
 Technology peripheralsAIICML 2024 | Revealing the mechanism of non-linear Transformer learning and generalization in contextual learning
Technology peripheralsAIICML 2024 | Revealing the mechanism of non-linear Transformer learning and generalization in contextual learningICML 2024 | Revealing the mechanism of non-linear Transformer learning and generalization in contextual learning


The AIxiv column is a column where academic and technical content is published on this site. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
The author of this article, Li Hongkang, is a doctoral student in the Department of Electrical, Computer and Systems Engineering at Rensselaer Polytechnic Institute in the United States. He graduated from the University of Science and Technology of China with a bachelor's degree. Research directions include deep learning theory, large language model theory, statistical machine learning, etc. He has published many papers at top AI conferences such as ICLR/ICML/Neurips.
In-context learning (ICL) has demonstrated powerful capabilities in many LLM-related applications, but its theoretical analysis is still relatively limited. People are still trying to understand why LLM based on the Transformer architecture can exhibit the capabilities of ICL.
Recently, a team from Rensselaer Polytechnic Institute and IBM Research analyzed the ICL of Transformer with nonlinear attention module (attention) and multilayer perceptron (MLP) from the perspective of optimization and generalization theory ability. In particular, they theoretically proved the ICL mechanism in which a single-layer Transformer first selects some contextual examples based on the query in the attention layer, and then makes predictions based on label embeddings in the MLP layer. This article has been included in ICML 2024.

Paper title: How Do Nonlinear Transformers Learn and Generalize in In-Context Learning?
Paper address: https://arxiv.org/pdf/2402.15607
Background introduction
In context learning (ICL)
Context learning (ICL) is a new learning paradigm that is very popular in large language models (LLM). It specifically refers to adding N test sample testing examples (context) before the testing query (testing query)  , that is, the combination of test input
, that is, the combination of test input  and test output
and test output  , thus forming a testing prompt:
, thus forming a testing prompt:  as the input of the model to guide the model Make correct inferences. This method is different from the classic method of fine-tuning a pre-trained model. It does not require changing the weight of the model, making it more efficient.
as the input of the model to guide the model Make correct inferences. This method is different from the classic method of fine-tuning a pre-trained model. It does not require changing the weight of the model, making it more efficient.
Progress in ICL theoretical work
Many recent theoretical works are based on the research framework proposed by [1], that is, people can directly use the prompt format to train the Transformer (this step can also be understood as simulating A simplified LLM pre-training mode), thereby making the model have ICL capabilities. Existing theoretical work focuses on the expressive power of the model [2]. They found that one could find a Transformer with “perfect” parameters that could perform ICL through forward operations and even implicitly perform classic machine learning algorithms such as gradient descent. But these works cannot answer why Transformer can be trained to such "perfect" parameters with ICL capabilities. Therefore, there are also some works trying to understand the ICL mechanism from the perspective of training or generalization of Transformer [3,4]. However, due to the complexity of analyzing the Transformer structure, these works currently stop at studying linear regression tasks, and the models considered usually omit the non-linear part of the Transformer.
This article analyzes the ICL capabilities and mechanisms of Transformer with nonlinear attention and MLP from the perspective of optimization and generalization theory:
Based on a simplified classification model, this article specifically quantifies how the characteristics of the data affect a The in-domain and out-of-domain (OOD) ICL generalization capabilities of the layer single-head Transformer.
This article further explains how ICL is implemented through trained Transformer.
Based on the characteristics of the trained Transformer, this article also analyzes the feasibility of using magnitude-based model pruning during ICL inference.
Theoretical part
Problem description
This paper considers a two-classification problem, that is, mapping  to
to  through a task
through a task  . In order to solve such a problem, this article builds prompt for learning. The prompt here is represented as:
. In order to solve such a problem, this article builds prompt for learning. The prompt here is represented as:
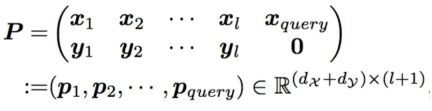
Training the network as a single-layer single-head Transformer:

