
Home >Technology peripherals >AI >Google's 'sincere work', open source 9B and 27B versions of Gemma2, focusing on efficiency and economy!
Google's 'sincere work', open source 9B and 27B versions of Gemma2, focusing on efficiency and economy!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-06-29 00:59:211195browse
Gemma 2 with twice the performance, how to play Llama 3 with the same level?


Excellent performance: The Gemma 2 27B model offers the best performance in its volume category, even competing with models more than twice its size Model competition. The 9B Gemma 2 model also performed well in its size category and outperformed the Llama 3 8B and other comparable open models. High efficiency, low cost: The 27B Gemma 2 model is designed to efficiently run inference at full precision on a single Google Cloud TPU host, NVIDIA A100 80GB Tensor Core GPU, or NVIDIA H100 Tensor Core GPU, while maintaining high performance Dramatically reduce costs. This makes AI deployment more convenient and affordable. Ultra-fast inference: Gemma 2 is optimized to run at blazing speeds on a variety of hardware, whether it’s a powerful gaming laptop, a high-end desktop, or a cloud-based setup. Users can try running Gemma 2 at full precision on Google AI Studio, or use a quantized version of Gemma.cpp on the CPU to unlock local performance, or try it on a home computer using NVIDIA RTX or GeForce RTX via Hugging Face Transformers.

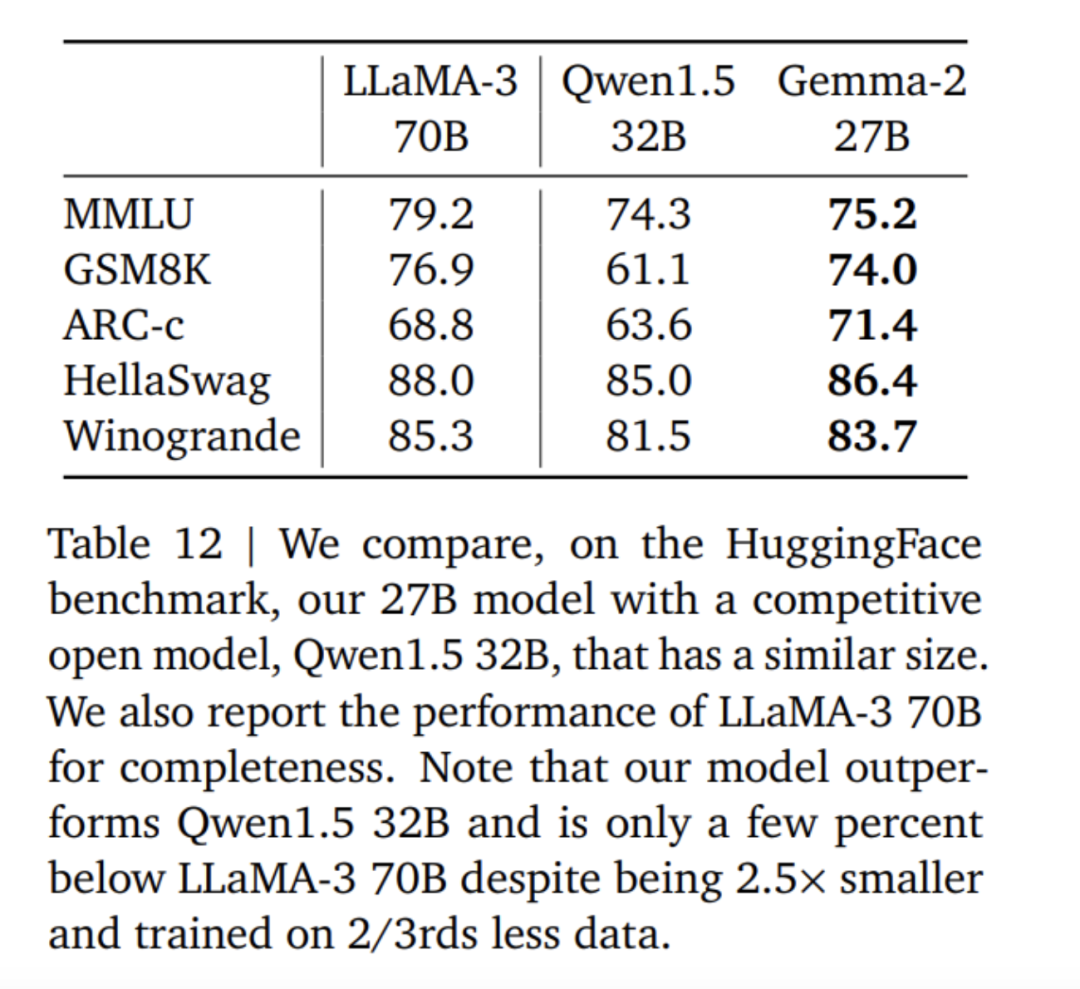
The above is the score data comparison between Gemma2, Llama3 and Grok-1.
In fact, judging from various score data, the advantages of the open source 9B large model are not particularly obvious. The large domestic model GLM-4-9B, which was open sourced by Zhipu AI nearly a month ago, has even more advantages.

