
 Technology peripheralsAITo provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Technology peripheralsAITo provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG frameworkTo provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework


Editor | ScienceAI
Question and Answer (QA) data sets play a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge.
Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings.
First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but they limit the model’s answer selection range and cannot fully test the model’s ability to answer scientific questions. In contrast, open question answering (openQA) can more comprehensively evaluate the model's capabilities, but lacks suitable evaluation metrics.
Second, many of the contents of existing data sets come from textbooks at university level and below, making it difficult to evaluate LLM’s high-level knowledge retention capabilities in actual academic research or production environments.
Third, the creation of these benchmark datasets relies on human expert annotation.
Addressing these challenges is crucial to building a more comprehensive QA data set and is also conducive to more accurate assessment of scientific LLM.
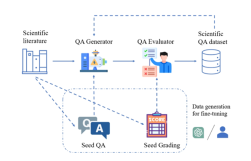
Illustration: SciQAG framework for generating high-quality scientific question and answer pairs from scientific literature.
To this end, the Argonne National Laboratory in the United States, the team of Professor Ian Foster of the University of Chicago (2002 Gordon Bell Prize winner), the UNSW AI4Science team of Professor Bram Hoex of the University of New South Wales, Australia, the AI4Science company GreenDynamics and the team of Professor Jie Chunyu of the City University of Hong Kong jointly proposed SciQAG, the first novel framework to automatically generate high-quality scientific open question and answer pairs from large scientific literature corpora based on large language models (LLM).