The pre-training process is to solve an empirical risk minimization for all training tasks. The loss function uses Hinge loss, which is suitable for binary classification problems, and the training algorithm is stochastic gradient descent.
This article defines two cases of ICL generalization. One is in-domain, that is, the distribution of the test data is the same as the training data during generalization. Note that the test task does not have to be the same as the training task in this case, that is, the generalization of unseen tasks has been considered here. The other one is out-of-domain, that is, the distribution of test and training data is different.
This article also involves the analysis of magnitude-based pruning during ICL inference. The pruning method here refers to deleting each neuron obtained by training from small to large according to its amplitude.
Construction of data and tasks
Please refer to Section 3.2 of the original text for this part. Here is just an overview. The theoretical analysis of this article is based on the recently popular feature learning route, that is, the data is usually assumed to be separable (usually orthogonal) patterns, thereby deriving gradient changes based on different patterns. This article first defines a set of in-domain-relevant (IDR) patterns used to determine the classification of in-domain tasks, and a set of task-independent in-domain-irrelevant (IDI) patterns. These patterns are orthogonal to each other. There are  IDR patterns and
IDR patterns and  IDI patterns. A
IDI patterns. A  is represented as the sum of an IDR pattern and an IDI pattern. An in-domain task is defined as a classification problem based on two IDR patterns.
is represented as the sum of an IDR pattern and an IDI pattern. An in-domain task is defined as a classification problem based on two IDR patterns.
Similarly, this article can describe the data and tasks when OOD is generalized by defining out-of-domain-relevant (ODR) pattern and out-of-domain-irrelevant (ODI) pattern.
The representation of prompt in this article can be explained by the example in the figure below, where  is the IDR pattern and
is the IDR pattern and  is the IDI pattern. The task being done here is to classify based on
is the IDI pattern. The task being done here is to classify based on  in x. If it is
in x. If it is  , then its label is + 1, which corresponds to +q. If it is
, then its label is + 1, which corresponds to +q. If it is  , then its label is - 1, which corresponds to -q. α, α' are defined as the context examples that are the same as the query's IDR/ODR pattern in the training and testing prompts respectively. In the example below,
, then its label is - 1, which corresponds to -q. α, α' are defined as the context examples that are the same as the query's IDR/ODR pattern in the training and testing prompts respectively. In the example below,  .
.

Theoretical results
First of all, for the in-domain situation, this article first gives a condition 3.2 to specify the conditions that the training task needs to meet, that is, the training task needs to cover all IDR patterns and labels. Then the in-domain results are as follows:

This shows: 1. The number of training tasks only needs to account for a small proportion of all tasks that meets condition 3.2, and we can achieve good generalization of unseen tasks ; 2. The higher the proportion of IDR patterns related to the current task in the prompt, the ideal generalization can be achieved with less training data, number of training iterations, and shorter training/testing prompts.
Next is the result of out-of-domain generalization.

It is explained here that if the ODR pattern is a linear combination of the IDR pattern and the coefficient sum is greater than 1, then OOD ICL generalization can achieve the ideal effect at this time. This result gives the intrinsic connection between training and test data required for good OOD generalization under the framework of ICL. This theorem has also been verified by experiments on GPT-2. As shown in the figure below, when the coefficient sum  in (12) is greater than 1, OOD classification can achieve ideal results. At the same time, when
in (12) is greater than 1, OOD classification can achieve ideal results. At the same time, when  , that is, when the proportion of ODR/IDR patterns related to classification tasks in the prompt is higher, the required context length is smaller.
, that is, when the proportion of ODR/IDR patterns related to classification tasks in the prompt is higher, the required context length is smaller.
Then, this paper gives the ICL generalization results with magnitude-based pruning.

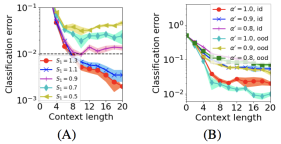
This result shows that, first of all, some (constant proportion) neurons in the trained  have small amplitudes, while the remaining ones are relatively large (Equation 14). When we only prune small neurons, there is basically no impact on the generalization results. When the proportion of pruning increases to pruning large neurons, the generalization error will increase significantly (Formula 15, 16). The following experiment verifies Theorem 3.7. The light blue vertical line in Figure A below represents the
have small amplitudes, while the remaining ones are relatively large (Equation 14). When we only prune small neurons, there is basically no impact on the generalization results. When the proportion of pruning increases to pruning large neurons, the generalization error will increase significantly (Formula 15, 16). The following experiment verifies Theorem 3.7. The light blue vertical line in Figure A below represents the  obtained by training and presents the results of Formula 14. However, pruning small neurons will not worsen generalization. This result is consistent with the theory. Figure B reflects that when there is more task-related context in the prompt, we can allow a larger pruning ratio to achieve the same generalization performance.
obtained by training and presents the results of Formula 14. However, pruning small neurons will not worsen generalization. This result is consistent with the theory. Figure B reflects that when there is more task-related context in the prompt, we can allow a larger pruning ratio to achieve the same generalization performance.