Open and accessible: Like the original Gemma model, Gemma 2 allows developers and researchers to share and commercialize innovations. Broad framework compatibility: Gemma 2 is compatible with major AI frameworks such as Hugging Face Transformers, as well as JAX, PyTorch and TensorFlow natively supported through Keras 3.0, vLLM, Gemma.cpp, Llama.cpp and Ollama, making it Easily integrates with user-preferred tools and workflows. In addition, Gemma has been optimized with NVIDIA TensorRT-LLM and can run on NVIDIA accelerated infrastructure or as an NVIDIA NIM inference microservice. It will also be optimized for NVIDIA's NeMo in the future and can be fine-tuned using Keras and Hugging Face. In addition, Google is actively upgrading fine-tuning capabilities. Easy Deployment: Starting next month, Google Cloud customers will be able to easily deploy and manage Gemma 2 on Vertex AI.
In the latest blog, Google announced that it has opened Gemini 1.5 Pro’s 2 million token context window access to all developers. However, as the context window increases, the input cost may also increase. In order to help developers reduce the cost of multiple prompt tasks using the same token, Google has thoughtfully launched the context caching function in the Gemini API for Gemini 1.5 Pro and 1.5 Flash. To solve the problem that large language models need to generate and execute code to improve accuracy when processing mathematics or data reasoning, Google has enabled code execution in Gemini 1.5 Pro and 1.5 Flash. When turned on, the model can dynamically generate and run Python code and learn iteratively from the results until the desired final output is achieved. The execution sandbox does not connect to the Internet and comes standard with some numerical libraries. Developers only need to be billed based on the model's output token. This is the first time Google has introduced code execution as a step in model functionality, available today through the Gemini API and Advanced Settings in Google AI Studio. Google wants to make AI accessible to all developers, whether integrating Gemini models through API keys or using the open model Gemma 2. To help developers get their hands on the Gemma 2 model, the Google team will make it available for experimentation in Google AI Studio.

Paper address: https://storage.googleapis.com/deepmind-media/gemma/gemma-2-report.pdf Blog address: https://blog.google/ technology/developers/google-gemma-2/

Local sliding window and global attention. The research team alternated using local sliding window attention and global attention in every other layer. The sliding window size of the local attention layer is set to 4096 tokens, while the span of the global attention layer is set to 8192 tokens. Logit soft cap. According to the method of Gemini 1.5, the research team limits logit at each attention layer and the final layer so that the value of logit remains between −soft_cap and +soft_cap. For the 9B and 27B models, the research team set the logarithmic cap of attention to 50.0 and the final logarithmic cap to 30.0. As of the time of publication, attention logit soft capping is incompatible with common FlashAttention implementations, so they have removed this feature from libraries that use FlashAttention. The research team conducted ablation experiments on model generation with and without attention logit soft capping, and found that the generation quality was almost unaffected in most pre-training and post-evaluation. All evaluations in this paper use the full model architecture including attention logit soft capping. However, some downstream performance may still be slightly affected by this removal. Use RMSNorm for post-norm and pre-norm. In order to stabilize training, the research team used RMSNorm to normalize the input and output of each transformation sub-layer, attention layer and feed-forward layer. Query attention in groups. Both 27B and 9B models use GQA, num_groups = 2, and ablation-based experiments show improved inference speed while maintaining downstream performance.

First, apply supervised fine-tuning (SFT) on a mixture of text-only, English-only synthesis, and artificially generated prompt-response pairs. Then, reinforcement learning based on the reward model (RLHF) is applied on these models. The reward model is trained on token-based pure English preference data, and the strategy uses the same prompt as the SFT stage. Finally, improve the overall performance by averaging the models obtained at each stage. The final data mixing and post-training methods, including tuned hyperparameters, are chosen based on minimizing model hazards related to safety and hallucinations while increasing model usefulness.





The above is the detailed content of Google's 'sincere work', open source 9B and 27B versions of Gemma2, focusing on efficiency and economy!. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technological innovation accelerates the implementation of my country's brain-computer interface industry
- South Korea announced that it will invest 500 billion won in the next five years to support the core industry of AI technology.
- Lightning News | JD.com launches Yanxi AI large model for retail, medical, logistics and other industrial scenarios
- Ministry of Industry and Information Technology: my country's AI core industry scale reaches 500 billion yuan, and more than 2,500 digital workshops and smart factories have been built
- Robot ETF (159770): Attracting net capital inflows for 4 consecutive days, the 'Guiding Opinions on the Innovation and Development of Humanoid Robots' may promote the industrial development process