
Home >Web Front-end >JS Tutorial >Nodejs crawler advanced tutorial asynchronous concurrency control_node.js
Nodejs crawler advanced tutorial asynchronous concurrency control_node.js

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2016-05-16 15:15:381968browse
I wrote a small crawler before that seems to be very imperfect now. Many aspects were not handled well. For example, when you click on a question on Zhihu, not all its answers are loaded. When you pull When you get to the end of the answer, click Load More and the answer will be loaded again. Therefore, if you directly send a request link to a question, the page obtained will be incomplete. Also, when we download pictures by sending links, we download them one by one. If there are too many pictures, it will still be downloaded after you have finished sleeping. Moreover, the crawler we wrote using nodejs does not download the pictures one by one. It’s such a waste that the most powerful asynchronous and concurrency feature of nodejs is not used.
Thoughts
This time’s crawler is an upgraded version of the last one. However, although the last one was simple, it is very suitable for novices to learn. The crawler code this time can be found on my github => NodeSpider.
The idea of the entire crawler is this: At the beginning, we crawled part of the page data through the link of the request question, and then we simulated the ajax request in the code to intercept the remaining page data. Of course, it can also be done asynchronously here. To achieve concurrency, for small-scale asynchronous process control, you can use this module => eventproxy, but I have no use for it here! We intercept the links of all pictures by analyzing the obtained page, and then implement batch download of these pictures through asynchronous concurrency.
It is very simple to capture the initial data of the page, so I won’t explain much here
/*获取首屏所有图片链接*/
var getInitUrlList=function(){
request.get("https://www.zhihu.com/question/")
.end(function(err,res){
if(err){
console.log(err);
}else{
var $=cheerio.load(res.text);
var answerList=$(".zm-item-answer");
answerList.map(function(i,answer){
var images=$(answer).find('.zm-item-rich-text img');
images.map(function(i,image){
photos.push($(image).attr("src"));
});
});
console.log("已成功抓取"+photos.length+"张图片的链接");
getIAjaxUrlList();
}
});
}
Simulate ajax request to get the complete page
The next step is how to simulate the ajax request issued when clicking to load more, go to Zhihu and take a look!
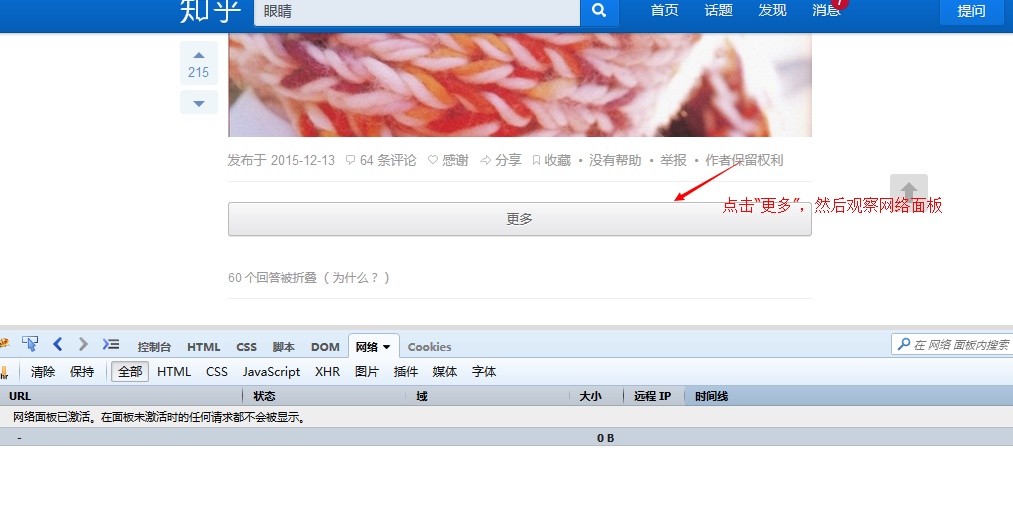
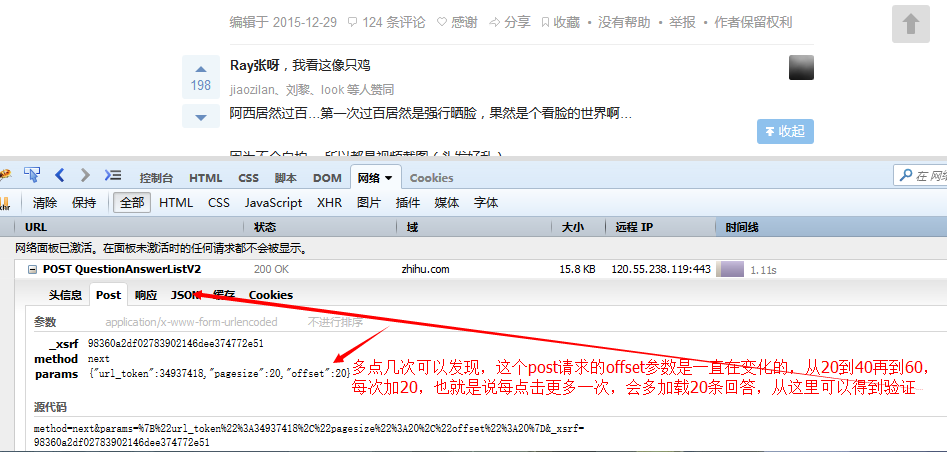