Paper link:https://arxiv.org/abs/2405.09939
github link:https://github.com/MasterAI-EAM/SciQAG
Based on SciQAG, the researchers built SciQAG-24D, a large-scale, high-quality, open scientific QA dataset, contains 188,042 QA pairs extracted from 22,743 scientific papers in 24 scientific fields, and is designed to serve the fine-tuning of LLM and the assessment of scientific problem-solving capabilities.
Experiments demonstrate that fine-tuning LLMs on the SciQAG-24D dataset can significantly improve their performance in open-ended question answering and scientific tasks.
The data set, model and evaluation code have been open sourced (https://github.com/MasterAI-EAM/SciQAG) to promote the joint development of open scientific Q&A by the AI for Science community.
SciQAG framework with SciQAG-24D benchmark dataset
SciQAG consists of a QA generator and a QA evaluator, aiming to quickly generate diverse open question and answer pairs based on scientific literature at scale. First, the generator converts scientific papers into question and answer pairs, and then the evaluator filters out the question and answer pairs that do not meet the quality standards, thereby obtaining a high-quality scientific question and answer dataset.
QA Generator
The researchers designed a two-step prompt (prompt) through comparative experiments, allowing LLM to first extract keywords and then generate question and answer pairs based on the keywords.
Since the generated question and answer data set adopts the "closed book" mode, that is, the original paper is not provided and only focuses on the extracted scientific knowledge itself. The prompt requires that the generated question and answer pairs do not rely on or refer to the unique information in the original paper (for example, no modern nomenclature is allowed). Such as "this/this paper", "this/this research", etc., or asking questions about the tables/pictures in the article).
To balance performance and cost, the researchers chose to fine-tune an open source LLM as the generator. SciQAG users can choose any open source or closed source LLM as the generator according to their own circumstances, either using fine-tuning or prompt word engineering.
QA Evaluator
The evaluator is used to accomplish two purposes: (1) Evaluate the quality of generated question and answer pairs; (2) Discard low-quality question and answer pairs based on set criteria.
Researchers developed a comprehensive evaluation index RACAR, which consists of five dimensions: relevance, agnosticism, completeness, accuracy and reasonableness.
In this study, the researchers directly used GPT-4 as the QA evaluator to evaluate the generated QA pairs according to RACAR, with an evaluation level of 1-5 (1 means unacceptable, 5 means completely acceptable).
As shown in the figure, to measure the consistency between GPT-4 and manual evaluation, two domain experts used the RACAR metric to perform manual evaluation on 10 articles (a total of 100 question and answer pairs). Users can choose any open source or closed source LLM as an evaluator according to their needs.
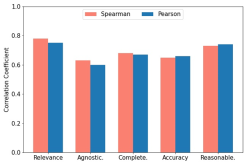
Illustration: Spearman and Pearson correlations between GPT-4 assigned scores and expert annotation scores.
Application of SciQAG framework
This study obtained a total of 22,743 highly cited papers in 24 categories from the Web of Science (WoS) core collection database, from the fields of materials science, chemistry, physics, energy, etc., aiming to build a A reliable, rich, balanced and representative source of scientific knowledge.
To fine-tune the open source LLM to form a QA generator, the researchers randomly selected 426 papers from the paper collection as input and generated 4260 seed QA pairs by prompting GPT-4.
Using the trained QA generator to perform inference on the remaining papers, a total of 227,430 QA pairs (including seed QA pairs) were generated. Fifty papers were extracted from each category (1,200 papers in total), GPT-4 was used to calculate the RACAR score of each generated QA pair, and QA pairs with any dimension score lower than 3 were filtered out as the test set.
For the remaining QA pairs, a rule-based method is used to filter out all question and answer pairs that contain unique information of the paper to form a training set.
SciQAG-24D benchmark data set
Based on the above, researchers established the open scientific QA benchmark data set SciQAG-24D. The filtered training set includes 21,529 papers and 179,511 QA pairs, and the filtered The test set contains 1,199 papers and 8,531 QA pairs.
Statistics show that 99.15% of the data in the answers come from the original paper, 87.29% of the questions have a similarity below 0.3, and the answers cover 78.26% of the original content.
This data set is widely used: the training set can be used to fine-tune LLM and inject scientific knowledge into it; the test set can be used to evaluate the performance of LLM on open QA tasks in a specific or overall scientific field. Since the test set is larger, it can also be used as high-quality data for fine-tuning.
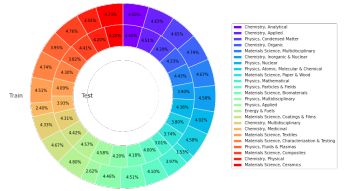
Illustration: The proportion of articles in different categories in the training and testing of the SciQAG-24D dataset.
Experimental results
The researchers conducted comprehensive experiments to compare the performance differences in scientific question answering between different language models and explore the impact of fine-tuning.