ICL mechanism
By characterizing the pre-training process, this article obtains the internal mechanism of single-layer single-head nonlinear Transformer for ICL, which is in Section 4 of the original article. This process can be represented by the diagram below.
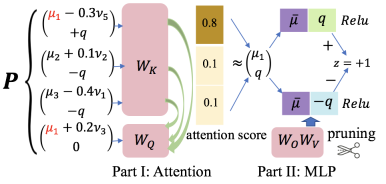
In short, the attention layer will select the same context as the ODR/IDR pattern of the query, giving them almost all attention weights, and then the MLP layer will focus on making the final classification based on the label embedding in the attention layer output. .
Summary
This article explains the training mechanism of nonlinear Transformer in ICL, as well as its generalization ability to new tasks and distribution shift data. The theoretical results have certain practical significance for designing prompt selection algorithm and LLM pruning algorithm.
参考文献
[1] Garg, et al., Neurips 2022. "What can transformers learn in-context? a case study of simple function classes."
[2] Von Oswald et al., ICML 2023. "Transformers learn in-context by gradient descent."
[3] Zhang et al., JMLR 2024. "Trained transformers learn linear models in-context."
[4] Huang et al., ICML 2024. "In-context convergence of transformers."
The above is the detailed content of ICML 2024 | Revealing the mechanism of non-linear Transformer learning and generalization in contextual learning. For more information, please follow other related articles on the PHP Chinese website!

 Let's Dance: Structured Movement To Fine-Tune Our Human Neural NetsApr 27, 2025 am 11:09 AM
Let's Dance: Structured Movement To Fine-Tune Our Human Neural NetsApr 27, 2025 am 11:09 AMScientists have extensively studied human and simpler neural networks (like those in C. elegans) to understand their functionality. However, a crucial question arises: how do we adapt our own neural networks to work effectively alongside novel AI s
 New Google Leak Reveals Subscription Changes For Gemini AIApr 27, 2025 am 11:08 AM
New Google Leak Reveals Subscription Changes For Gemini AIApr 27, 2025 am 11:08 AMGoogle's Gemini Advanced: New Subscription Tiers on the Horizon Currently, accessing Gemini Advanced requires a $19.99/month Google One AI Premium plan. However, an Android Authority report hints at upcoming changes. Code within the latest Google P
 How Data Analytics Acceleration Is Solving AI's Hidden BottleneckApr 27, 2025 am 11:07 AM
How Data Analytics Acceleration Is Solving AI's Hidden BottleneckApr 27, 2025 am 11:07 AMDespite the hype surrounding advanced AI capabilities, a significant challenge lurks within enterprise AI deployments: data processing bottlenecks. While CEOs celebrate AI advancements, engineers grapple with slow query times, overloaded pipelines, a
 MarkItDown MCP Can Convert Any Document into Markdowns!Apr 27, 2025 am 09:47 AM
MarkItDown MCP Can Convert Any Document into Markdowns!Apr 27, 2025 am 09:47 AMHandling documents is no longer just about opening files in your AI projects, it’s about transforming chaos into clarity. Docs such as PDFs, PowerPoints, and Word flood our workflows in every shape and size. Retrieving structured
 How to Use Google ADK for Building Agents? - Analytics VidhyaApr 27, 2025 am 09:42 AM
How to Use Google ADK for Building Agents? - Analytics VidhyaApr 27, 2025 am 09:42 AMHarness the power of Google's Agent Development Kit (ADK) to create intelligent agents with real-world capabilities! This tutorial guides you through building conversational agents using ADK, supporting various language models like Gemini and GPT. W
 Use of SLM over LLM for Effective Problem Solving - Analytics VidhyaApr 27, 2025 am 09:27 AM
Use of SLM over LLM for Effective Problem Solving - Analytics VidhyaApr 27, 2025 am 09:27 AMsummary: Small Language Model (SLM) is designed for efficiency. They are better than the Large Language Model (LLM) in resource-deficient, real-time and privacy-sensitive environments. Best for focus-based tasks, especially where domain specificity, controllability, and interpretability are more important than general knowledge or creativity. SLMs are not a replacement for LLMs, but they are ideal when precision, speed and cost-effectiveness are critical. Technology helps us achieve more with fewer resources. It has always been a promoter, not a driver. From the steam engine era to the Internet bubble era, the power of technology lies in the extent to which it helps us solve problems. Artificial intelligence (AI) and more recently generative AI are no exception
 How to Use Google Gemini Models for Computer Vision Tasks? - Analytics VidhyaApr 27, 2025 am 09:26 AM
How to Use Google Gemini Models for Computer Vision Tasks? - Analytics VidhyaApr 27, 2025 am 09:26 AMHarness the Power of Google Gemini for Computer Vision: A Comprehensive Guide Google Gemini, a leading AI chatbot, extends its capabilities beyond conversation to encompass powerful computer vision functionalities. This guide details how to utilize
 Gemini 2.0 Flash vs o4-mini: Can Google Do Better Than OpenAI?Apr 27, 2025 am 09:20 AM
Gemini 2.0 Flash vs o4-mini: Can Google Do Better Than OpenAI?Apr 27, 2025 am 09:20 AMThe AI landscape of 2025 is electrifying with the arrival of Google's Gemini 2.0 Flash and OpenAI's o4-mini. These cutting-edge models, launched weeks apart, boast comparable advanced features and impressive benchmark scores. This in-depth compariso


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

WebStorm Mac version
Useful JavaScript development tools

SublimeText3 Chinese version
Chinese version, very easy to use