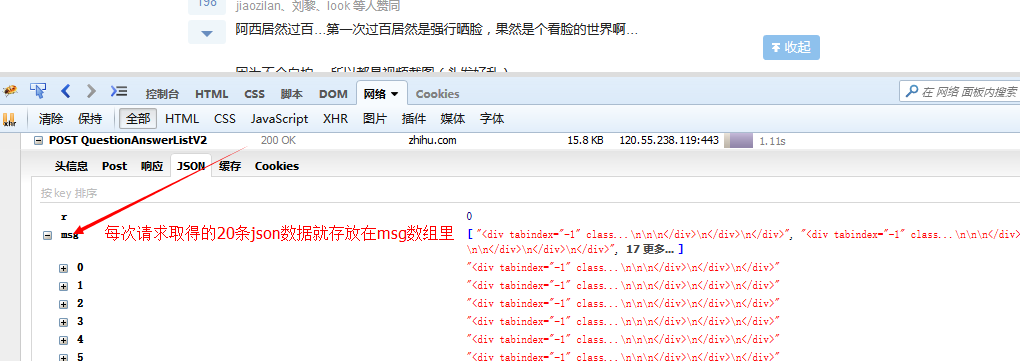
With this information, you can simulate sending the same request to obtain this data.
/*每隔毫秒模拟发送ajax请求,并获取请求结果中所有的图片链接*/
var getIAjaxUrlList=function(offset){
request.post("https://www.zhihu.com/node/QuestionAnswerListV")
.set(config)
.send("method=next¶ms=%B%url_token%%A%C%pagesize%%A%C%offset%%A" +offset+ "%D&_xsrf=adfdeee")
.end(function(err,res){
if(err){
console.log(err);
}else{
var response=JSON.parse(res.text);/*想用json的话对json序列化即可,提交json的话需要对json进行反序列化*/
if(response.msg&&response.msg.length){
var $=cheerio.load(response.msg.join(""));/*把所有的数组元素拼接在一起,以空白符分隔,不要这样join(),它会默认数组元素以逗号分隔*/
var answerList=$(".zm-item-answer");
answerList.map(function(i,answer){
var images=$(answer).find('.zm-item-rich-text img');
images.map(function(i,image){
photos.push($(image).attr("src"));
});
});
setTimeout(function(){
offset+=;
console.log("已成功抓取"+photos.length+"张图片的链接");
getIAjaxUrlList(offset);
},);
}else{
console.log("图片链接全部获取完毕,一共有"+photos.length+"条图片链接");
// console.log(photos);
return downloadImg();
}
}
});
}
Post this request in the code https://www.zhihu.com/node/QuestionAnswerListV2, copy the original request headers and request parameters as our request headers and request parameters, superagent The set method can be used to set request headers, and the send method can be used to send request parameters. We initialize the offset in the request parameter to 20, add 20 to the offset every certain time, and then resend the request. This is equivalent to us sending an ajax request every certain time and getting the latest 20 pieces of data. Every time we get the When we get the data, we will process the data to a certain extent and turn it into a whole paragraph of HTML, which will facilitate subsequent extraction and link processing. After asynchronous concurrency control downloads pictures and obtains all the picture links, that is, when it is determined that response.msg is empty, we will download these pictures. It is impossible to download them one by one, because as you can see, we There are enough pictures
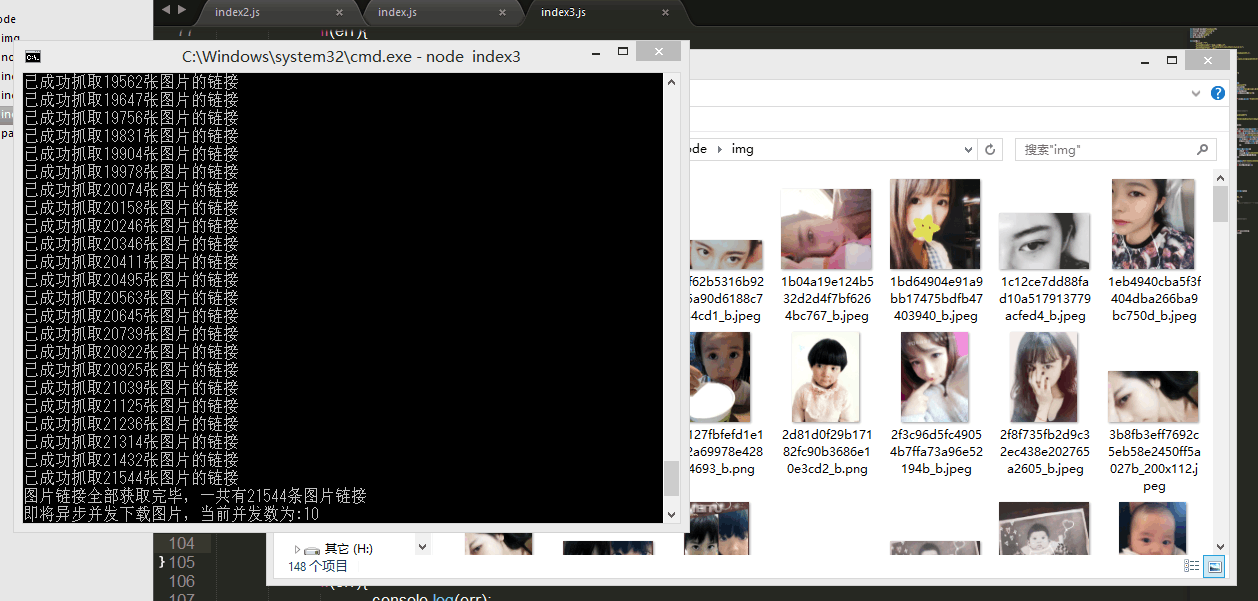
Yes, more than 20,000 pictures, but fortunately nodejs has the magical single-thread asynchronous feature, we can download these pictures at the same time. But this time a problem arises. I heard that if too many requests are sent at the same time, the IP address will be blocked by the website! Is this true? I don’t know, I haven’t tried it, because I don’t want to try it ( ̄ー ̄〃), so at this time we need to control the number of asynchronous concurrency.
