


You can get download numbers for PyPI packages (or projects) from a Google BigQuery dataset. You need a Google account and credentials, and Google gives 1 TiB of free quota per month.
Each month, I have automation to fetch the download numbers for the 8,000 most popular packages over the past 30 days, and make it available as more accessible JSON and CSV files at Top PyPI Packages. This data is widely used for research in academia and industry.
However, as more packages and releases are uploaded to PyPI, and there are more and more downloads logged, the amount of billed data increases too.

This chart shows the amount of data billed per month.
At first, I was only collecting downloads data for 4,000 packages, and it was fetched for two queries: downloads over 365 days and over 30 days. But as time passed, it started using up too much quota to download data for 365 days.
So I ditched the 365-day data, and increased the 30-day data from 4,000 to 5,000 packages. Later, I checked how much quota was being used and increased from 5,000 packages to 8,000 packages.
But then I exceeded the BigQuery monthly quota of 1 TiB fetching data for July 2024.
To fetch the missing data and investigate what's going in, I started Google Cloud's 90-day, $300 (€277.46) free-trial ?
Here's what I found!
Finding: it costs more to get data for downloads from only pip than from all installers
I use the pypinfo client to help query BigQuery. By default, it only fetches downloads for pip.
Only pip
This command gets one day's download data for the top 10 packages, for pip only:
$ pypinfo --limit 10 --days 1 "" project Served from cache: False Data processed: 58.21 GiB Data billed: 58.21 GiB Estimated cost: <pre class="brush:php;toolbar:false">$ pypinfo --all --limit 10 --days 1 "" project Served from cache: False Data processed: 46.63 GiB Data billed: 46.63 GiB Estimated cost: <pre class="brush:php;toolbar:false">SELECT file.project as project, COUNT(*) as download_count, FROM `bigquery-public-data.pypi.file_downloads` WHERE timestamp BETWEEN TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -2 DAY) AND TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -1 DAY) AND details.installer.name = "pip" GROUP BY project ORDER BY download_count DESC LIMIT 10.23 .29
Results:
| project | download count |
|---|---|
| boto3 | 37,251,744 |
| aiobotocore | 16,252,824 |
| urllib3 | 16,243,278 |
| botocore | 15,687,125 |
| requests | 13,271,314 |
| s3fs | 12,865,055 |
| s3transfer | 12,014,278 |
| fsspec | 11,982,305 |
| charset-normalizer | 11,684,740 |
| certifi | 11,639,584 |
| Total | 158,892,247 |
All installers
Adding the --all flag gets one day's download data for the top 10 packages, for all installers:
$ pypinfo --limit 10 --days 1 "" project Served from cache: False Data processed: 58.21 GiB Data billed: 58.21 GiB Estimated cost: <pre class="brush:php;toolbar:false">$ pypinfo --all --limit 10 --days 1 "" project Served from cache: False Data processed: 46.63 GiB Data billed: 46.63 GiB Estimated cost: <pre class="brush:php;toolbar:false">SELECT file.project as project, COUNT(*) as download_count, FROM `bigquery-public-data.pypi.file_downloads` WHERE timestamp BETWEEN TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -2 DAY) AND TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -1 DAY) AND details.installer.name = "pip" GROUP BY project ORDER BY download_count DESC LIMIT 10.23 .29
| project | download count |
|---|---|
| boto3 | 39,495,624 |
| botocore | 17,281,187 |
| urllib3 | 17,225,121 |
| aiobotocore | 16,430,826 |
| requests | 14,287,965 |
| s3fs | 12,958,516 |
| charset-normalizer | 12,781,405 |
| certifi | 12,647,098 |
| setuptools | 12,608,120 |
| idna | 12,510,335 |
| Total | 168,226,197 |
So we can see the default pip-only costs an extra 25% data processed and data billed, and costs an extra 25% in dollars.
Unsurprisingly, the actual download counts are higher for all installers. The ranking has changed a bit, but I expect we're still getting more-or-less the same packages in the top thousands of results.
Queries
It sends a query like this to BigQuery for only pip:
SELECT file.project as project, COUNT(*) as download_count, FROM `bigquery-public-data.pypi.file_downloads` WHERE timestamp BETWEEN TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -2 DAY) AND TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -1 DAY) GROUP BY project ORDER BY download_count DESC LIMIT 10
And for all installers:
$ pypinfo --all --limit 100 --days 1 "" installer Served from cache: False Data processed: 29.49 GiB Data billed: 29.49 GiB Estimated cost: <pre class="brush:php;toolbar:false">SELECT file.project as project, COUNT(*) as download_count, FROM `bigquery-public-data.pypi.file_downloads` WHERE timestamp BETWEEN TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -2 DAY) AND TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -1 DAY) GROUP BY project ORDER BY download_count DESC LIMIT 8000.15
These queries are the same, except the default has an extra AND details.installer.name = "pip" condition. It seems reasonable it would cost more to do extra filtering work.
Installers
Let's look at the installers:
| installer name | download count |
|---|---|
| pip | 1,121,198,711 |
| uv | 117,194,833 |
| requests | 29,828,272 |
| poetry | 23,009,454 |
| None | 8,916,745 |
| bandersnatch | 6,171,555 |
| setuptools | 1,362,797 |
| Bazel | 1,280,271 |
| Browser | 1,096,328 |
| Nexus | 593,230 |
| Homebrew | 510,247 |
| Artifactory | 69,063 |
| pdm | 62,904 |
| OS | 13,108 |
| devpi | 9,530 |
| conda | 2,272 |
| pex | 194 |
| Total | 1,311,319,514 |
pip still by far the most popular, and unsurprising uv is up there too, with about 10% of pip's downloads.
The others are about 25% or less of uv. A lot of them are mirroring services that we wanted to exclude before.
I think given uv's importance, and my expectation that it will continue to take a bigger share of the pie, plus especially the extra cost for filtering by just pip, means that we should switch to fetching data for all downloaders. Plus the others don't account for that much of the pie.
Finding: the number of packages doesn't affect the cost
This was the biggest surprise. Earlier I'd been increasing or decreasing the number to try and remain under quota. But it turns out it makes no difference how many packages you query!
I fetched data for just one day and all installers for different package limits: 1000, 2000, 3000, 4000, 5000, 6000, 7000, 8000. Sample query:
$ pypinfo --limit 10 --days 1 "" project Served from cache: False Data processed: 58.21 GiB Data billed: 58.21 GiB Estimated cost: <pre class="brush:php;toolbar:false">$ pypinfo --all --limit 10 --days 1 "" project Served from cache: False Data processed: 46.63 GiB Data billed: 46.63 GiB Estimated cost: <pre class="brush:php;toolbar:false">SELECT file.project as project, COUNT(*) as download_count, FROM `bigquery-public-data.pypi.file_downloads` WHERE timestamp BETWEEN TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -2 DAY) AND TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -1 DAY) AND details.installer.name = "pip" GROUP BY project ORDER BY download_count DESC LIMIT 10.23 .29
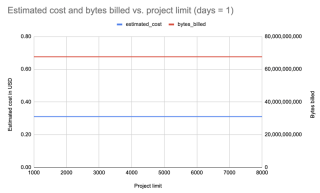
Result: Interestingly, the cost is the same for all limits (1000-8000): $0.31.
Repeating with one day but filtering for pip only:

Result: Cost increased to $0.39 but again the same for all limits.
Let's repeat with all installers, but for 30 days, and this time query in decreasing limits, in case we were only paying for incremental changes: 8000, 7000, 6000, 5000, 4000, 3000, 2000, 1000:

Result: Again, the cost is the same regardless of package limit: $4.89 per query.
Well then, let's repeat with the limit increasing by powers of ten, up to 1,000,000! This last one fetches data for all 531,022 packages on PyPI:
| limit | projects count | estimated cost | bytes billed | bytes processed |
|---|---|---|---|---|
| 1 | 1 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 10 | 10 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 100 | 100 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 1000 | 1,000 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 8000 | 8,000 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 10000 | 10,000 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 100000 | 100,000 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 1000000 | 531,022 | 0.20 | 43,447,746,560 | 43,447,720,943 |
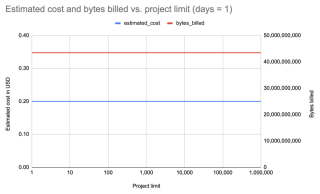
Result: Again, same cost, whether for 1 package or 531,022 packages!
Finding: the number of days affects the cost
No surprise. I'd earlier noticed 365 days too took much quota, and I could continue with 30 days.
Here's the estimated cost and bytes billed (for one package, all installers) between one and 30 days (f"pypinfo --all --json --indent 0 --days {days} --limit 1 '' project"), showing a roughly linear increase:

Conclusion
It doesn't matter how many packages I fetch data for, I might as well fetch all and make it available to everyone, depending on the size of the data file. It will make sense to still offer a smaller file with 8,000 or so packages: often you just need a large-ish yet manageable number.
It costs more to filter for only downloads from pip, so I've switched to fetching data for all installers.
The number of days affects the cost, so I will need to decrease this in the future to stay within quota. For example, at some point I may need to switch from 30 to 25 days, and later from 25 to 20 days.
More details from the investigation, the scripts and data files can be found at
hugovk/top-pypi-packages#36.
And let me know if you know any tricks to reduce costs!
Header photo: "The Balancing Rock, Stonehenge, Near Glen Innes, NSW" by the Royal Australian Historical Society, with no known copyright restrictions.
The above is the detailed content of A surprising thing about PyPI&#s BigQuery data. For more information, please follow other related articles on the PHP Chinese website!

 Merging Lists in Python: Choosing the Right MethodMay 14, 2025 am 12:11 AM
Merging Lists in Python: Choosing the Right MethodMay 14, 2025 am 12:11 AMTomergelistsinPython,youcanusethe operator,extendmethod,listcomprehension,oritertools.chain,eachwithspecificadvantages:1)The operatorissimplebutlessefficientforlargelists;2)extendismemory-efficientbutmodifiestheoriginallist;3)listcomprehensionoffersf
 How to concatenate two lists in python 3?May 14, 2025 am 12:09 AM
How to concatenate two lists in python 3?May 14, 2025 am 12:09 AMIn Python 3, two lists can be connected through a variety of methods: 1) Use operator, which is suitable for small lists, but is inefficient for large lists; 2) Use extend method, which is suitable for large lists, with high memory efficiency, but will modify the original list; 3) Use * operator, which is suitable for merging multiple lists, without modifying the original list; 4) Use itertools.chain, which is suitable for large data sets, with high memory efficiency.
 Python concatenate list stringsMay 14, 2025 am 12:08 AM
Python concatenate list stringsMay 14, 2025 am 12:08 AMUsing the join() method is the most efficient way to connect strings from lists in Python. 1) Use the join() method to be efficient and easy to read. 2) The cycle uses operators inefficiently for large lists. 3) The combination of list comprehension and join() is suitable for scenarios that require conversion. 4) The reduce() method is suitable for other types of reductions, but is inefficient for string concatenation. The complete sentence ends.
 Python execution, what is that?May 14, 2025 am 12:06 AM
Python execution, what is that?May 14, 2025 am 12:06 AMPythonexecutionistheprocessoftransformingPythoncodeintoexecutableinstructions.1)Theinterpreterreadsthecode,convertingitintobytecode,whichthePythonVirtualMachine(PVM)executes.2)TheGlobalInterpreterLock(GIL)managesthreadexecution,potentiallylimitingmul
 Python: what are the key featuresMay 14, 2025 am 12:02 AM
Python: what are the key featuresMay 14, 2025 am 12:02 AMKey features of Python include: 1. The syntax is concise and easy to understand, suitable for beginners; 2. Dynamic type system, improving development speed; 3. Rich standard library, supporting multiple tasks; 4. Strong community and ecosystem, providing extensive support; 5. Interpretation, suitable for scripting and rapid prototyping; 6. Multi-paradigm support, suitable for various programming styles.
 Python: compiler or Interpreter?May 13, 2025 am 12:10 AM
Python: compiler or Interpreter?May 13, 2025 am 12:10 AMPython is an interpreted language, but it also includes the compilation process. 1) Python code is first compiled into bytecode. 2) Bytecode is interpreted and executed by Python virtual machine. 3) This hybrid mechanism makes Python both flexible and efficient, but not as fast as a fully compiled language.
 Python For Loop vs While Loop: When to Use Which?May 13, 2025 am 12:07 AM
Python For Loop vs While Loop: When to Use Which?May 13, 2025 am 12:07 AMUseaforloopwheniteratingoverasequenceorforaspecificnumberoftimes;useawhileloopwhencontinuinguntilaconditionismet.Forloopsareidealforknownsequences,whilewhileloopssuitsituationswithundeterminediterations.
 Python loops: The most common errorsMay 13, 2025 am 12:07 AM
Python loops: The most common errorsMay 13, 2025 am 12:07 AMPythonloopscanleadtoerrorslikeinfiniteloops,modifyinglistsduringiteration,off-by-oneerrors,zero-indexingissues,andnestedloopinefficiencies.Toavoidthese:1)Use'i


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SublimeText3 Linux new version
SublimeText3 Linux latest version

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

Notepad++7.3.1
Easy-to-use and free code editor