Zero-shot setting
The researchers used part of the test set in SciQAG-24D to conduct a zero-shot performance comparison of the five models. Two of them are open source LLMs: LLaMA1 (7B) and LLaMA2-chat (7B), and the rest are closed source LLMs.
Called via API: GPT3.5 (gpt-3.5-turbo), GPT-4 (gpt-4-1106-preview) and Claude 3 (claude-3-opus-20240229). Each model was prompted with 1,000 questions in the test, and its output was evaluated by the CAR metric (adapted from the RACAR metric, focusing only on response evaluation) to measure its zero-shot ability to answer scientific research questions.
As shown in the figure, among all models, GPT-4 has the highest score for completeness (4.90) and plausibility (4.99), while Claude 3 has the highest accuracy score (4.95). GPT-3.5 also performs very well, scoring closely behind GPT-4 and Claude 3 on all metrics.
Notably, LLaMA1 has the lowest scores in all three dimensions. In contrast, although the LLaMA2-chat model does not score as high as the GPT model, it significantly improves over the original LLaMA1 in all metrics. The results demonstrate the superior performance of commercial LLMs in answering scientific questions, while open source models (such as LLaMA2-chat) have also made significant progress in this regard.
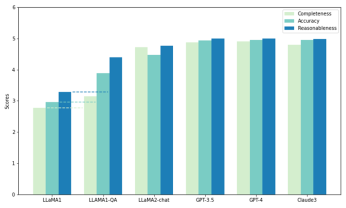
Illustration: Zero-sample test and fine-tuning test (LLAMA1-QA) on SciQAG-24D
fine-tuning setting (fine-tuning setting)
The researchers selected LLaMA1 with the worst zero-sample performance Fine-tuning is performed on the training set of SciQAG-24D to obtain LLaMA1-QA. Through three experiments, the researchers demonstrated that SciQAG-24D can be used as effective fine-tuning data to improve the performance of downstream scientific tasks:
(a) LLaMA-QA versus original LLaMA1 on the unseen SciQAG-24D test set Performance comparison.
As shown in the figure above, the performance of LLaMA1-QA has been significantly improved compared to the original LLaMA1 (completeness increased by 13%, accuracy and plausibility increased by more than 30%). This shows that LLaMA1 has learned the logic of answering scientific questions from the training data of SciQAG-24D and internalized some scientific knowledge.
(b) Comparison of fine-tuning performance on SciQ, a scientific MCQ benchmark.
The first row of the table below shows that LLaMA1-QA is slightly better than LLaMA1 (+1%). According to observations, fine-tuning also enhanced the model's instruction following ability: the probability of unparsable output dropped from 4.1% in LLaMA1 to 1.7% in LLaMA1-QA.
(c) Comparison of fine-tuning performance on various scientific tasks.
In terms of evaluation indicators, F1-score is used for classification tasks, MAE is used for regression tasks, and KL divergence is used for transformation tasks. As shown in the table below, LLaMA1-QA has significant improvements compared to the LLaMA1 model in scientific tasks.
The most obvious improvement is reflected in the regression task, where the MAE dropped from 463.96 to 185.32. These findings suggest that incorporating QA pairs during training can enhance the model's ability to learn and apply scientific knowledge, thereby improving its performance in downstream prediction tasks.
Surprisingly, compared to specially designed machine learning models with features, LLM can achieve results comparable to or even surpass them in some tasks. For example, in the band gap task, although LLaMA1-QA does not perform as well as models such as MODNet (0.3327), it has surpassed AMMExpress v2020 (0.4161).
In the diversity task, LLaMA1-QA outperforms the deep learning baseline (0.3198). These findings indicate that LLM has great potential in specific scientific tasks.
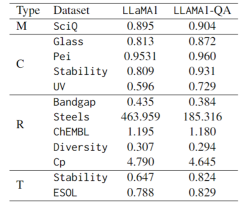
Illustration: Fine-tuning performance of LLaMA1 and LLaMA1-QA on SciQ and scientific tasks (M represents multiple choice, C represents classification, R represents regression, T represents transformation)
Summary and Outlook
(1) SciQAG is a framework for generating QA pairs from scientific literature. Combined with the RACAR metric for evaluating and screening QA pairs, it can efficiently generate large amounts of knowledge-based QA data for resource-poor scientific fields.
(2) The team generated a comprehensive open source scientific QA dataset containing 188,042 QA pairs, called SciQAG-24D. The training set is used to fine-tune the LLM, and the test set evaluates the performance of the LLM on open-ended closed-book scientific QA tasks.
The zero-sample performance of several LLMs on the SciQAG-24D test set was compared, and LLaMA1 was fine-tuned on the SciQAG-24D training set to obtain LLaMA1-QA. This fine-tuning significantly improves its performance on multiple scientific tasks.
(3) Research shows that LLM has potential in scientific tasks, and the results of LLaMA1-QA can reach levels even exceeding the machine learning baseline. This demonstrates the multifaceted utility of SciQAG-24D and shows that incorporating scientific QA data into the training process can enhance LLM's ability to learn and apply scientific knowledge.
The above is the detailed content of To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework. For more information, please follow other related articles on the PHP Chinese website!