A magical module is used here => async, which not only helps us get rid of the difficult-to-maintain callback pyramid devil, but also easily helps us manage asynchronous processes. Please refer to the documentation for details. Since I don’t know how to use it myself, I only use the powerful async.mapLimit method here. It's really awesome.
var requestAndwrite=function(url,callback){
request.get(url).end(function(err,res){
if(err){
console.log(err);
console.log("有一张图片请求失败啦...");
}else{
var fileName=path.basename(url);
fs.writeFile("./img/"+fileName,res.body,function(err){
if(err){
console.log(err);
console.log("有一张图片写入失败啦...");
}else{
console.log("图片下载成功啦");
callback(null,"successful !");
/*callback貌似必须调用,第二个参数将传给下一个回调函数的result,result是一个数组*/
}
});
}
});
}
var downloadImg=function(asyncNum){
/*有一些图片链接地址不完整没有“http:”头部,帮它们拼接完整*/
for(var i=;i<photos.length;i++){
if(photos[i].indexOf("http")===-){
photos[i]="http:"+photos[i];
}
}
console.log("即将异步并发下载图片,当前并发数为:"+asyncNum);
async.mapLimit(photos,asyncNum,function(photo,callback){
console.log("已有"+asyncNum+"张图片进入下载队列");
requestAndwrite(photo,callback);
},function(err,result){
if(err){
console.log(err);
}else{
// console.log(result);<=会输出一个有万多个“successful”字符串的数组
console.log("全部已下载完毕!");
}
});
};
Look here first=>
The first parameter photos of the mapLimit method is an array of all picture links, which is also the object of our concurrent requests. asyncNum limits the number of concurrent requests. Without this parameter, more than 20,000 requests will be sent at the same time. , well, your IP will be successfully blocked, but when we have this parameter, for example, its value is 10, it will only help us fetch 10 links from the array at a time and execute concurrent requests. After these 10 requests are responded to, the next 10 requests are sent. Tell Ni Meng, it’s okay to send 100 messages at the same time. The download speed is super fast. I don’t know if it goes up further. Please tell me...
The above has introduced you to the relevant knowledge of asynchronous concurrency control in the Nodejs crawler advanced tutorial. I hope it will be helpful to you.
Related articles
See more- An in-depth analysis of the Bootstrap list group component
- Detailed explanation of JavaScript function currying
- Complete example of JS password generation and strength detection (with demo source code download)
- Angularjs integrates WeChat UI (weui)
- How to quickly switch between Traditional Chinese and Simplified Chinese with JavaScript and the trick for websites to support switching between Simplified and Traditional Chinese_javascript skills