of visiting the array is repeated until no more exchanges are needed, which means that the array has been sorted. The name of this algorithm comes from the fact that smaller elements will slowly "float" to the top of the array through swapping.
Steps:
Compare adjacent elements. If the first one is bigger than the second one, swap them both.
Do the same for each pair of adjacent elements, starting with the first pair and ending with the last pair. At this point, the last element should be the largest number.
Repeat the above steps for all elements except the last one.
Continue to repeat the above steps for fewer and fewer elements each time until there are no pairs of numbers to compare.
Sort effect:

6 Insertion sort
Introduction:
The algorithm description of Insertion Sort is a simple and intuitive sorting algorithm. It works by constructing an ordered sequence. For unsorted data, it scans from back to front in the sorted sequence, finds the corresponding position and inserts it. In the implementation of insertion sort, in-place sorting is usually used (that is, sorting that only uses O(1) extra space). Therefore, during the scanning process from back to front, it is necessary to repeatedly and gradually shift the sorted elements backward. , providing insertion space for the latest element.
Steps:
Start from the first element, which can be considered to have been sorted
Take out the next element and scan from back to front in the sorted element sequence
If the element (sorted) is greater than the new element, move the element to the next position
Repeat step 3 until you find a position where the sorted element is less than or equal to the new element
Insert the new element into that position
Repeat step 2
7 Hill sorting
Introduction:
Hill sorting, also known as descending incremental sorting algorithm is a high-speed and stable improved version of insertion sort.
Hill sorting proposes an improved method based on the following two properties of insertion sorting:
Insertion sorting is highly efficient when operating on almost sorted data, that is, it can achieve The efficiency of linear sorting
But insertion sorting is generally inefficient, because insertion sorting can only move the data one bit at a time
Sort effect:
The above is the detailed content of Dynamic diagram explanation of commonly used sorting algorithms. For more information, please follow other related articles on the PHP Chinese website!