 You Must Build Workplace AI Behind A Veil Of IgnoranceApr 29, 2025 am 11:15 AM
You Must Build Workplace AI Behind A Veil Of IgnoranceApr 29, 2025 am 11:15 AMIn John Rawls' seminal 1971 book The Theory of Justice, he proposed a thought experiment that we should take as the core of today's AI design and use decision-making: the veil of ignorance. This philosophy provides a simple tool for understanding equity and also provides a blueprint for leaders to use this understanding to design and implement AI equitably. Imagine that you are making rules for a new society. But there is a premise: you don’t know in advance what role you will play in this society. You may end up being rich or poor, healthy or disabled, belonging to a majority or marginal minority. Operating under this "veil of ignorance" prevents rule makers from making decisions that benefit themselves. On the contrary, people will be more motivated to formulate public
 Decisions, Decisions… Next Steps For Practical Applied AIApr 29, 2025 am 11:14 AM
Decisions, Decisions… Next Steps For Practical Applied AIApr 29, 2025 am 11:14 AMNumerous companies specialize in robotic process automation (RPA), offering bots to automate repetitive tasks—UiPath, Automation Anywhere, Blue Prism, and others. Meanwhile, process mining, orchestration, and intelligent document processing speciali
 The Agents Are Coming – More On What We Will Do Next To AI PartnersApr 29, 2025 am 11:13 AM
The Agents Are Coming – More On What We Will Do Next To AI PartnersApr 29, 2025 am 11:13 AMThe future of AI is moving beyond simple word prediction and conversational simulation; AI agents are emerging, capable of independent action and task completion. This shift is already evident in tools like Anthropic's Claude. AI Agents: Research a
 Why Empathy Is More Important Than Control For Leaders In An AI-Driven FutureApr 29, 2025 am 11:12 AM
Why Empathy Is More Important Than Control For Leaders In An AI-Driven FutureApr 29, 2025 am 11:12 AMRapid technological advancements necessitate a forward-looking perspective on the future of work. What happens when AI transcends mere productivity enhancement and begins shaping our societal structures? Topher McDougal's upcoming book, Gaia Wakes:
 AI For Product Classification: Can Machines Master Tax Law?Apr 29, 2025 am 11:11 AM
AI For Product Classification: Can Machines Master Tax Law?Apr 29, 2025 am 11:11 AMProduct classification, often involving complex codes like "HS 8471.30" from systems such as the Harmonized System (HS), is crucial for international trade and domestic sales. These codes ensure correct tax application, impacting every inv
 Could Data Center Demand Spark A Climate Tech Rebound?Apr 29, 2025 am 11:10 AM
Could Data Center Demand Spark A Climate Tech Rebound?Apr 29, 2025 am 11:10 AMThe future of energy consumption in data centers and climate technology investment This article explores the surge in energy consumption in AI-driven data centers and its impact on climate change, and analyzes innovative solutions and policy recommendations to address this challenge. Challenges of energy demand: Large and ultra-large-scale data centers consume huge power, comparable to the sum of hundreds of thousands of ordinary North American families, and emerging AI ultra-large-scale centers consume dozens of times more power than this. In the first eight months of 2024, Microsoft, Meta, Google and Amazon have invested approximately US$125 billion in the construction and operation of AI data centers (JP Morgan, 2024) (Table 1). Growing energy demand is both a challenge and an opportunity. According to Canary Media, the looming electricity
 AI And Hollywood's Next Golden AgeApr 29, 2025 am 11:09 AM
AI And Hollywood's Next Golden AgeApr 29, 2025 am 11:09 AMGenerative AI is revolutionizing film and television production. Luma's Ray 2 model, as well as Runway's Gen-4, OpenAI's Sora, Google's Veo and other new models, are improving the quality of generated videos at an unprecedented speed. These models can easily create complex special effects and realistic scenes, even short video clips and camera-perceived motion effects have been achieved. While the manipulation and consistency of these tools still need to be improved, the speed of progress is amazing. Generative video is becoming an independent medium. Some models are good at animation production, while others are good at live-action images. It is worth noting that Adobe's Firefly and Moonvalley's Ma
 Is ChatGPT Slowly Becoming AI's Biggest Yes-Man?Apr 29, 2025 am 11:08 AM
Is ChatGPT Slowly Becoming AI's Biggest Yes-Man?Apr 29, 2025 am 11:08 AMChatGPT user experience declines: is it a model degradation or user expectations? Recently, a large number of ChatGPT paid users have complained about their performance degradation, which has attracted widespread attention. Users reported slower responses to models, shorter answers, lack of help, and even more hallucinations. Some users expressed dissatisfaction on social media, pointing out that ChatGPT has become “too flattering” and tends to verify user views rather than provide critical feedback. This not only affects the user experience, but also brings actual losses to corporate customers, such as reduced productivity and waste of computing resources. Evidence of performance degradation Many users have reported significant degradation in ChatGPT performance, especially in older models such as GPT-4 (which will soon be discontinued from service at the end of this month). this


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SublimeText3 Linux new version
SublimeText3 Linux latest version

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

SublimeText3 Chinese version
Chinese version, very easy to use

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

